 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Skip-gram Using Convolutional Pseudowords
Paper and Code
Nov 29, 2015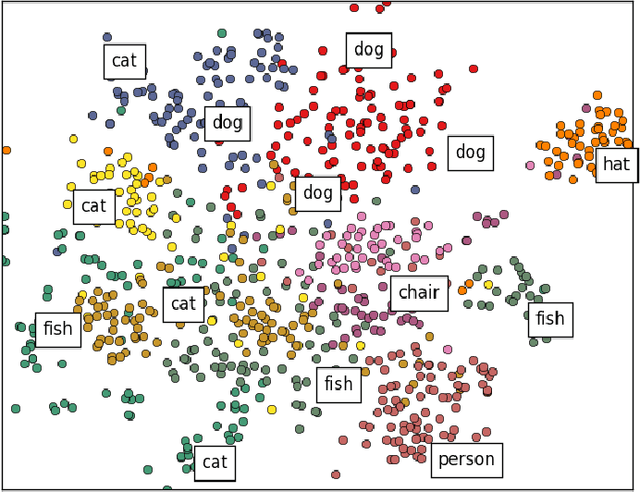
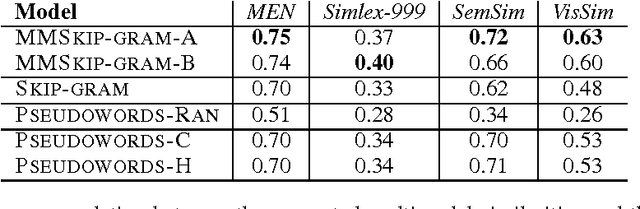

This work studies the representational mapping across multimodal data such that given a piece of the raw data in one modality the corresponding semantic description in terms of the raw data in another modality is immediately obtained. Such a representational mapping can be found in a wide spectrum of real-world applications including image/video retrieval, object recognition, action/behavior recognition, and event understanding and prediction. To that end, we introduce a simplified training objective for learning multimodal embeddings using the skip-gram architecture by introducing convolutional "pseudowords:" embeddings composed of the additive combination of distributed word representations and image features from convolutional neural networks projected into the multimodal space. We present extensive results of the representational properties of these embeddings on various word similarity benchmarks to show the promise of this approach.