 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Individual and Collective Objectives in Multi-Agent Cooperation
Paper and Code
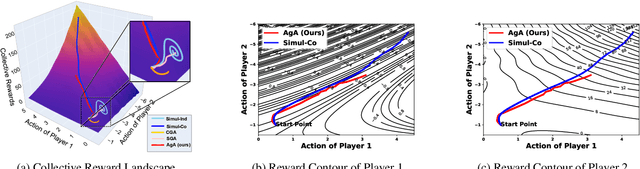
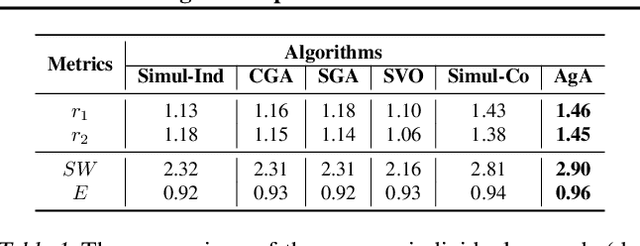
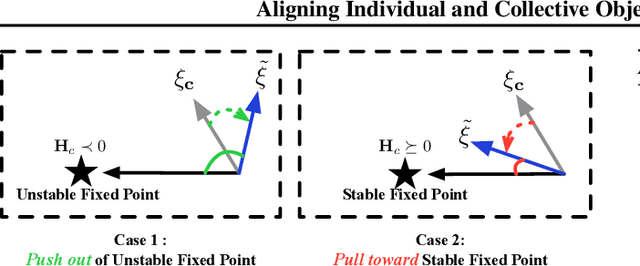
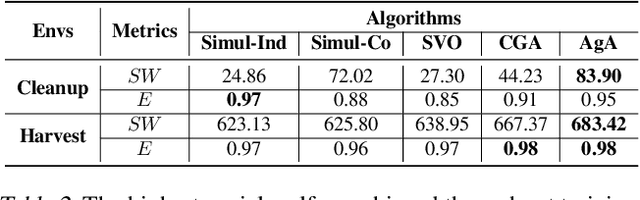
In the field of multi-agent learning, the challenge of mixed-motive cooperation is pronounced, given the inherent contradictions between individual and collective goals. Current research in this domain primarily focuses on incorporating domain knowledge into rewards or introducing additional mechanisms to foster cooperation. However, many of these methods suffer from the drawbacks of manual design costs and the lack of a theoretical grounding convergence procedure to the solution. To address this gap, we approach the mixed-motive game by modeling it as a differentiable game to study learning dynamics. We introduce a novel optimization method named Altruistic Gradient Adjustment (AgA) that employs gradient adjustments to novelly align individual and collective objectives. Furthermore, we provide theoretical proof that the selection of an appropriate alignment weight in AgA can accelerate convergence towards the desired solutions while effectively avoiding the undesired ones. The visualization of learning dynamics effectively demonstrates that AgA successfully achieves alignment between individual and collective objectives. Additionally, through evaluations conducted on established mixed-motive benchmarks such as the public good game, Cleanup, Harvest, and our modified mixed-motive SMAC environment, we validate AgA's capability to facilitate altruistic and fair collaboration.