 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADE: Forecasting for Anomaly Detection on ECG
Feb 11, 2025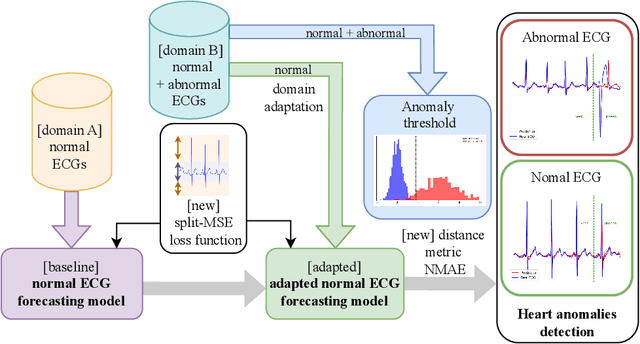
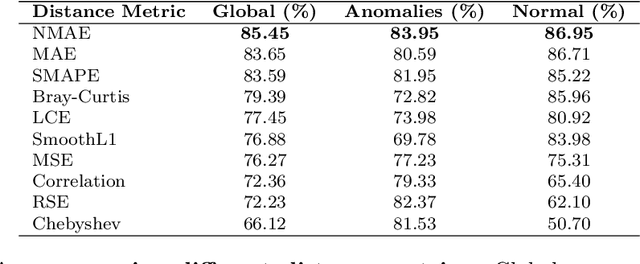
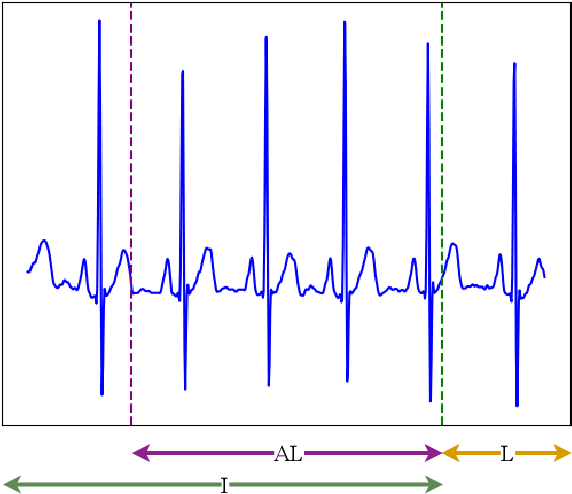

Cardiovascular diseases, a leading cause of noncommunicable disease-related deaths, require early and accurate detection to improve patient outcomes. Taking advantage of advances in machine learning and deep learning, multiple approaches have been proposed in the literature to address the challenge of detecting ECG anomalies. Typically, these methods are based on the manual interpretation of ECG signals, which is time consuming and depends on the expertise of healthcare professionals. The objective of this work is to propose a deep learning system, FADE, designed for normal ECG forecasting and anomaly detection, which reduces the need for extensive labeled datasets and manual interpretation. FADE has been trained in a self-supervised manner with a novel morphological inspired loss function. Unlike conventional models that learn from labeled anomalous ECG waveforms, our approach predicts the future of normal ECG signals, thus avoiding the need for extensive labeled datasets. Using a novel distance function to compare forecasted ECG signals with actual sensor data, our method effectively identifies cardiac anomalies. Additionally, this approach can be adapted to new contexts through domain adaptation techniques. To evaluate our proposal, we performed a set of experiments using two publicly available datasets: MIT-BIH NSR and MIT-BIH Arrythmia. The results demonstrate that our system achieves an average accuracy of 83.84% in anomaly detection, while correctly classifying normal ECG signals with an accuracy of 85.46%. Our proposed approach exhibited superior performance in the early detection of cardiac anomalies in ECG signals, surpassing previous methods that predominantly identify a limited range of anomalies. FADE effectively detects both abnormal heartbeats and arrhythmias, offering significant advantages in healthcare through cost reduction or processing of large-scale ECG data.
