 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADE: Forecasting for Anomaly Detection on ECG
Feb 11, 2025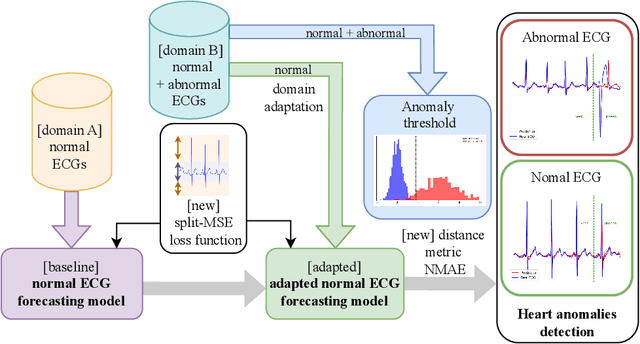
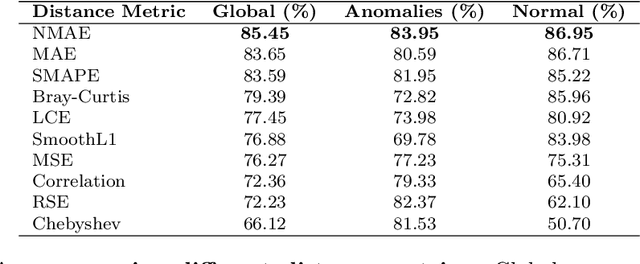
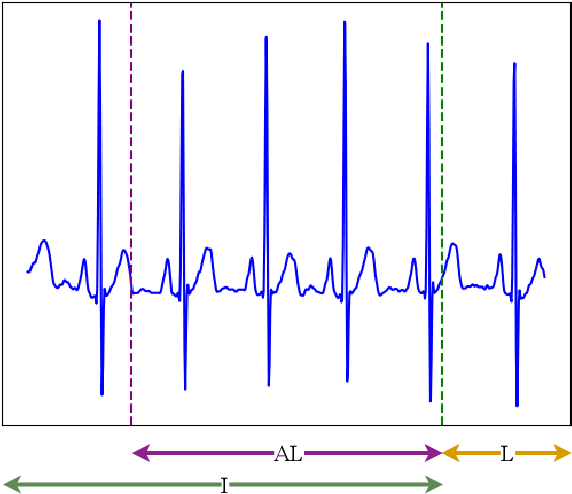

Cardiovascular diseases, a leading cause of noncommunicable disease-related deaths, require early and accurate detection to improve patient outcomes. Taking advantage of advances in machine learning and deep learning, multiple approaches have been proposed in the literature to address the challenge of detecting ECG anomalies. Typically, these methods are based on the manual interpretation of ECG signals, which is time consuming and depends on the expertise of healthcare professionals. The objective of this work is to propose a deep learning system, FADE, designed for normal ECG forecasting and anomaly detection, which reduces the need for extensive labeled datasets and manual interpretation. FADE has been trained in a self-supervised manner with a novel morphological inspired loss function. Unlike conventional models that learn from labeled anomalous ECG waveforms, our approach predicts the future of normal ECG signals, thus avoiding the need for extensive labeled datasets. Using a novel distance function to compare forecasted ECG signals with actual sensor data, our method effectively identifies cardiac anomalies. Additionally, this approach can be adapted to new contexts through domain adaptation techniques. To evaluate our proposal, we performed a set of experiments using two publicly available datasets: MIT-BIH NSR and MIT-BIH Arrythmia. The results demonstrate that our system achieves an average accuracy of 83.84% in anomaly detection, while correctly classifying normal ECG signals with an accuracy of 85.46%. Our proposed approach exhibited superior performance in the early detection of cardiac anomalies in ECG signals, surpassing previous methods that predominantly identify a limited range of anomalies. FADE effectively detects both abnormal heartbeats and arrhythmias, offering significant advantages in healthcare through cost reduction or processing of large-scale ECG data.
