 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bird Song Detector for improving bird identification through Deep Learning: a case study from Doñana
Mar 19, 2025


Passive Acoustic Monitoring with automatic recorders is essential for ecosystem conservation but generates vast unsupervised audio data, posing challenges for extracting meaningful information. Deep Learning techniques offer a promising solution. BirdNET, a widely used model for bird identification, has shown success in many study systems but is limited in some regions due to biases in its training data. A key challenge in bird species detection is that many recordings either lack target species or contain overlapping vocalizations. To overcome these problems, we developed a multi-stage pipeline for automatic bird vocalization identification in Do\~nana National Park (SW Spain), a region facing significant conservation threats. Our approach included a Bird Song Detector to isolate vocalizations and custom classifiers trained with BirdNET embeddings. We manually annotated 461 minutes of audio from three habitats across nine locations, yielding 3,749 annotations for 34 classes. Spectrograms facilitated the use of image processing techniques. Applying the Bird Song Detector before classification improved species identification, as all classification models performed better when analyzing only the segments where birds were detected. Specifically, the combination of the Bird Song Detector and fine-tuned BirdNET compared to the baseline without the Bird Song Detector. Our approach demonstrated the effectiveness of integrating a Bird Song Detector with fine-tuned classification models for bird identification at local soundscapes. These findings highlight the need to adapt general-purpose tools for specific ecological challenges, as demonstrated in Do\~nana. Automatically detecting bird species serves for tracking the health status of this threatened ecosystem, given the sensitivity of birds to environmental changes, and helps in the design of conservation measures for reducing biodiversity loss
DeepArUco++: Improved detection of square fiducial markers in challenging lighting conditions
Nov 08, 2024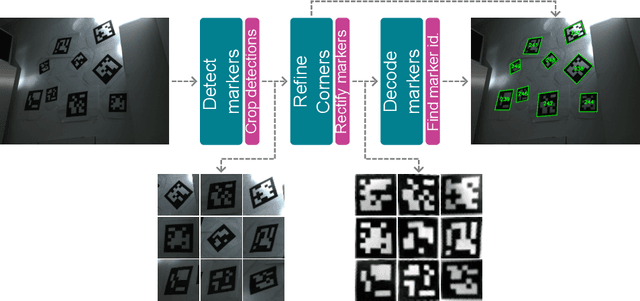
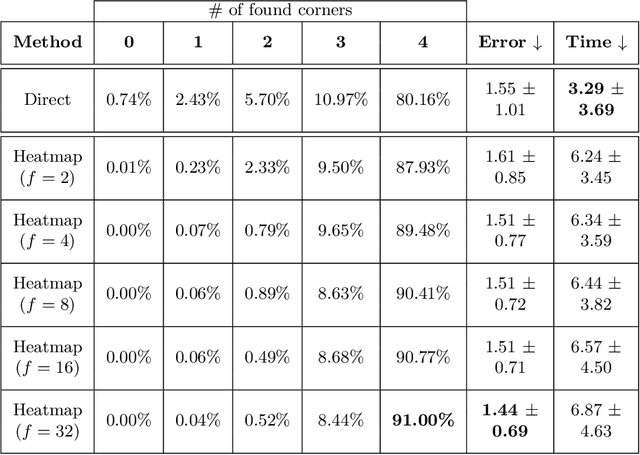

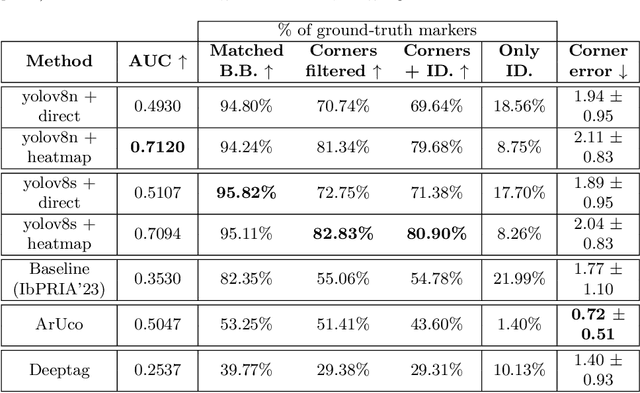
Fiducial markers are a computer vision tool used for object pose estimation and detection. These markers are highly useful in fields such as industry, medicine and logistics. However, optimal lighting conditions are not always available,and other factors such as blur or sensor noise can affect image quality. Classical computer vision techniques that precisely locate and decode fiducial markers often fail under difficult illumination conditions (e.g. extreme variations of lighting within the same frame). Hence, we propose DeepArUco++, a deep learning-based framework that leverages the robustness of Convolutional Neural Networks to perform marker detection and decoding in challenging lighting conditions. The framework is based on a pipeline using different Neural Network models at each step, namely marker detection, corner refinement and marker decoding. Additionally, we propose a simple method for generating synthetic data for training the different models that compose the proposed pipeline, and we present a second, real-life dataset of ArUco markers in challenging lighting conditions used to evaluate our system. The developed method outperforms other state-of-the-art methods in such tasks and remains competitive even when testing on the datasets used to develop those methods. Code available in GitHub: https://github.com/AVAuco/deeparuco/
RealHePoNet: a robust single-stage ConvNet for head pose estimation in the wild
Nov 03, 2020