Lightweight Structure-Aware Attention for Visual Understanding
Nov 29, 2022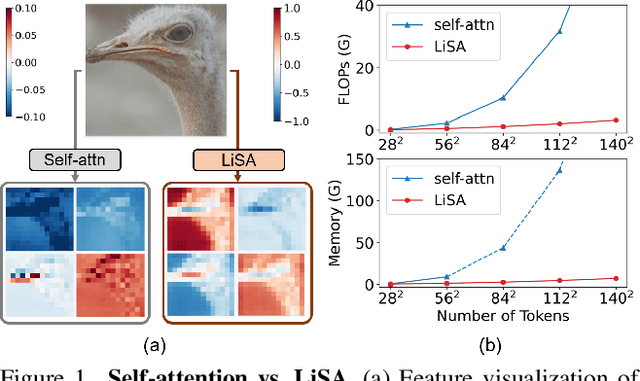
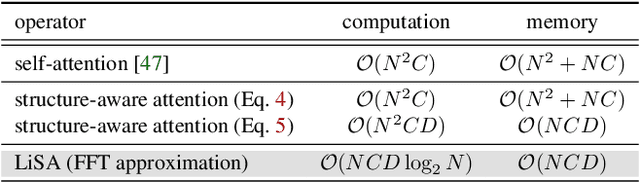
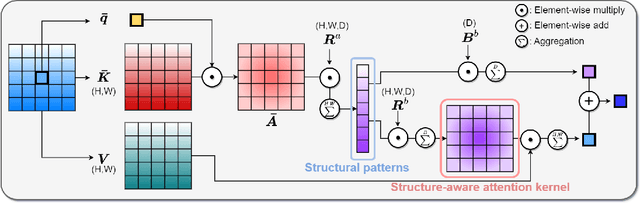
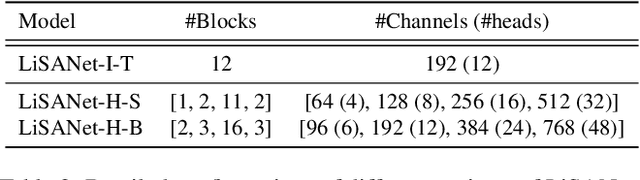
Vision Transformers (ViTs) have become a dominant paradigm for visual representation learning with self-attention operators. Although these operators provide flexibility to the model with their adjustable attention kernels, they suffer from inherent limitations: (1) the attention kernel is not discriminative enough, resulting in high redundancy of the ViT layers, and (2) the complexity in computation and memory is quadratic in the sequence length. In this paper, we propose a novel attention operator, called lightweight structure-aware attention (LiSA), which has a better representation power with log-linear complexity. Our operator learns structural patterns by using a set of relative position embeddings (RPEs). To achieve log-linear complexity, the RPEs are approximated with fast Fourier transforms. Our experiments and ablation studies demonstrate that ViTs based on the proposed operator outperform self-attention and other existing operators, achieving state-of-the-art results on ImageNet, and competitive results on other visual understanding benchmarks such as COCO and Something-Something-V2. The source code of our approach will be released online.
iLGaCo: Incremental Learning of Gait Covariate Factors
Aug 31, 2020
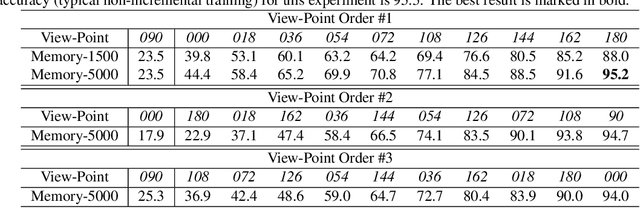
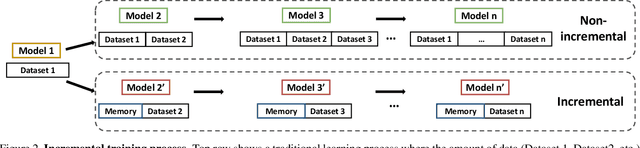
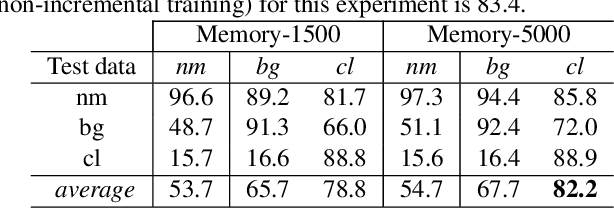
Gait is a popular biometric pattern used for identifying people based on their way of walking. Traditionally, gait recognition approaches based on deep learning are trained using the whole training dataset. In fact, if new data (classes, view-points, walking conditions, etc.) need to be included, it is necessary to re-train again the model with old and new data samples. In this paper, we propose iLGaCo, the first incremental learning approach of covariate factors for gait recognition, where the deep model can be updated with new information without re-training it from scratch by using the whole dataset. Instead, our approach performs a shorter training process with the new data and a small subset of previous samples. This way, our model learns new information while retaining previous knowledge. We evaluate iLGaCo on CASIA-B dataset in two incremental ways: adding new view-points and adding new walking conditions. In both cases, our results are close to the classical `training-from-scratch' approach, obtaining a marginal drop in accuracy ranging from 0.2% to 1.2%, what shows the efficacy of our approach. In addition, the comparison of iLGaCo with other incremental learning methods, such as LwF and iCarl, shows a significant improvement in accuracy, between 6% and 15% depending on the experiment.
