 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowHFT: Imitation Learning via Flow Matching Policy for Optimal High-Frequency Trading under Diverse Market Conditions
May 16, 2025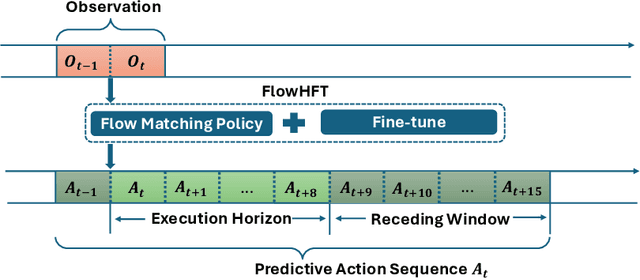
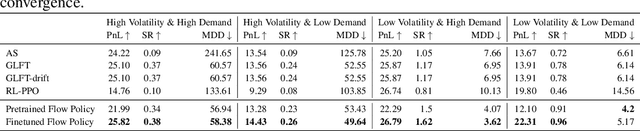
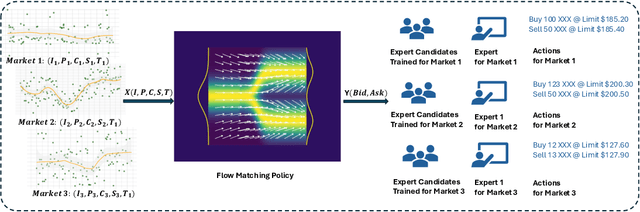

High-frequency trading (HFT) is an investing strategy that continuously monitors market states and places bid and ask orders at millisecond speeds. Traditional HFT approaches fit models with historical data and assume that future market states follow similar patterns. This limits the effectiveness of any single model to the specific conditions it was trained for. Additionally, these models achieve optimal solutions only under specific market conditions, such as assumptions about stock price's stochastic process, stable order flow, and the absence of sudden volatility. Real-world markets, however, are dynamic, diverse, and frequently volatile. To address these challenges, we propose the FlowHFT, a novel imitation learning framework based on flow matching policy. FlowHFT simultaneously learns strategies from numerous expert models, each proficient in particular market scenarios. As a result, our framework can adaptively adjust investment decisions according to the prevailing market state. Furthermore, FlowHFT incorporates a grid-search fine-tuning mechanism. This allows it to refine strategies and achieve superior performance even in complex or extreme market scenarios where expert strategies may be suboptimal. We test FlowHFT in multiple market environments. We first show that flow matching policy is applicable in stochastic market environments, thus enabling FlowHFT to learn trading strategies under different market conditions. Notably, our single framework consistently achieves performance superior to the best expert for each market condition.
FlowHFT: Flow Policy Induced Optimal High-Frequency Trading under Diverse Market Conditions
May 09, 2025High-frequency trading (HFT) is an investing strategy that continuously monitors market states and places bid and ask orders at millisecond speeds. Traditional HFT approaches fit models with historical data and assume that future market states follow similar patterns. This limits the effectiveness of any single model to the specific conditions it was trained for. Additionally, these models achieve optimal solutions only under specific market conditions, such as assumptions about stock price's stochastic process, stable order flow, and the absence of sudden volatility. Real-world markets, however, are dynamic, diverse, and frequently volatile. To address these challenges, we propose the FlowHFT, a novel imitation learning framework based on flow matching policy. FlowHFT simultaneously learns strategies from numerous expert models, each proficient in particular market scenarios. As a result, our framework can adaptively adjust investment decisions according to the prevailing market state. Furthermore, FlowHFT incorporates a grid-search fine-tuning mechanism. This allows it to refine strategies and achieve superior performance even in complex or extreme market scenarios where expert strategies may be suboptimal. We test FlowHFT in multiple market environments. We first show that flow matching policy is applicable in stochastic market environments, thus enabling FlowHFT to learn trading strategies under different market conditions. Notably, our single framework consistently achieves performance superior to the best expert for each market condition.
FinLoRA: Finetuning Quantized Financial Large Language Models Using Low-Rank Adaptation
Dec 16, 2024



Finetuned large language models (LLMs) have shown remarkable performance in financial tasks, such as sentiment analysis and information retrieval. Due to privacy concerns, finetuning and deploying Financial LLMs (FinLLMs) locally are crucial for institutions. However, finetuning FinLLMs poses challenges including GPU memory constraints and long input sequences. In this paper, we employ quantized low-rank adaptation (QLoRA) to finetune FinLLMs, which leverage low-rank matrix decomposition and quantization techniques to significantly reduce computational requirements while maintaining high model performance. We also employ data and pipeline parallelism to enable local finetuning using cost-effective, widely accessible GPUs. Experiments on financial datasets demonstrate that our method achieves substantial improvements in accuracy, GPU memory usage, and time efficiency, underscoring the potential of lowrank methods for scalable and resource-efficient LLM finetuning.
Financial Aspect-Based Sentiment Analysis using Deep Representations
Aug 23, 2018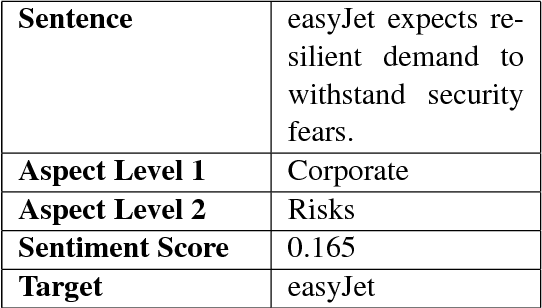
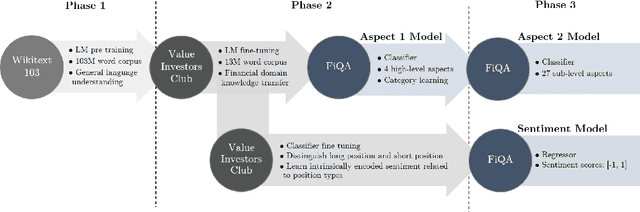
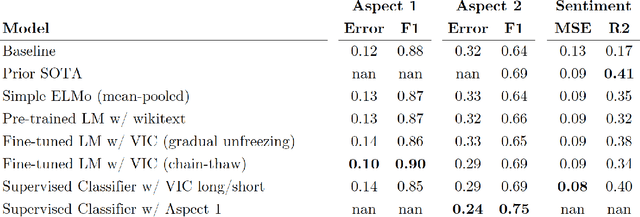
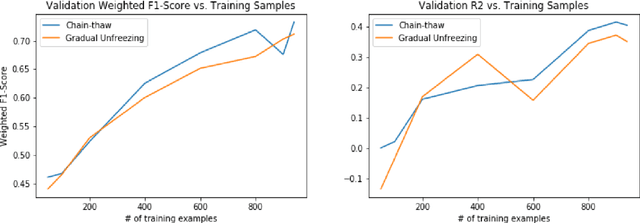
The topic of aspect-based sentiment analysis (ABSA) has been explored for a variety of industries, but it still remains much unexplored in finance. The recent release of data for an open challenge (FiQA) from the companion proceedings of WWW '18 has provided valuable finance-specific annotations. FiQA contains high quality labels, but it still lacks data quantity to apply traditional ABSA deep learning architecture. In this paper, we employ high-level semantic representations and methods of inductive transfer learning for NLP. We experiment with extensions of recently developed domain adaptation methods and target task fine-tuning that significantly improve performance on a small dataset. Our results show an 8.7% improvement in the F1 score for classification and an 11% improvement over the MSE for regression on current state-of-the-art results.