 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-Aware Attentive Neural Embeddings for Image-based Visual Localization
Paper and Code
Dec 08, 2018
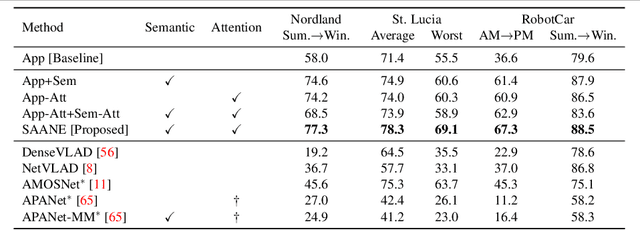
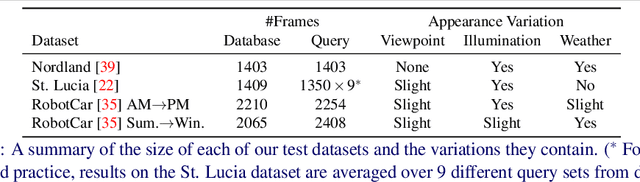
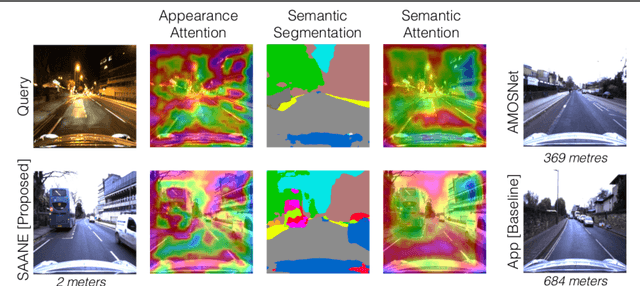
We present a novel method for fusing appearance and semantic information using visual attention for 2D image-based localization (2D-VL) across extreme changes in viewing conditions. Our deep learning based method is motivated by the intuition that specific scene regions remain stable in the semantic modality even in the presence of vast differences in the appearance modality. The proposed attention-based module learns to focus not only on discriminative visual regions for place recognition but also on consistently stable semantic regions to perform 2D-VL. We show the effectiveness of this model by comparing against state-of-the-art (SOTA) methods on several challenging localization datasets. We report an average absolute improvement of 19% over current SOTA 2D-VL methods. Furthermore, we present an extensive study demonstrating the effectiveness and contribution of each component of our model, showing 8%-15% absolute improvement from adding semantic information, and an additional 4% from our proposed attention module, over both prior methods as well as a competitive baseline.