 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning with Differentiable Architecture and Forgetting Search
May 19, 2022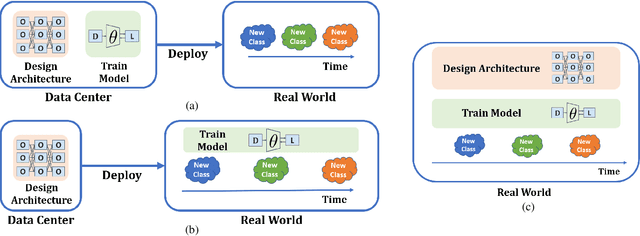
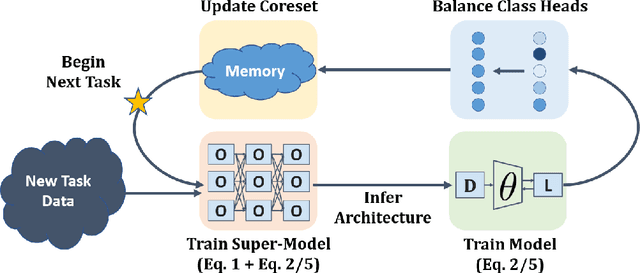
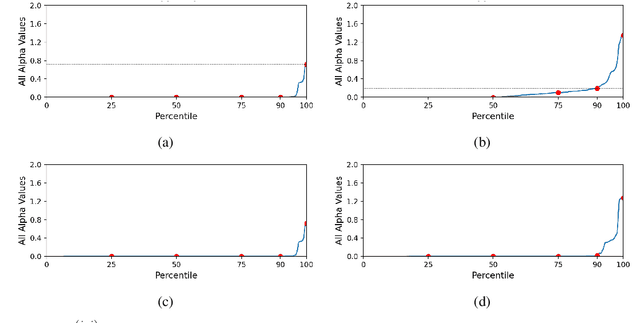
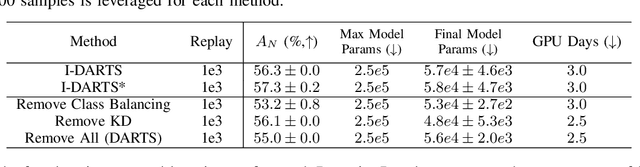
As progress is made on training machine learning models on incrementally expanding classification tasks (i.e., incremental learning), a next step is to translate this progress to industry expectations. One technique missing from incremental learning is automatic architecture design via Neural Architecture Search (NAS). In this paper, we show that leveraging NAS for incremental learning results in strong performance gains for classification tasks. Specifically, we contribute the following: first, we create a strong baseline approach for incremental learning based on Differentiable Architecture Search (DARTS) and state-of-the-art incremental learning strategies, outperforming many existing strategies trained with similar-sized popular architectures; second, we extend the idea of architecture search to regularize architecture forgetting, boosting performance past our proposed baseline. We evaluate our method on both RF signal and image classification tasks, and demonstrate we can achieve up to a 10% performance increase over state-of-the-art methods. Most importantly, our contribution enables learning from continuous distributions on real-world application data for which the complexity of the data distribution is unknown, or the modality less explored (such as RF signal classification).
