 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Fine-tuning for Image Enhancement of Super-Resolution Deep Neural Networks
Paper and Code
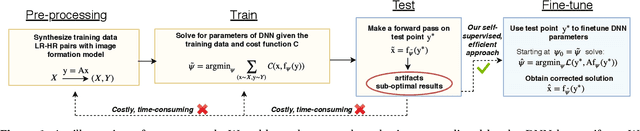



While Deep Neural Networks (DNNs) trained for image and video super-resolution regularly achieve new state-of-the-art performance, they also suffer from significant drawbacks. One of their limitations is their tendency to generate strong artifacts in their solution. This may occur when the low-resolution image formation model does not match that seen during training. Artifacts also regularly arise when training Generative Adversarial Networks for inverse imaging problems. In this paper, we propose an efficient, fully self-supervised approach to remove the observed artifacts. More specifically, at test time, given an image and its known image formation model, we fine-tune the parameters of the trained network and iteratively update them using a data consistency loss. We apply our method to image and video super-resolution neural networks and show that our proposed framework consistently enhances the solution originally provided by the neural network.