End-to-End Incremental Learning
Sep 03, 2018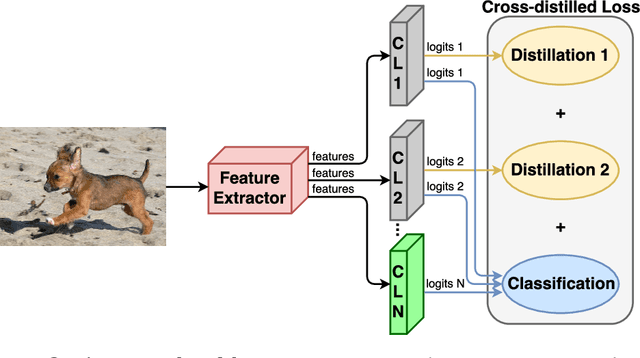

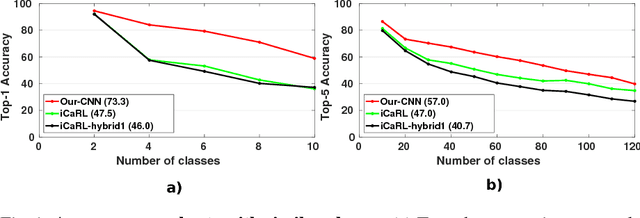
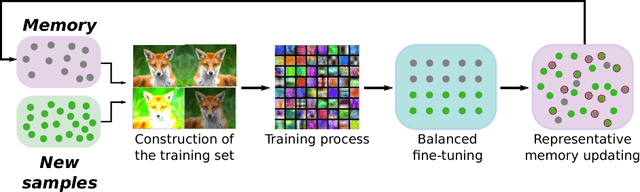
Although deep learning approaches have stood out in recent years due to their state-of-the-art results, they continue to suffer from catastrophic forgetting, a dramatic decrease in overall performance when training with new classes added incrementally. This is due to current neural network architectures requiring the entire dataset, consisting of all the samples from the old as well as the new classes, to update the model -a requirement that becomes easily unsustainable as the number of classes grows. We address this issue with our approach to learn deep neural networks incrementally, using new data and only a small exemplar set corresponding to samples from the old classes. This is based on a loss composed of a distillation measure to retain the knowledge acquired from the old classes, and a cross-entropy loss to learn the new classes. Our incremental training is achieved while keeping the entire framework end-to-end, i.e., learning the data representation and the classifier jointly, unlike recent methods with no such guarantees. We evaluate our method extensively on the CIFAR-100 and ImageNet (ILSVRC 2012) image classification datasets, and show state-of-the-art performance.
