 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepArUco++: Improved detection of square fiducial markers in challenging lighting conditions
Nov 08, 2024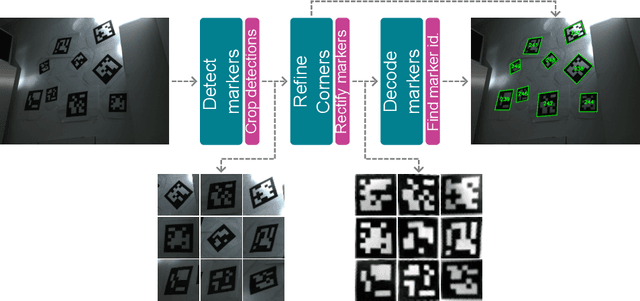
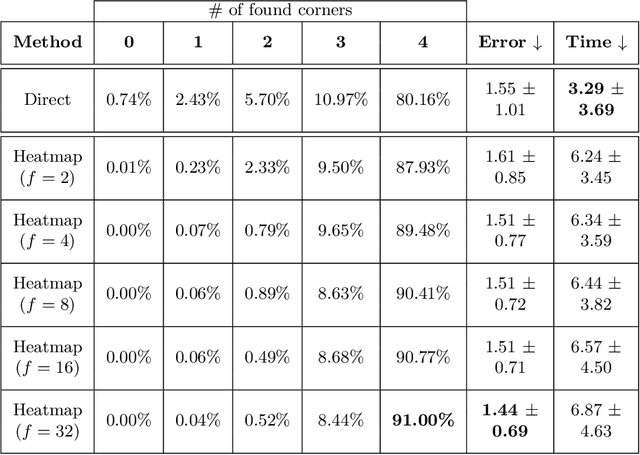

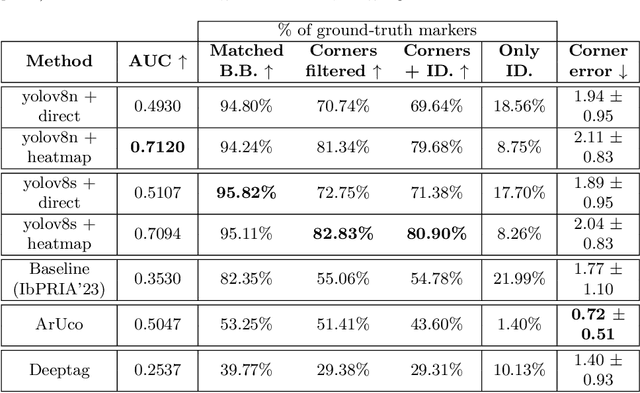
Fiducial markers are a computer vision tool used for object pose estimation and detection. These markers are highly useful in fields such as industry, medicine and logistics. However, optimal lighting conditions are not always available,and other factors such as blur or sensor noise can affect image quality. Classical computer vision techniques that precisely locate and decode fiducial markers often fail under difficult illumination conditions (e.g. extreme variations of lighting within the same frame). Hence, we propose DeepArUco++, a deep learning-based framework that leverages the robustness of Convolutional Neural Networks to perform marker detection and decoding in challenging lighting conditions. The framework is based on a pipeline using different Neural Network models at each step, namely marker detection, corner refinement and marker decoding. Additionally, we propose a simple method for generating synthetic data for training the different models that compose the proposed pipeline, and we present a second, real-life dataset of ArUco markers in challenging lighting conditions used to evaluate our system. The developed method outperforms other state-of-the-art methods in such tasks and remains competitive even when testing on the datasets used to develop those methods. Code available in GitHub: https://github.com/AVAuco/deeparuco/
3D Reconstruction and Alignment by Consumer RGB-D Sensors and Fiducial Planar Markers for Patient Positioning in Radiation Therapy
Mar 22, 2021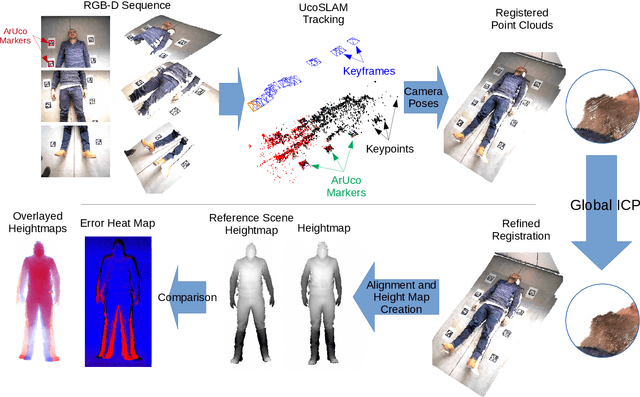

