 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-based Tuning of Convolutional Neural Networks on Multi-GPUs
Paper and Code
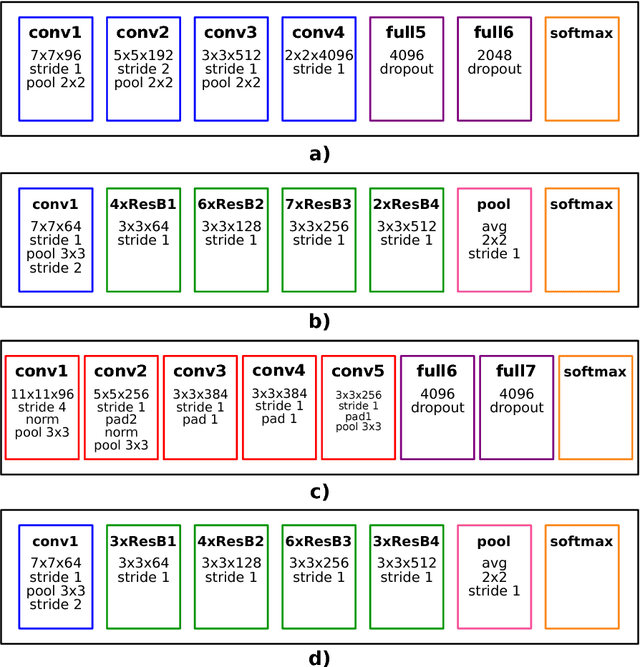

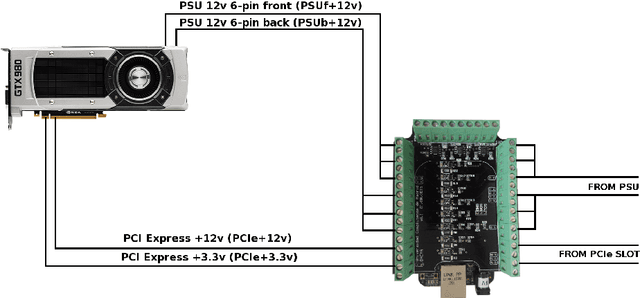
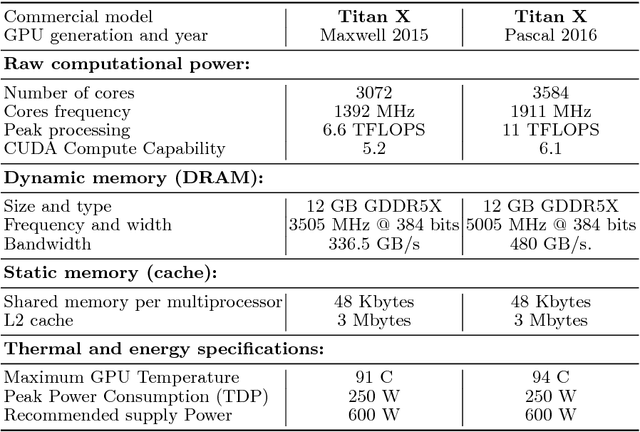
Deep Learning (DL) applications are gaining momentum in the realm of Artificial Intelligence, particularly after GPUs have demonstrated remarkable skills for accelerating their challenging computational requirements. Within this context, Convolutional Neural Network (CNN) models constitute a representative example of success on a wide set of complex applications, particularly on datasets where the target can be represented through a hierarchy of local features of increasing semantic complexity. In most of the real scenarios, the roadmap to improve results relies on CNN settings involving brute force computation, and researchers have lately proven Nvidia GPUs to be one of the best hardware counterparts for acceleration. Our work complements those findings with an energy study on critical parameters for the deployment of CNNs on flagship image and video applications: object recognition and people identification by gait, respectively. We evaluate energy consumption on four different networks based on the two most popular ones (ResNet/AlexNet): ResNet (167 layers), a 2D CNN (15 layers), a CaffeNet (25 layers) and a ResNetIm (94 layers) using batch sizes of 64, 128 and 256, and then correlate those with speed-up and accuracy to determine optimal settings. Experimental results on a multi-GPU server endowed with twin Maxwell and twin Pascal Titan X GPUs demonstrate that energy correlates with performance and that Pascal may have up to 40% gains versus Maxwell. Larger batch sizes extend performance gains and energy savings, but we have to keep an eye on accuracy, which sometimes shows a preference for small batches. We expect this work to provide a preliminary guidance for a wide set of CNN and DL applications in modern HPC times, where the GFLOPS/w ratio constitutes the primary goal.