GraphMapper: Efficient Visual Navigation by Scene Graph Generation
May 17, 2022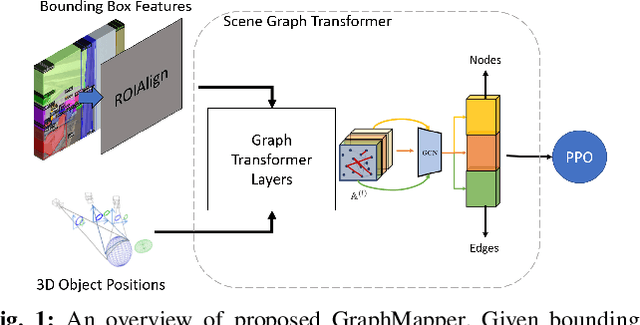
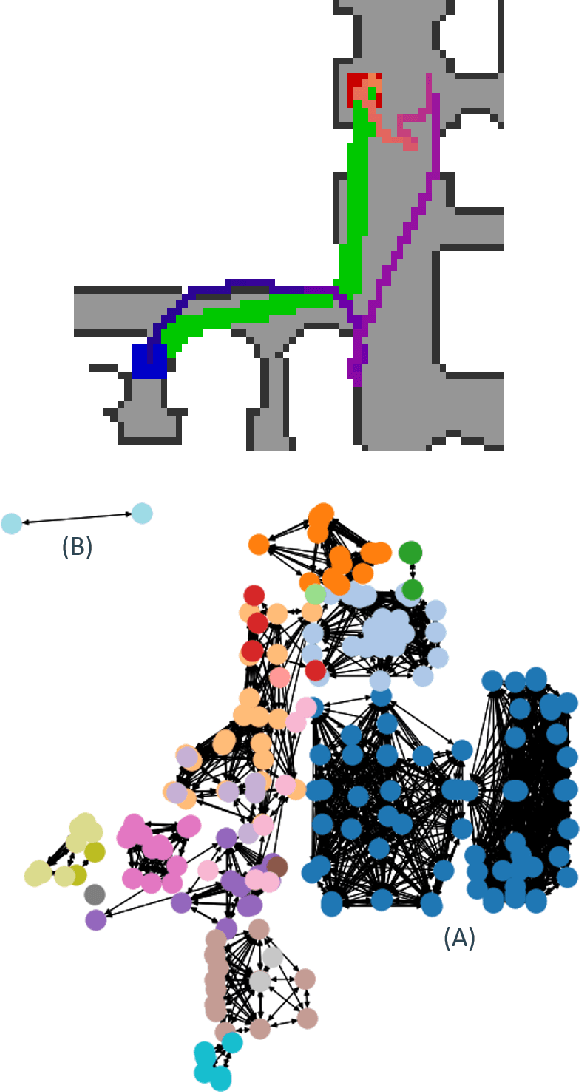
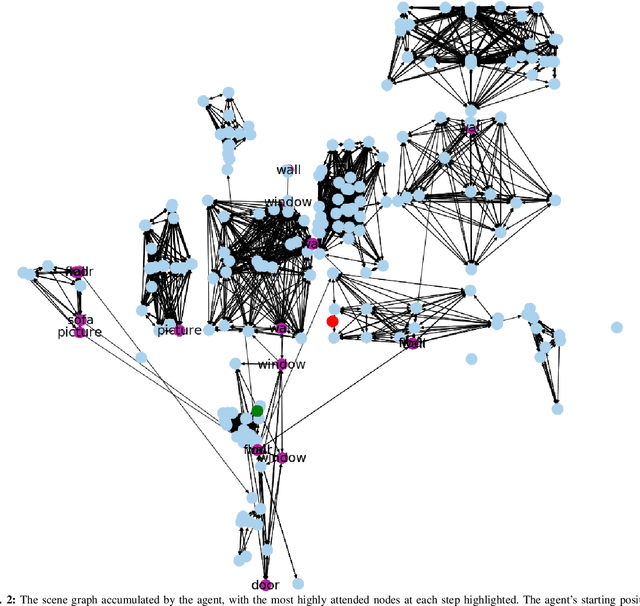
Understanding the geometric relationships between objects in a scene is a core capability in enabling both humans and autonomous agents to navigate in new environments. A sparse, unified representation of the scene topology will allow agents to act efficiently to move through their environment, communicate the environment state with others, and utilize the representation for diverse downstream tasks. To this end, we propose a method to train an autonomous agent to learn to accumulate a 3D scene graph representation of its environment by simultaneously learning to navigate through said environment. We demonstrate that our approach, GraphMapper, enables the learning of effective navigation policies through fewer interactions with the environment than vision-based systems alone. Further, we show that GraphMapper can act as a modular scene encoder to operate alongside existing Learning-based solutions to not only increase navigational efficiency but also generate intermediate scene representations that are useful for other future tasks.
SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments
Aug 26, 2021
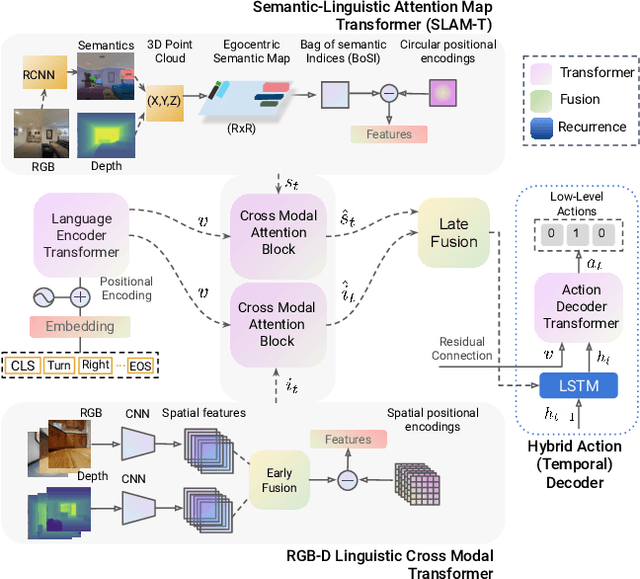
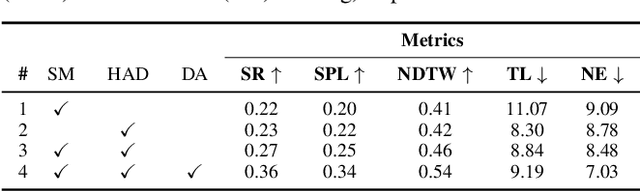
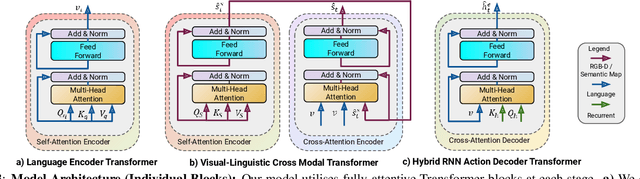
This paper presents a novel approach for the Vision-and-Language Navigation (VLN) task in continuous 3D environments, which requires an autonomous agent to follow natural language instructions in unseen environments. Existing end-to-end learning-based VLN methods struggle at this task as they focus mostly on utilizing raw visual observations and lack the semantic spatio-temporal reasoning capabilities which is crucial in generalizing to new environments. In this regard, we present a hybrid transformer-recurrence model which focuses on combining classical semantic mapping techniques with a learning-based method. Our method creates a temporal semantic memory by building a top-down local ego-centric semantic map and performs cross-modal grounding to align map and language modalities to enable effective learning of VLN policy. Empirical results in a photo-realistic long-horizon simulation environment show that the proposed approach outperforms a variety of state-of-the-art methods and baselines with over 22% relative improvement in SPL in prior unseen environments.