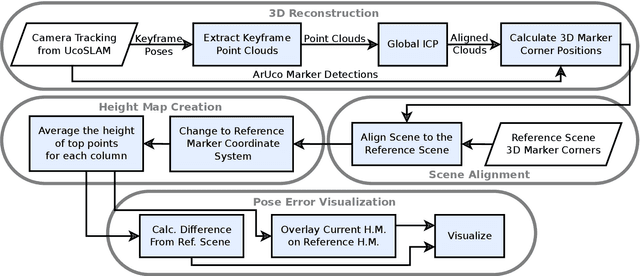

BACKGROUND AND OBJECTIVE: Patient positioning is a crucial step in radiation therapy, for which non-invasive methods have been developed based on surface reconstruction using optical 3D imaging. However, most solutions need expensive specialized hardware and a careful calibration procedure that must be repeated over time.This paper proposes a fast and cheap patient positioning method based on inexpensive consumer level RGB-D sensors. METHODS: The proposed method relies on a 3D reconstruction approach that fuses, in real-time, artificial and natural visual landmarks recorded from a hand-held RGB-D sensor. The video sequence is transformed into a set of keyframes with known poses, that are later refined to obtain a realistic 3D reconstruction of the patient. The use of artificial landmarks allows our method to automatically align the reconstruction to a reference one, without the need of calibrating the system with respect to the linear accelerator coordinate system. RESULTS:The experiments conducted show that our method obtains a median of 1 cm in translational error, and 1 degree of rotational error with respect to reference pose. Additionally, the proposed method shows as visual output overlayed poses (from the reference and the current scene) and an error map that can be used to correct the patient's current pose to match the reference pose. CONCLUSIONS: A novel approach to obtain 3D body reconstructions for patient positioning without requiring expensive hardware or dedicated graphic cards is proposed. The method can be used to align in real time the patient's current pose to a preview pose, which is a relevant step in radiation therapy.
Detection of Binary Square Fiducial Markers Using an Event Camera
Jan 19, 2021
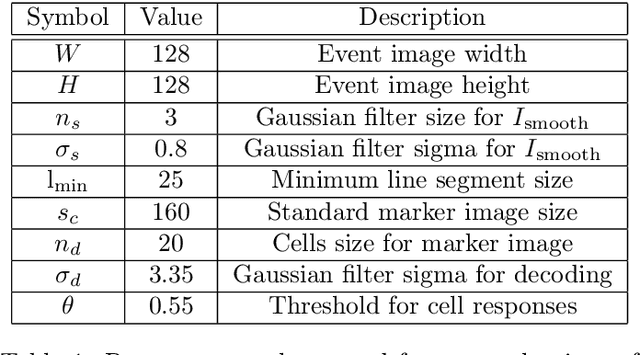

