 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepArUco++: Improved detection of square fiducial markers in challenging lighting conditions
Nov 08, 2024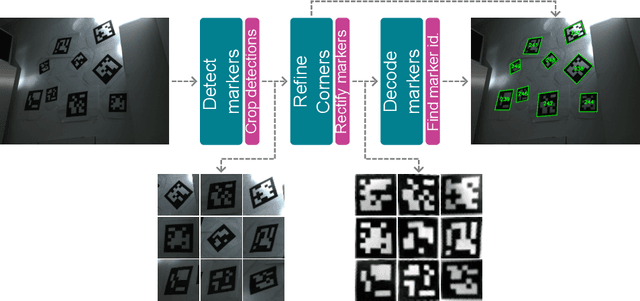
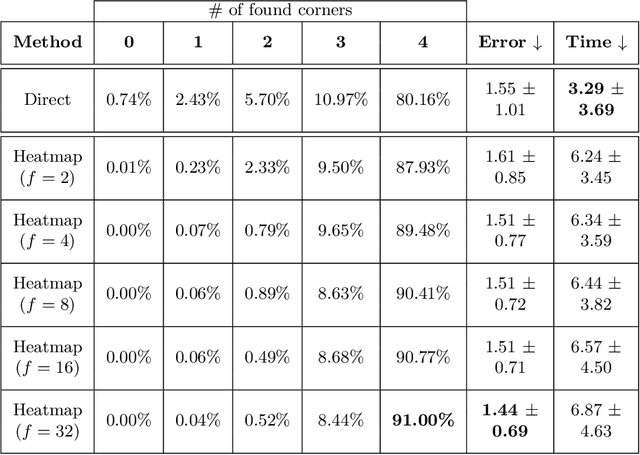

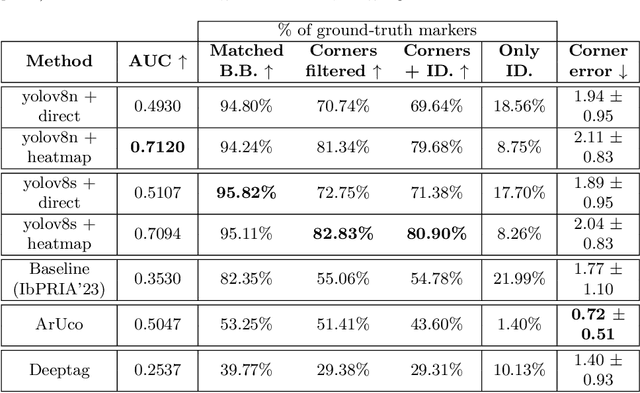
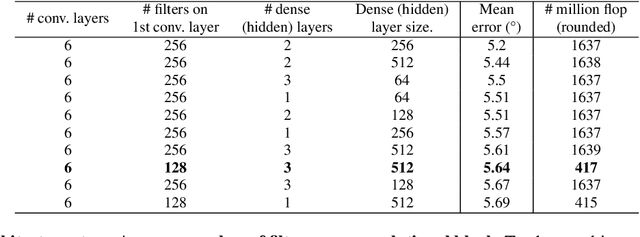
Fiducial markers are a computer vision tool used for object pose estimation and detection. These markers are highly useful in fields such as industry, medicine and logistics. However, optimal lighting conditions are not always available,and other factors such as blur or sensor noise can affect image quality. Classical computer vision techniques that precisely locate and decode fiducial markers often fail under difficult illumination conditions (e.g. extreme variations of lighting within the same frame). Hence, we propose DeepArUco++, a deep learning-based framework that leverages the robustness of Convolutional Neural Networks to perform marker detection and decoding in challenging lighting conditions. The framework is based on a pipeline using different Neural Network models at each step, namely marker detection, corner refinement and marker decoding. Additionally, we propose a simple method for generating synthetic data for training the different models that compose the proposed pipeline, and we present a second, real-life dataset of ArUco markers in challenging lighting conditions used to evaluate our system. The developed method outperforms other state-of-the-art methods in such tasks and remains competitive even when testing on the datasets used to develop those methods. Code available in GitHub: https://github.com/AVAuco/deeparuco/
RealHePoNet: a robust single-stage ConvNet for head pose estimation in the wild
Nov 03, 2020


Human head pose estimation in images has applications in many fields such as human-computer interaction or video surveillance tasks. In this work, we address this problem, defined here as the estimation of both vertical (tilt/pitch) and horizontal (pan/yaw) angles, through the use of a single Convolutional Neural Network (ConvNet) model, trying to balance precision and inference speed in order to maximize its usability in real-world applications. Our model is trained over the combination of two datasets: 'Pointing'04' (aiming at covering a wide range of poses) and 'Annotated Facial Landmarks in the Wild' (in order to improve robustness of our model for its use on real-world images). Three different partitions of the combined dataset are defined and used for training, validation and testing purposes. As a result of this work, we have obtained a trained ConvNet model, coined RealHePoNet, that given a low-resolution grayscale input image, and without the need of using facial landmarks, is able to estimate with low error both tilt and pan angles (~4.4{\deg} average error on the test partition). Also, given its low inference time (~6 ms per head), we consider our model usable even when paired with medium-spec hardware (i.e. GTX 1060 GPU). * Code available at: https://github.com/rafabs97/headpose_final * Demo video at: https://www.youtube.com/watch?v=2UeuXh5DjAE