End-to-End Incremental Learning
Sep 03, 2018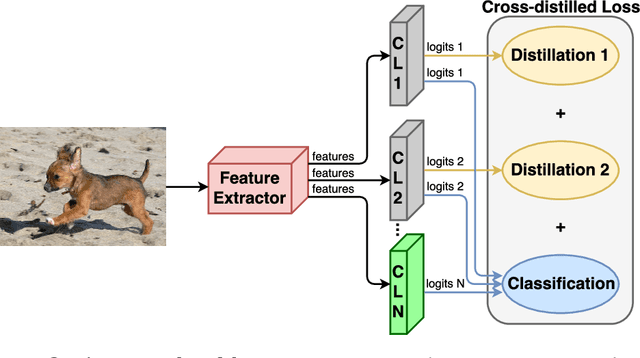

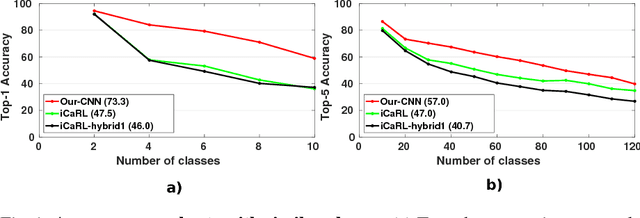
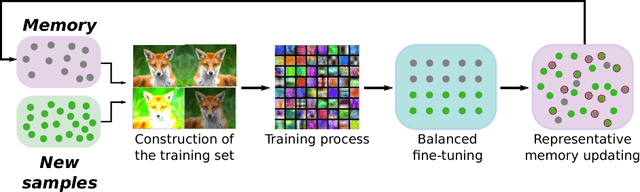
Although deep learning approaches have stood out in recent years due to their state-of-the-art results, they continue to suffer from catastrophic forgetting, a dramatic decrease in overall performance when training with new classes added incrementally. This is due to current neural network architectures requiring the entire dataset, consisting of all the samples from the old as well as the new classes, to update the model -a requirement that becomes easily unsustainable as the number of classes grows. We address this issue with our approach to learn deep neural networks incrementally, using new data and only a small exemplar set corresponding to samples from the old classes. This is based on a loss composed of a distillation measure to retain the knowledge acquired from the old classes, and a cross-entropy loss to learn the new classes. Our incremental training is achieved while keeping the entire framework end-to-end, i.e., learning the data representation and the classifier jointly, unlike recent methods with no such guarantees. We evaluate our method extensively on the CIFAR-100 and ImageNet (ILSVRC 2012) image classification datasets, and show state-of-the-art performance.
Energy-based Tuning of Convolutional Neural Networks on Multi-GPUs
Aug 01, 2018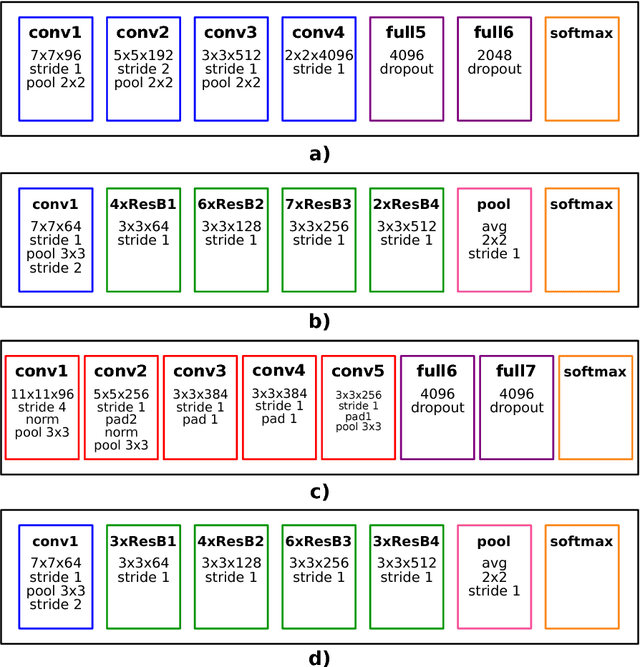

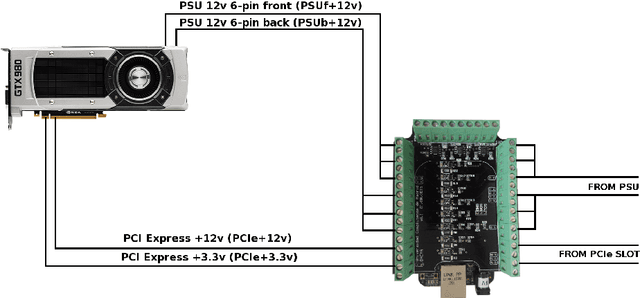
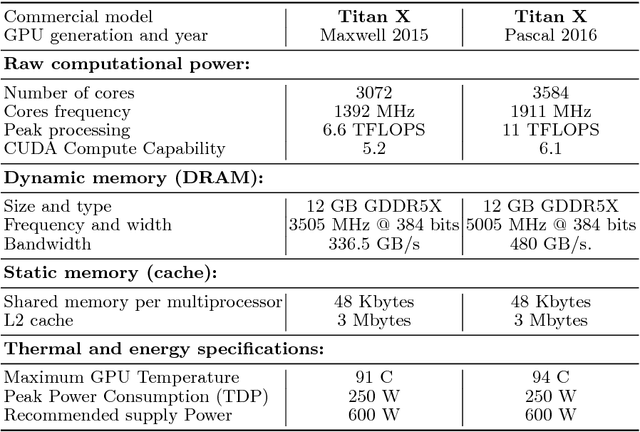
Deep Learning (DL) applications are gaining momentum in the realm of Artificial Intelligence, particularly after GPUs have demonstrated remarkable skills for accelerating their challenging computational requirements. Within this context, Convolutional Neural Network (CNN) models constitute a representative example of success on a wide set of complex applications, particularly on datasets where the target can be represented through a hierarchy of local features of increasing semantic complexity. In most of the real scenarios, the roadmap to improve results relies on CNN settings involving brute force computation, and researchers have lately proven Nvidia GPUs to be one of the best hardware counterparts for acceleration. Our work complements those findings with an energy study on critical parameters for the deployment of CNNs on flagship image and video applications: object recognition and people identification by gait, respectively. We evaluate energy consumption on four different networks based on the two most popular ones (ResNet/AlexNet): ResNet (167 layers), a 2D CNN (15 layers), a CaffeNet (25 layers) and a ResNetIm (94 layers) using batch sizes of 64, 128 and 256, and then correlate those with speed-up and accuracy to determine optimal settings. Experimental results on a multi-GPU server endowed with twin Maxwell and twin Pascal Titan X GPUs demonstrate that energy correlates with performance and that Pascal may have up to 40% gains versus Maxwell. Larger batch sizes extend performance gains and energy savings, but we have to keep an eye on accuracy, which sometimes shows a preference for small batches. We expect this work to provide a preliminary guidance for a wide set of CNN and DL applications in modern HPC times, where the GFLOPS/w ratio constitutes the primary goal.