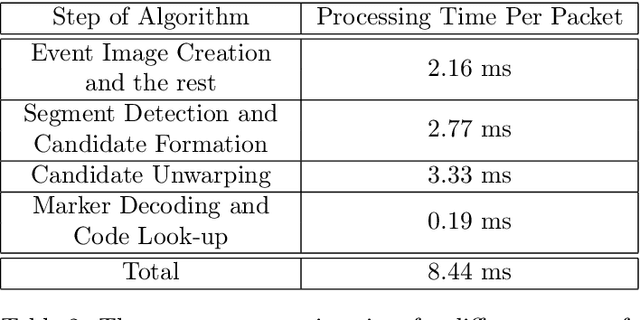
Event cameras are a new type of image sensors that output changes in light intensity (events) instead of absolute intensity values. They have a very high temporal resolution and a high dynamic range. In this paper, we propose a method to detect and decode binary square markers using an event camera. We detect the edges of the markers by detecting line segments in an image created from events in the current packet. The line segments are combined to form marker candidates. The bit value of marker cells is decoded using the events on their borders. To the best of our knowledge, no other approach exists for detecting square binary markers directly from an event camera. Experimental results show that the performance of our proposal is much superior to the one from the RGB ArUco marker detector. Additionally, the proposed method can run on a single CPU thread in real-time.
UcoSLAM: Simultaneous Localization and Mapping by Fusion of KeyPoints and Squared Planar Markers
Feb 11, 2019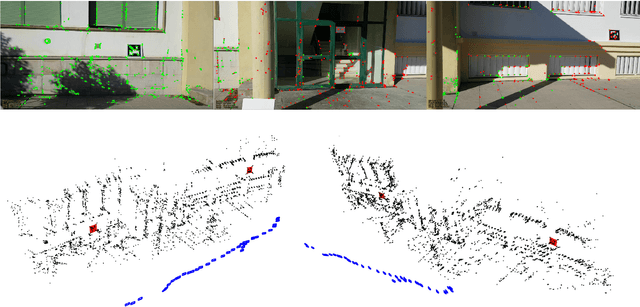

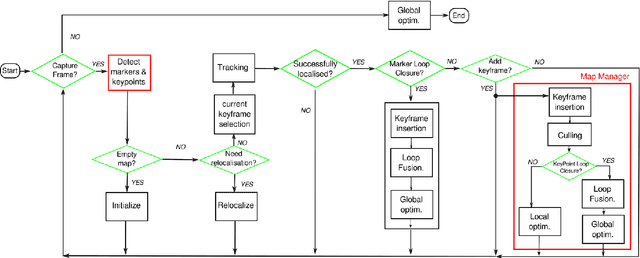
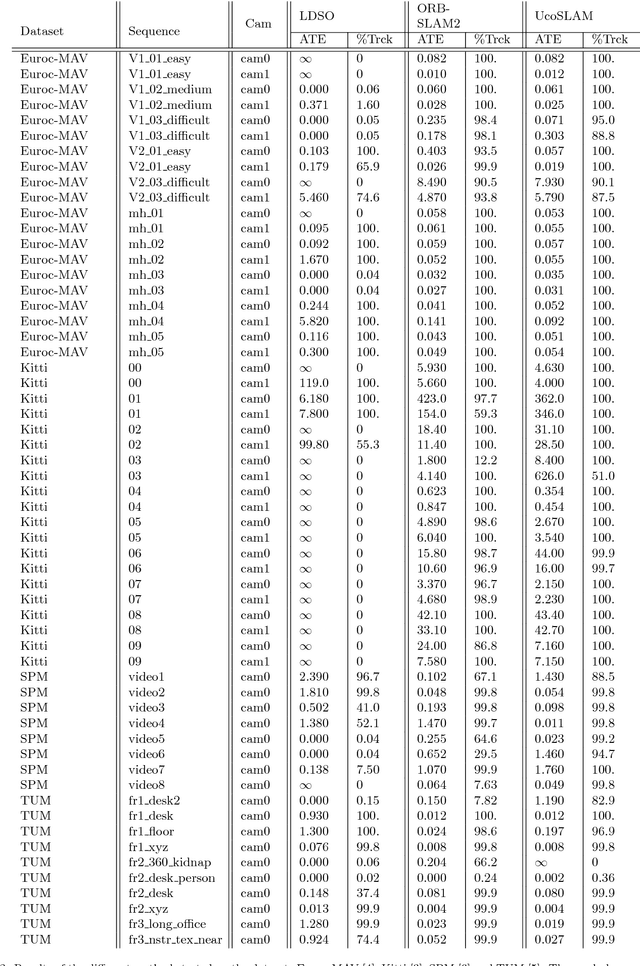
This paper proposes a novel approach for Simultaneous Localization and Mapping by fusing natural and artificial landmarks. Most of the SLAM approaches use natural landmarks (such as keypoints). However, they are unstable over time, repetitive in many cases or insufficient for a robust tracking (e.g. in indoor buildings). On the other hand, other approaches have employed artificial landmarks (such as squared fiducial markers) placed in the environment to help tracking and relocalization. We propose a method that integrates both approaches in order to achieve long-term robust tracking in many scenarios. Our method has been compared to the start-of-the-art methods ORB-SLAM2 and LDSO in the public dataset Kitti, Euroc-MAV, TUM and SPM, obtaining better precision, robustness and speed. Our tests also show that the combination of markers and keypoints achieves better accuracy than each one of them independently.
3D human pose estimation from depth maps using a deep combination of poses
Jul 14, 2018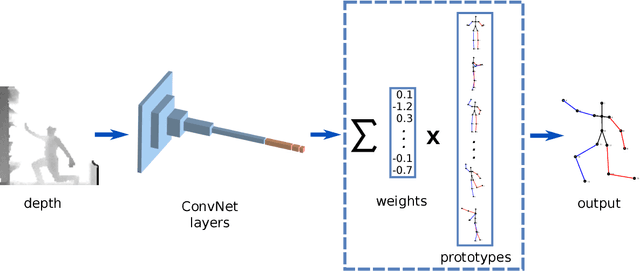