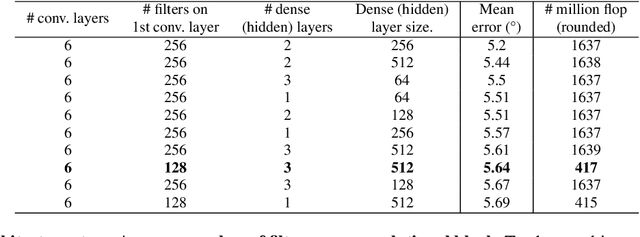
Human head pose estimation in images has applications in many fields such as human-computer interaction or video surveillance tasks. In this work, we address this problem, defined here as the estimation of both vertical (tilt/pitch) and horizontal (pan/yaw) angles, through the use of a single Convolutional Neural Network (ConvNet) model, trying to balance precision and inference speed in order to maximize its usability in real-world applications. Our model is trained over the combination of two datasets: 'Pointing'04' (aiming at covering a wide range of poses) and 'Annotated Facial Landmarks in the Wild' (in order to improve robustness of our model for its use on real-world images). Three different partitions of the combined dataset are defined and used for training, validation and testing purposes. As a result of this work, we have obtained a trained ConvNet model, coined RealHePoNet, that given a low-resolution grayscale input image, and without the need of using facial landmarks, is able to estimate with low error both tilt and pan angles (~4.4{\deg} average error on the test partition). Also, given its low inference time (~6 ms per head), we consider our model usable even when paired with medium-spec hardware (i.e. GTX 1060 GPU). * Code available at: https://github.com/rafabs97/headpose_final * Demo video at: https://www.youtube.com/watch?v=2UeuXh5DjAE
End-to-End Incremental Learning
Sep 03, 2018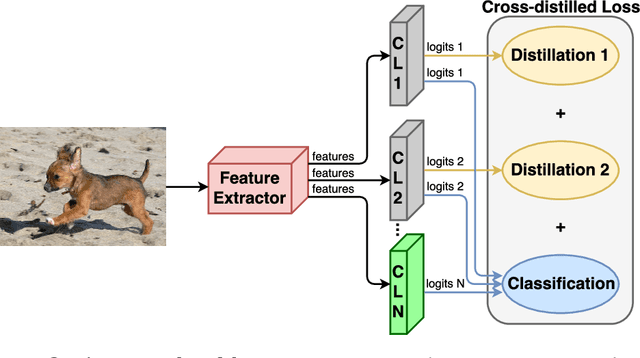