MaAST: Map Attention with Semantic Transformersfor Efficient Visual Navigation
Mar 21, 2021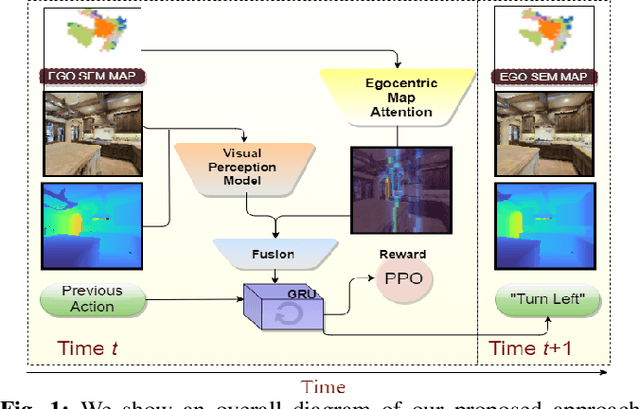

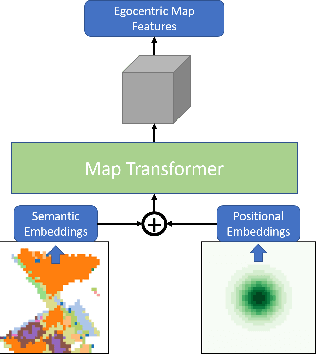
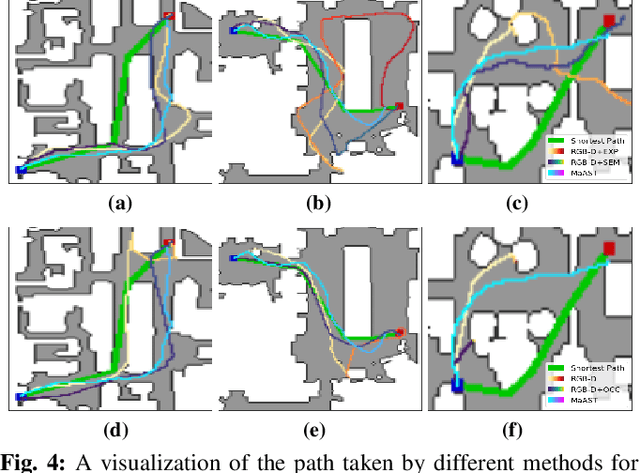
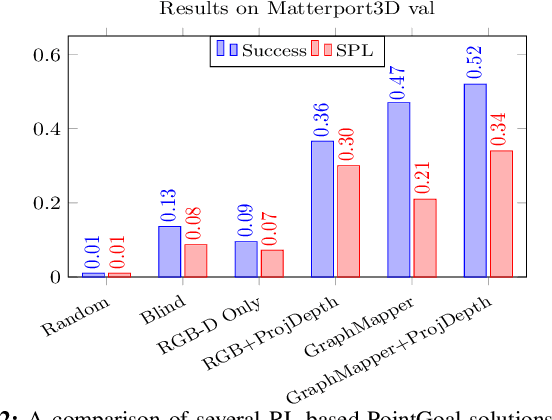
Visual navigation for autonomous agents is a core task in the fields of computer vision and robotics. Learning-based methods, such as deep reinforcement learning, have the potential to outperform the classical solutions developed for this task; however, they come at a significantly increased computational load. Through this work, we design a novel approach that focuses on performing better or comparable to the existing learning-based solutions but under a clear time/computational budget. To this end, we propose a method to encode vital scene semantics such as traversable paths, unexplored areas, and observed scene objects -- alongside raw visual streams such as RGB, depth, and semantic segmentation masks -- into a semantically informed, top-down egocentric map representation. Further, to enable the effective use of this information, we introduce a novel 2-D map attention mechanism, based on the successful multi-layer Transformer networks. We conduct experiments on 3-D reconstructed indoor PointGoal visual navigation and demonstrate the effectiveness of our approach. We show that by using our novel attention schema and auxiliary rewards to better utilize scene semantics, we outperform multiple baselines trained with only raw inputs or implicit semantic information while operating with an 80% decrease in the agent's experience.