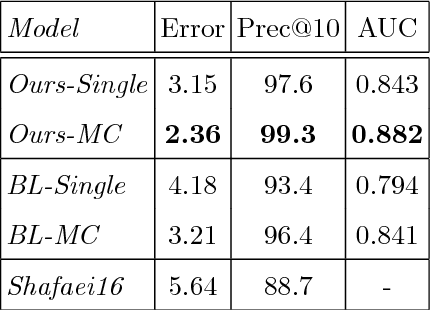
Many real-world applications require the estimation of human body joints for higher-level tasks as, for example, human behaviour understanding. In recent years, depth sensors have become a popular approach to obtain three-dimensional information. The depth maps generated by these sensors provide information that can be employed to disambiguate the poses observed in two-dimensional images. This work addresses the problem of 3D human pose estimation from depth maps employing a Deep Learning approach. We propose a model, named Deep Depth Pose (DDP), which receives a depth map containing a person and a set of predefined 3D prototype poses and returns the 3D position of the body joints of the person. In particular, DDP is defined as a ConvNet that computes the specific weights needed to linearly combine the prototypes for the given input. We have thoroughly evaluated DDP on the challenging 'ITOP' and 'UBC3V' datasets, which respectively depict realistic and synthetic samples, defining a new state-of-the-art on them.
Mapping and Localization from Planar Markers
Jan 25, 2017
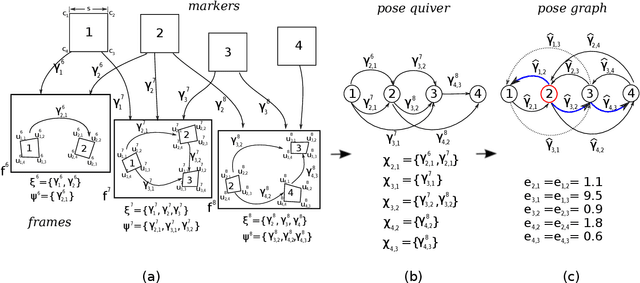

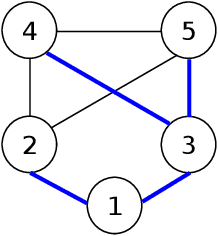
Squared planar markers are a popular tool for fast, accurate and robust camera localization, but its use is frequently limited to a single marker, or at most, to a small set of them for which their relative pose is known beforehand. Mapping and localization from a large set of planar markers is yet a scarcely treated problem in favour of keypoint-based approaches. However, while keypoint detectors are not robust to rapid motion, large changes in viewpoint, or significant changes in appearance, fiducial markers can be robustly detected under a wider range of conditions. This paper proposes a novel method to simultaneously solve the problems of mapping and localization from a set of squared planar markers. First, a quiver of pairwise relative marker poses is created, from which an initial pose graph is obtained. The pose graph may contain small pairwise pose errors, that when propagated, leads to large errors. Thus, we distribute the rotational and translational error along the basis cycles of the graph so as to obtain a corrected pose graph. Finally, we perform a global pose optimization by minimizing the reprojection errors of the planar markers in all observed frames. The experiments conducted show that our method performs better than Structure from Motion and visual SLAM techniques.