 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTrace: Holistic Trajectory-Level Evaluation of LLM Tool Calling for Long-Horizon Financial Tasks
Apr 11, 2026Recent studies demonstrate that tool-calling capability enables large language models (LLMs) to interact with external environments for long-horizon financial tasks. While existing benchmarks have begun evaluating financial tool calling, they focus on limited scenarios and rely on call-level metrics that fail to capture trajectory-level reasoning quality. To address this gap, we introduce FinTrace, a benchmark comprising 800 expert-annotated trajectories spanning 34 real-world financial task categories across multiple difficulty levels. FinTrace employs a rubric-based evaluation protocol with nine metrics organized along four axes -- action correctness, execution efficiency, process quality, and output quality -- enabling fine-grained assessment of LLM tool-calling behavior. Our evaluation of 13 LLMs reveals that while frontier models achieve strong tool selection, all models struggle with information utilization and final answer quality, exposing a critical gap between invoking the right tools and reasoning effectively over their outputs. To move beyond diagnosis, we construct FinTrace-Training, the first trajectory-level preference dataset for financial tool-calling, containing 8,196 curated trajectories with tool-augmented contexts and preference pairs. We fine-tune Qwen-3.5-9B using supervised fine-tuning followed by direct preference optimization (DPO) and show that training on FinTrace-Training consistently improves intermediate reasoning metrics, with DPO more effectively suppressing failure modes. However, end-to-end answer quality remains a bottleneck, indicating that trajectory-level improvements do not yet fully propagate to final output quality.
Truth Neurons
May 18, 2025Despite their remarkable success and deployment across diverse workflows, language models sometimes produce untruthful responses. Our limited understanding of how truthfulness is mechanistically encoded within these models jeopardizes their reliability and safety. In this paper, we propose a method for identifying representations of truthfulness at the neuron level. We show that language models contain truth neurons, which encode truthfulness in a subject-agnostic manner. Experiments conducted across models of varying scales validate the existence of truth neurons, confirming that the encoding of truthfulness at the neuron level is a property shared by many language models. The distribution patterns of truth neurons over layers align with prior findings on the geometry of truthfulness. Selectively suppressing the activations of truth neurons found through the TruthfulQA dataset degrades performance both on TruthfulQA and on other benchmarks, showing that the truthfulness mechanisms are not tied to a specific dataset. Our results offer novel insights into the mechanisms underlying truthfulness in language models and highlight potential directions toward improving their trustworthiness and reliability.
Replicating Human Social Perception in Generative AI: Evaluating the Valence-Dominance Model
Mar 05, 2025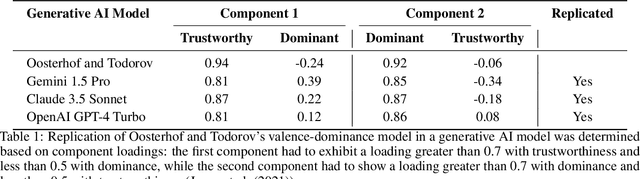
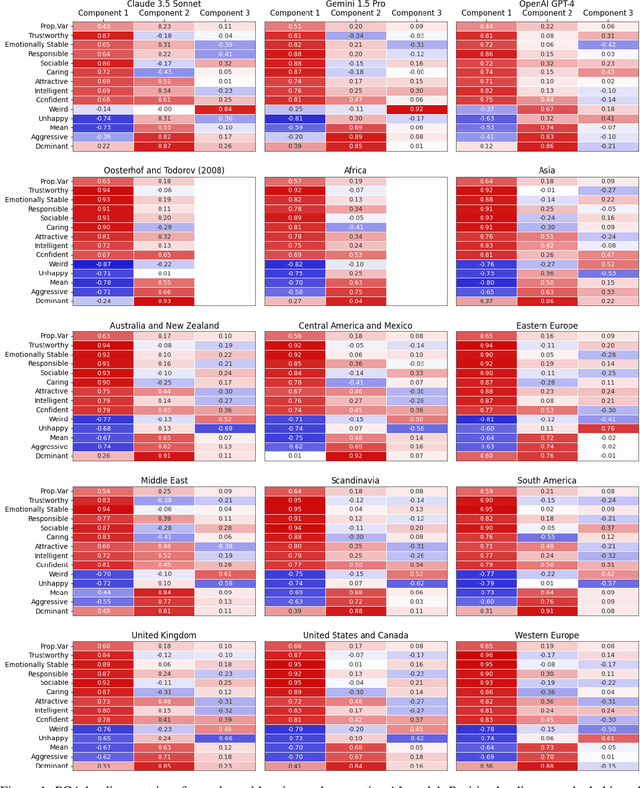