Multimodal feature fusion for CNN-based gait recognition: an empirical comparison
Jun 19, 2018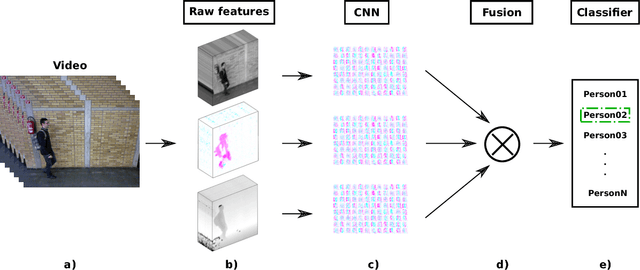
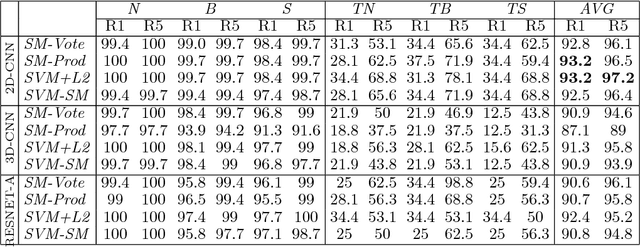
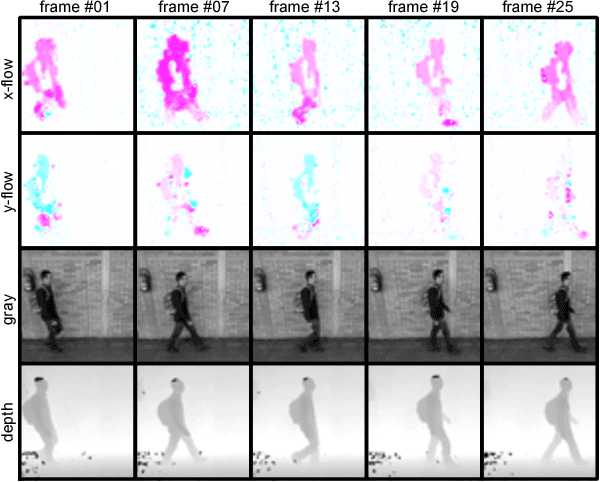
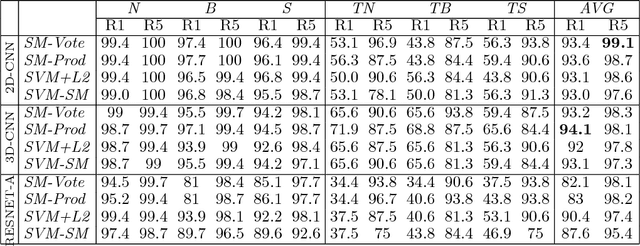
People identification in video based on the way they walk (i.e. gait) is a relevant task in computer vision using a non-invasive approach. Standard and current approaches typically derive gait signatures from sequences of binary energy maps of subjects extracted from images, but this process introduces a large amount of non-stationary noise, thus, conditioning their efficacy. In contrast, in this paper we focus on the raw pixels, or simple functions derived from them, letting advanced learning techniques to extract relevant features. Therefore, we present a comparative study of different Convolutional Neural Network (CNN) architectures on three low-level features (i.e. gray pixels, optical flow channels and depth maps) on two widely-adopted and challenging datasets: TUM-GAID and CASIA-B. In addition, we perform a comparative study between different early and late fusion methods used to combine the information obtained from each kind of low-level features. Our experimental results suggest that (i) the use of hand-crafted energy maps (e.g. GEI) is not necessary, since equal or better results can be achieved from the raw pixels; (ii) the combination of multiple modalities (i.e. gray pixels, optical flow and depth maps) from different CNNs allows to obtain state-of-the-art results on the gait task with an image resolution several times smaller than the previously reported results; and, (iii) the selection of the architecture is a critical point that can make the difference between state-of-the-art results or poor results.