 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust Cascade Model for Multiple Degradation Single Image Super-Resolution
Nov 16, 2020
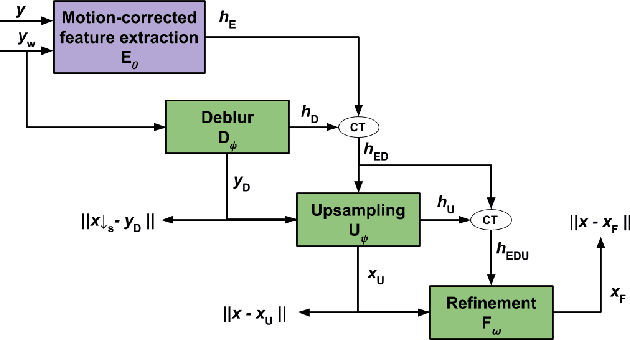

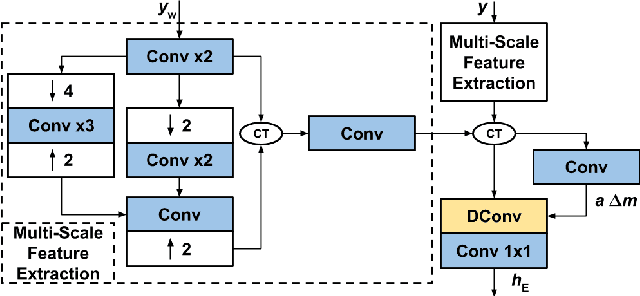
Single Image Super-Resolution (SISR) is one of the low-level computer vision problems that has received increased attention in the last few years. Current approaches are primarily based on harnessing the power of deep learning models and optimization techniques to reverse the degradation model. Owing to its hardness, isotropic blurring or Gaussians with small anisotropic deformations have been mainly considered. Here, we widen this scenario by including large non-Gaussian blurs that arise in real camera movements. Our approach leverages the degradation model and proposes a new formulation of the Convolutional Neural Network (CNN) cascade model, where each network sub-module is constrained to solve a specific degradation: deblurring or upsampling. A new densely connected CNN-architecture is proposed where the output of each sub-module is restricted using some external knowledge to focus it on its specific task. As far we know this use of domain-knowledge to module-level is a novelty in SISR. To fit the finest model, a final sub-module takes care of the residual errors propagated by the previous sub-modules. We check our model with three state of the art (SOTA) datasets in SISR and compare the results with the SOTA models. The results show that our model is the only one able to manage our wider set of deformations. Furthermore, our model overcomes all current SOTA methods for a standard set of deformations. In terms of computational load, our model also improves on the two closest competitors in terms of efficiency. Although the approach is non-blind and requires an estimation of the blur kernel, it shows robustness to blur kernel estimation errors, making it a good alternative to blind models.
Multimodal feature fusion for CNN-based gait recognition: an empirical comparison
Jun 19, 2018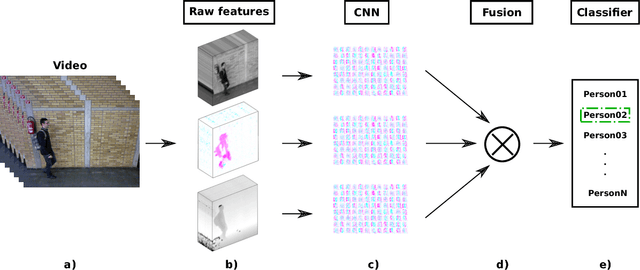
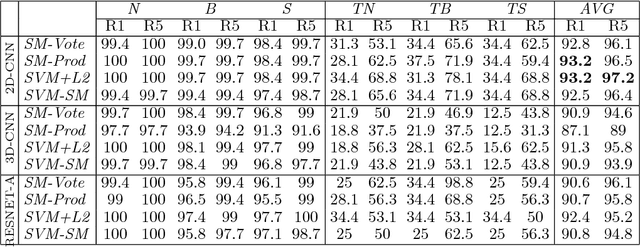
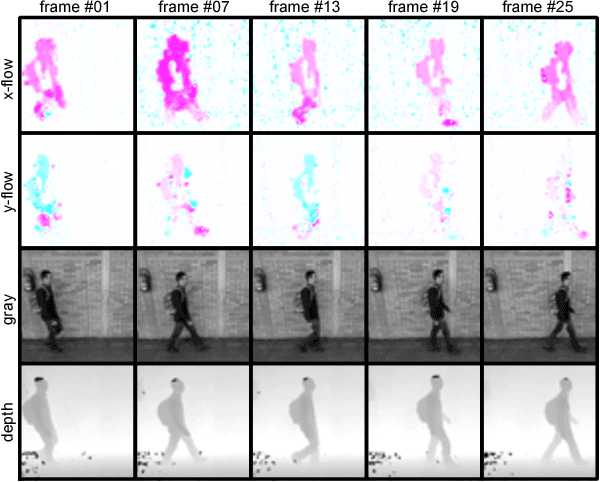
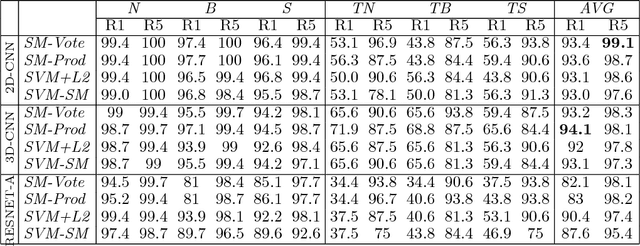
People identification in video based on the way they walk (i.e. gait) is a relevant task in computer vision using a non-invasive approach. Standard and current approaches typically derive gait signatures from sequences of binary energy maps of subjects extracted from images, but this process introduces a large amount of non-stationary noise, thus, conditioning their efficacy. In contrast, in this paper we focus on the raw pixels, or simple functions derived from them, letting advanced learning techniques to extract relevant features. Therefore, we present a comparative study of different Convolutional Neural Network (CNN) architectures on three low-level features (i.e. gray pixels, optical flow channels and depth maps) on two widely-adopted and challenging datasets: TUM-GAID and CASIA-B. In addition, we perform a comparative study between different early and late fusion methods used to combine the information obtained from each kind of low-level features. Our experimental results suggest that (i) the use of hand-crafted energy maps (e.g. GEI) is not necessary, since equal or better results can be achieved from the raw pixels; (ii) the combination of multiple modalities (i.e. gray pixels, optical flow and depth maps) from different CNNs allows to obtain state-of-the-art results on the gait task with an image resolution several times smaller than the previously reported results; and, (iii) the selection of the architecture is a critical point that can make the difference between state-of-the-art results or poor results.