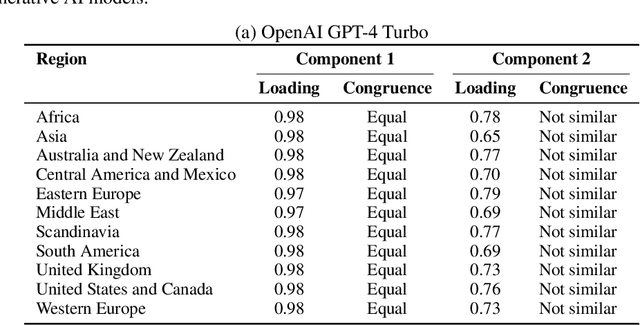
As artificial intelligence (AI) continues to advance--particularly in generative models--an open question is whether these systems can replicate foundational models of human social perception. A well-established framework in social cognition suggests that social judgments are organized along two primary dimensions: valence (e.g., trustworthiness, warmth) and dominance (e.g., power, assertiveness). This study examines whether multimodal generative AI systems can reproduce this valence-dominance structure when evaluating facial images and how their representations align with those observed across world regions. Through principal component analysis (PCA), we found that the extracted dimensions closely mirrored the theoretical structure of valence and dominance, with trait loadings aligning with established definitions. However, many world regions and generative AI models also exhibited a third component, the nature and significance of which warrant further investigation. These findings demonstrate that multimodal generative AI systems can replicate key aspects of human social perception, raising important questions about their implications for AI-driven decision-making and human-AI interactions.
INVESTORBENCH: A Benchmark for Financial Decision-Making Tasks with LLM-based Agent
Dec 24, 2024



Recent advancements have underscored the potential of large language model (LLM)-based agents in financial decision-making. Despite this progress, the field currently encounters two main challenges: (1) the lack of a comprehensive LLM agent framework adaptable to a variety of financial tasks, and (2) the absence of standardized benchmarks and consistent datasets for assessing agent performance. To tackle these issues, we introduce \textsc{InvestorBench}, the first benchmark specifically designed for evaluating LLM-based agents in diverse financial decision-making contexts. InvestorBench enhances the versatility of LLM-enabled agents by providing a comprehensive suite of tasks applicable to different financial products, including single equities like stocks, cryptocurrencies and exchange-traded funds (ETFs). Additionally, we assess the reasoning and decision-making capabilities of our agent framework using thirteen different LLMs as backbone models, across various market environments and tasks. Furthermore, we have curated a diverse collection of open-source, multi-modal datasets and developed a comprehensive suite of environments for financial decision-making. This establishes a highly accessible platform for evaluating financial agents' performance across various scenarios.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
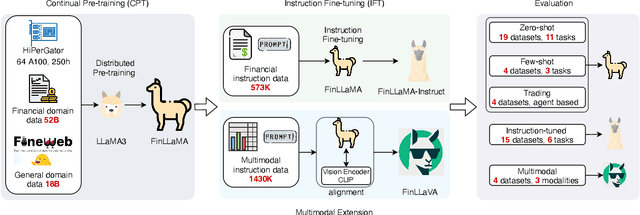
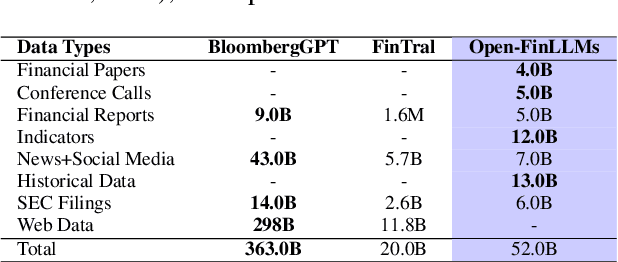
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
Jul 10, 2024


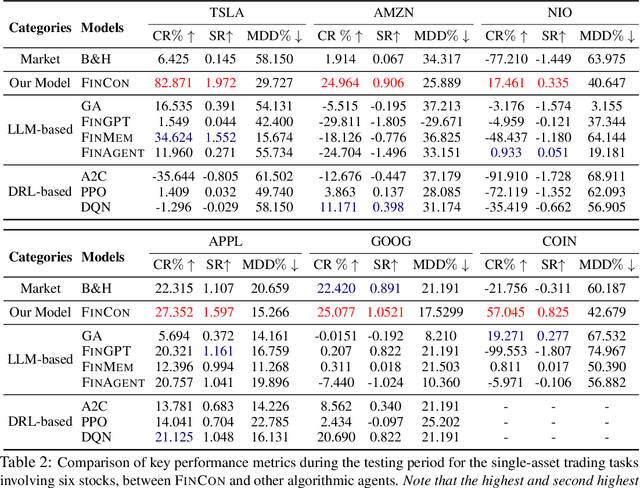