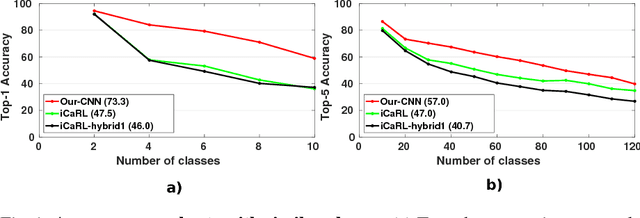
Although deep learning approaches have stood out in recent years due to their state-of-the-art results, they continue to suffer from catastrophic forgetting, a dramatic decrease in overall performance when training with new classes added incrementally. This is due to current neural network architectures requiring the entire dataset, consisting of all the samples from the old as well as the new classes, to update the model -a requirement that becomes easily unsustainable as the number of classes grows. We address this issue with our approach to learn deep neural networks incrementally, using new data and only a small exemplar set corresponding to samples from the old classes. This is based on a loss composed of a distillation measure to retain the knowledge acquired from the old classes, and a cross-entropy loss to learn the new classes. Our incremental training is achieved while keeping the entire framework end-to-end, i.e., learning the data representation and the classifier jointly, unlike recent methods with no such guarantees. We evaluate our method extensively on the CIFAR-100 and ImageNet (ILSVRC 2012) image classification datasets, and show state-of-the-art performance.
Energy-based Tuning of Convolutional Neural Networks on Multi-GPUs
Aug 01, 2018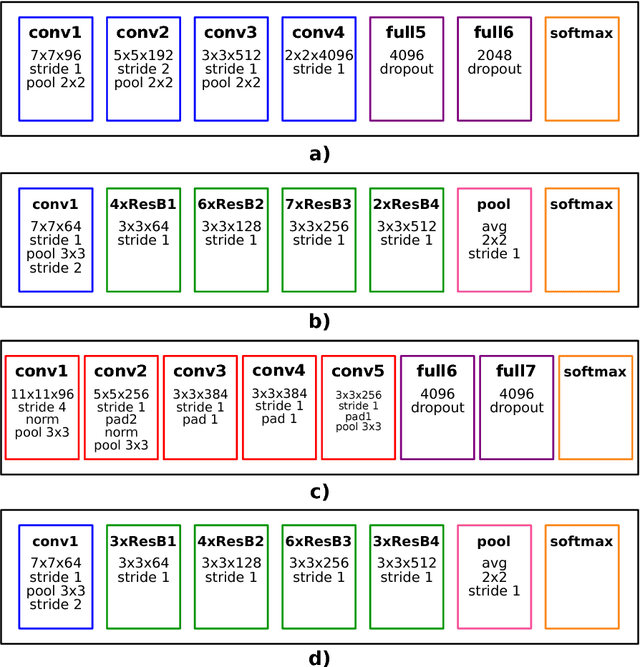

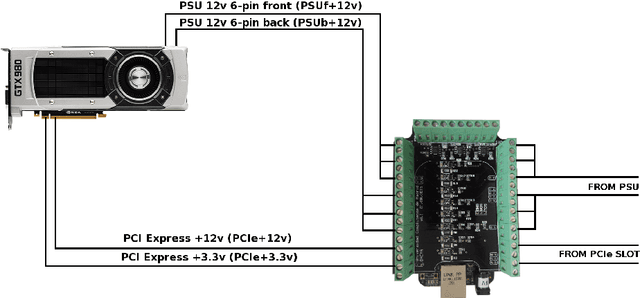
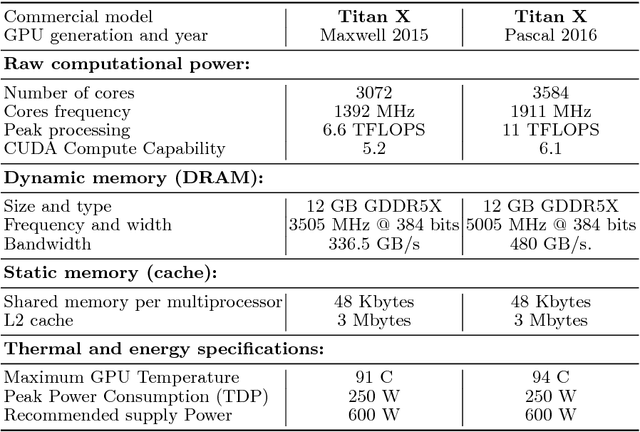
Deep Learning (DL) applications are gaining momentum in the realm of Artificial Intelligence, particularly after GPUs have demonstrated remarkable skills for accelerating their challenging computational requirements. Within this context, Convolutional Neural Network (CNN) models constitute a representative example of success on a wide set of complex applications, particularly on datasets where the target can be represented through a hierarchy of local features of increasing semantic complexity. In most of the real scenarios, the roadmap to improve results relies on CNN settings involving brute force computation, and researchers have lately proven Nvidia GPUs to be one of the best hardware counterparts for acceleration. Our work complements those findings with an energy study on critical parameters for the deployment of CNNs on flagship image and video applications: object recognition and people identification by gait, respectively. We evaluate energy consumption on four different networks based on the two most popular ones (ResNet/AlexNet): ResNet (167 layers), a 2D CNN (15 layers), a CaffeNet (25 layers) and a ResNetIm (94 layers) using batch sizes of 64, 128 and 256, and then correlate those with speed-up and accuracy to determine optimal settings. Experimental results on a multi-GPU server endowed with twin Maxwell and twin Pascal Titan X GPUs demonstrate that energy correlates with performance and that Pascal may have up to 40% gains versus Maxwell. Larger batch sizes extend performance gains and energy savings, but we have to keep an eye on accuracy, which sometimes shows a preference for small batches. We expect this work to provide a preliminary guidance for a wide set of CNN and DL applications in modern HPC times, where the GFLOPS/w ratio constitutes the primary goal.