 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Method to Incorporate Spatial Information into Loss Functions for GAN-based Super-resolution Models
Paper and Code
Mar 15, 2024

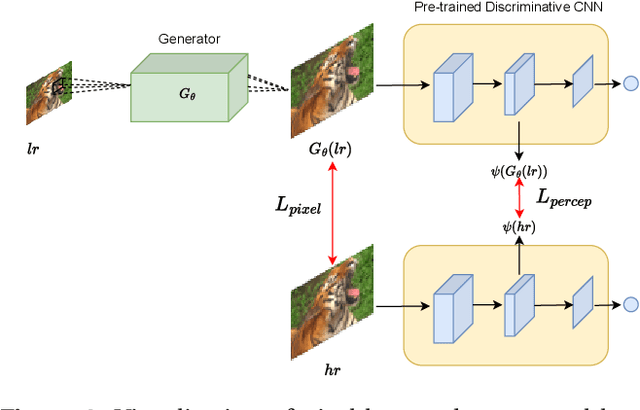
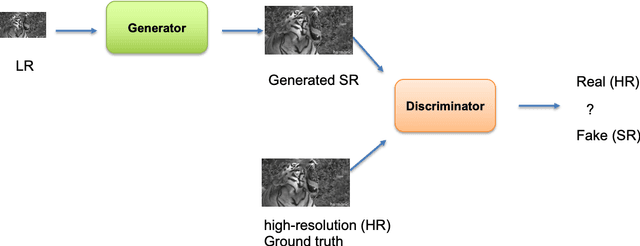
Generative Adversarial Networks (GANs) have shown great performance on super-resolution problems since they can generate more visually realistic images and video frames. However, these models often introduce side effects into the outputs, such as unexpected artifacts and noises. To reduce these artifacts and enhance the perceptual quality of the results, in this paper, we propose a general method that can be effectively used in most GAN-based super-resolution (SR) models by introducing essential spatial information into the training process. We extract spatial information from the input data and incorporate it into the training loss, making the corresponding loss a spatially adaptive (SA) one. After that, we utilize it to guide the training process. We will show that the proposed approach is independent of the methods used to extract the spatial information and independent of the SR tasks and models. This method consistently guides the training process towards generating visually pleasing SR images and video frames, substantially mitigating artifacts and noise, ultimately leading to enhanced perceptual quality.