Large language models (LLMs) have demonstrated notable potential in conducting complex tasks and are increasingly utilized in various financial applications. However, high-quality sequential financial investment decision-making remains challenging. These tasks require multiple interactions with a volatile environment for every decision, demanding sufficient intelligence to maximize returns and manage risks. Although LLMs have been used to develop agent systems that surpass human teams and yield impressive investment returns, opportunities to enhance multi-sourced information synthesis and optimize decision-making outcomes through timely experience refinement remain unexplored. Here, we introduce the FinCon, an LLM-based multi-agent framework with CONceptual verbal reinforcement tailored for diverse FINancial tasks. Inspired by effective real-world investment firm organizational structures, FinCon utilizes a manager-analyst communication hierarchy. This structure allows for synchronized cross-functional agent collaboration towards unified goals through natural language interactions and equips each agent with greater memory capacity than humans. Additionally, a risk-control component in FinCon enhances decision quality by episodically initiating a self-critiquing mechanism to update systematic investment beliefs. The conceptualized beliefs serve as verbal reinforcement for the future agent's behavior and can be selectively propagated to the appropriate node that requires knowledge updates. This feature significantly improves performance while reducing unnecessary peer-to-peer communication costs. Moreover, FinCon demonstrates strong generalization capabilities in various financial tasks, including single stock trading and portfolio management.
Evaluating Large Language Models on the GMAT: Implications for the Future of Business Education
Jan 02, 2024The rapid evolution of artificial intelligence (AI), especially in the domain of Large Language Models (LLMs) and generative AI, has opened new avenues for application across various fields, yet its role in business education remains underexplored. This study introduces the first benchmark to assess the performance of seven major LLMs, OpenAI's models (GPT-3.5 Turbo, GPT-4, and GPT-4 Turbo), Google's models (PaLM 2, Gemini 1.0 Pro), and Anthropic's models (Claude 2 and Claude 2.1), on the GMAT, which is a key exam in the admission process for graduate business programs. Our analysis shows that most LLMs outperform human candidates, with GPT-4 Turbo not only outperforming the other models but also surpassing the average scores of graduate students at top business schools. Through a case study, this research examines GPT-4 Turbo's ability to explain answers, evaluate responses, identify errors, tailor instructions, and generate alternative scenarios. The latest LLM versions, GPT-4 Turbo, Claude 2.1, and Gemini 1.0 Pro, show marked improvements in reasoning tasks compared to their predecessors, underscoring their potential for complex problem-solving. While AI's promise in education, assessment, and tutoring is clear, challenges remain. Our study not only sheds light on LLMs' academic potential but also emphasizes the need for careful development and application of AI in education. As AI technology advances, it is imperative to establish frameworks and protocols for AI interaction, verify the accuracy of AI-generated content, ensure worldwide access for diverse learners, and create an educational environment where AI supports human expertise. This research sets the stage for further exploration into the responsible use of AI to enrich educational experiences and improve exam preparation and assessment methods.