Energy-based Tuning of Convolutional Neural Networks on Multi-GPUs
Aug 01, 2018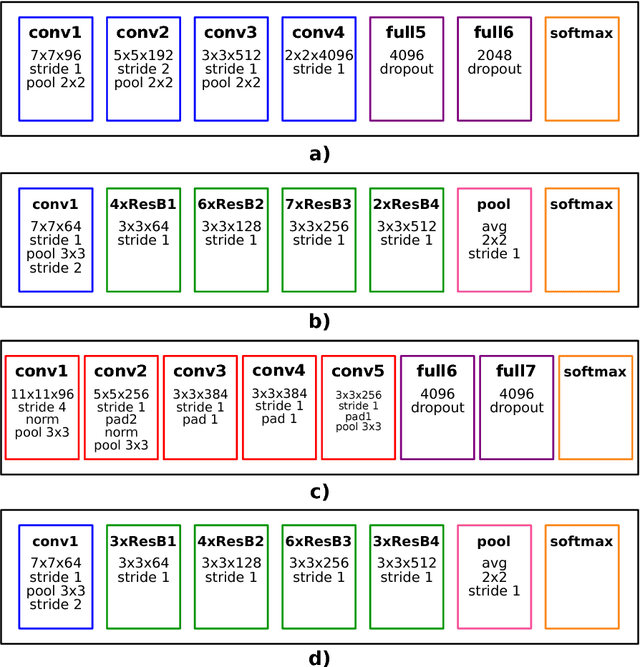

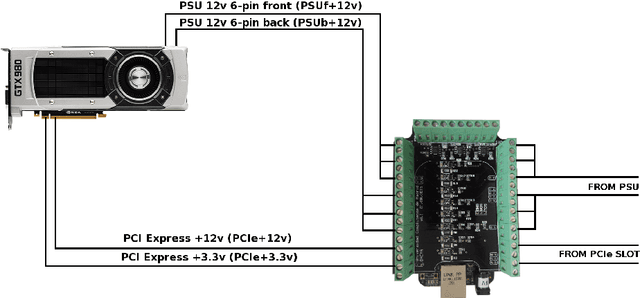
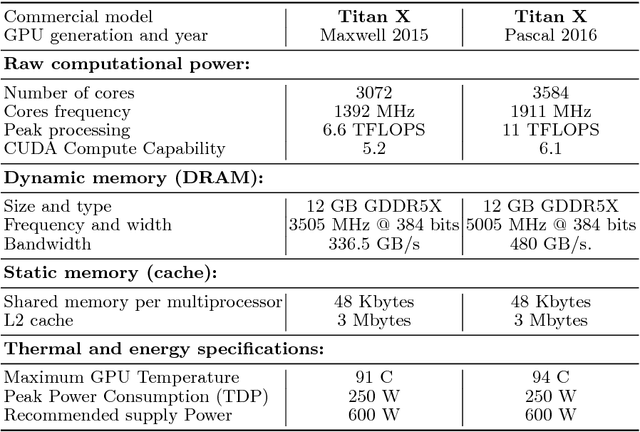
Deep Learning (DL) applications are gaining momentum in the realm of Artificial Intelligence, particularly after GPUs have demonstrated remarkable skills for accelerating their challenging computational requirements. Within this context, Convolutional Neural Network (CNN) models constitute a representative example of success on a wide set of complex applications, particularly on datasets where the target can be represented through a hierarchy of local features of increasing semantic complexity. In most of the real scenarios, the roadmap to improve results relies on CNN settings involving brute force computation, and researchers have lately proven Nvidia GPUs to be one of the best hardware counterparts for acceleration. Our work complements those findings with an energy study on critical parameters for the deployment of CNNs on flagship image and video applications: object recognition and people identification by gait, respectively. We evaluate energy consumption on four different networks based on the two most popular ones (ResNet/AlexNet): ResNet (167 layers), a 2D CNN (15 layers), a CaffeNet (25 layers) and a ResNetIm (94 layers) using batch sizes of 64, 128 and 256, and then correlate those with speed-up and accuracy to determine optimal settings. Experimental results on a multi-GPU server endowed with twin Maxwell and twin Pascal Titan X GPUs demonstrate that energy correlates with performance and that Pascal may have up to 40% gains versus Maxwell. Larger batch sizes extend performance gains and energy savings, but we have to keep an eye on accuracy, which sometimes shows a preference for small batches. We expect this work to provide a preliminary guidance for a wide set of CNN and DL applications in modern HPC times, where the GFLOPS/w ratio constitutes the primary goal.