Semantically-Aware Attentive Neural Embeddings for Image-based Visual Localization
Dec 08, 2018
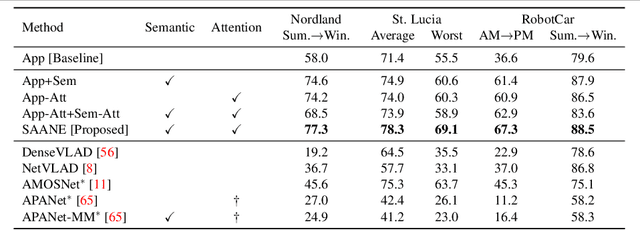
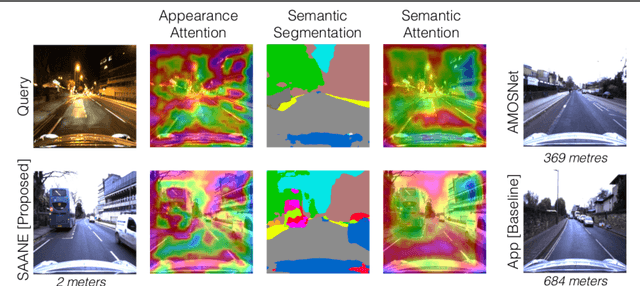
We present a novel method for fusing appearance and semantic information using visual attention for 2D image-based localization (2D-VL) across extreme changes in viewing conditions. Our deep learning based method is motivated by the intuition that specific scene regions remain stable in the semantic modality even in the presence of vast differences in the appearance modality. The proposed attention-based module learns to focus not only on discriminative visual regions for place recognition but also on consistently stable semantic regions to perform 2D-VL. We show the effectiveness of this model by comparing against state-of-the-art (SOTA) methods on several challenging localization datasets. We report an average absolute improvement of 19% over current SOTA 2D-VL methods. Furthermore, we present an extensive study demonstrating the effectiveness and contribution of each component of our model, showing 8%-15% absolute improvement from adding semantic information, and an additional 4% from our proposed attention module, over both prior methods as well as a competitive baseline.
Multimodal Skip-gram Using Convolutional Pseudowords
Nov 29, 2015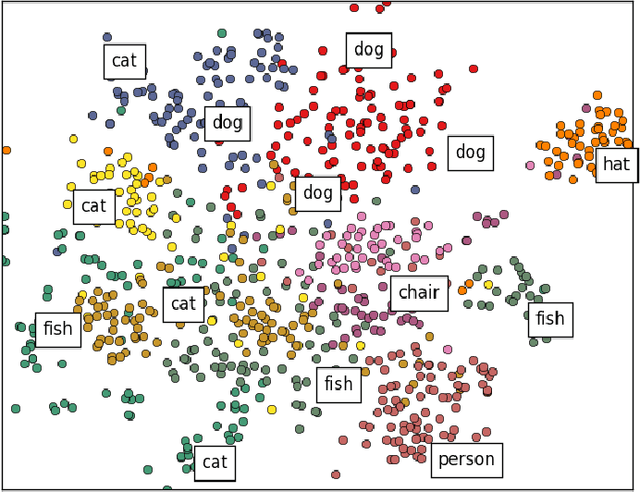
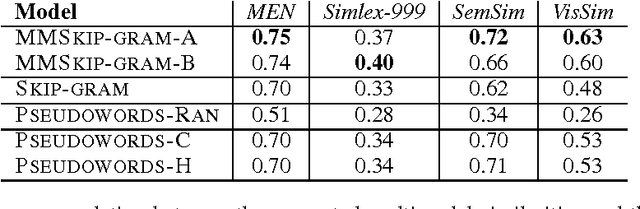

This work studies the representational mapping across multimodal data such that given a piece of the raw data in one modality the corresponding semantic description in terms of the raw data in another modality is immediately obtained. Such a representational mapping can be found in a wide spectrum of real-world applications including image/video retrieval, object recognition, action/behavior recognition, and event understanding and prediction. To that end, we introduce a simplified training objective for learning multimodal embeddings using the skip-gram architecture by introducing convolutional "pseudowords:" embeddings composed of the additive combination of distributed word representations and image features from convolutional neural networks projected into the multimodal space. We present extensive results of the representational properties of these embeddings on various word similarity benchmarks to show the promise of this approach.