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023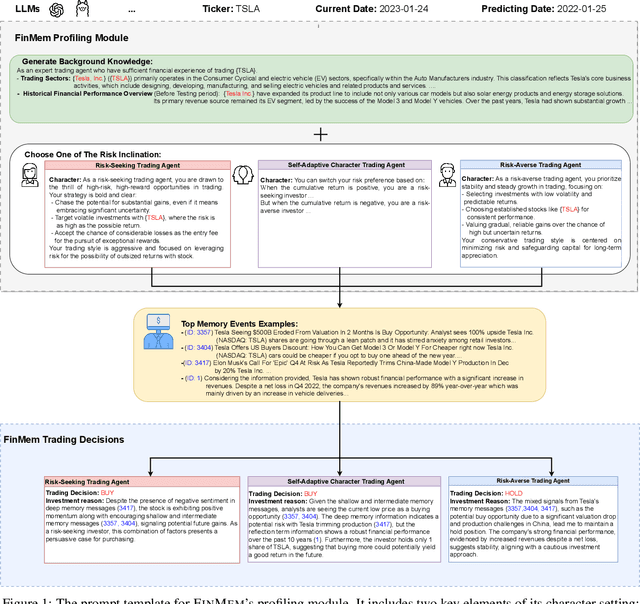
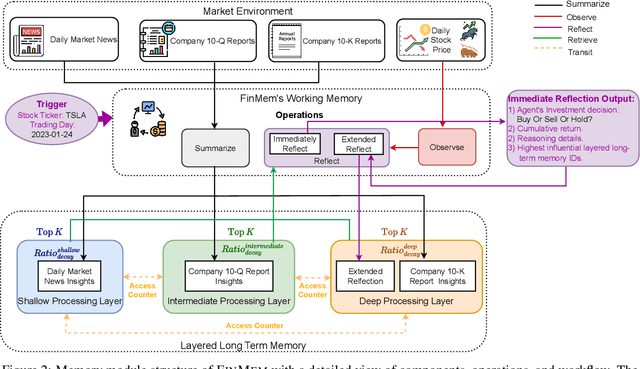


Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Harnessing Collective Intelligence Under a Lack of Cultural Consensus
Sep 19, 2023



Harnessing collective intelligence to drive effective decision-making and collaboration benefits from the ability to detect and characterize heterogeneity in consensus beliefs. This is particularly true in domains such as technology acceptance or leadership perception, where a consensus defines an intersubjective truth, leading to the possibility of multiple "ground truths" when subsets of respondents sustain mutually incompatible consensuses. Cultural Consensus Theory (CCT) provides a statistical framework for detecting and characterizing these divergent consensus beliefs. However, it is unworkable in modern applications because it lacks the ability to generalize across even highly similar beliefs, is ineffective with sparse data, and can leverage neither external knowledge bases nor learned machine representations. Here, we overcome these limitations through Infinite Deep Latent Construct Cultural Consensus Theory (iDLC-CCT), a nonparametric Bayesian model that extends CCT with a latent construct that maps between pretrained deep neural network embeddings of entities and the consensus beliefs regarding those entities among one or more subsets of respondents. We validate the method across domains including perceptions of risk sources, food healthiness, leadership, first impressions, and humor. We find that iDLC-CCT better predicts the degree of consensus, generalizes well to out-of-sample entities, and is effective even with sparse data. To improve scalability, we introduce an efficient hard-clustering variant of the iDLC-CCT using an algorithm derived from a small-variance asymptotic analysis of the model. The iDLC-CCT, therefore, provides a workable computational foundation for harnessing collective intelligence under a lack of cultural consensus and may potentially form the basis of consensus-aware information technologies.
Actively learning a Bayesian matrix fusion model with deep side information
Jun 08, 2023


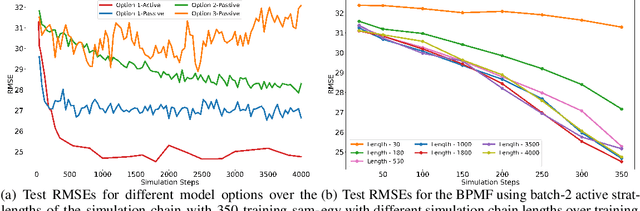
High-dimensional deep neural network representations of images and concepts can be aligned to predict human annotations of diverse stimuli. However, such alignment requires the costly collection of behavioral responses, such that, in practice, the deep-feature spaces are only ever sparsely sampled. Here, we propose an active learning approach to adaptively sampling experimental stimuli to efficiently learn a Bayesian matrix factorization model with deep side information. We observe a significant efficiency gain over a passive baseline. Furthermore, with a sequential batched sampling strategy, the algorithm is applicable not only to small datasets collected from traditional laboratory experiments but also to settings where large-scale crowdsourced data collection is needed to accurately align the high-dimensional deep feature representations derived from pre-trained networks.