 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Priming for Detecting Human-Object Interactions
Paper and Code
Apr 09, 2020
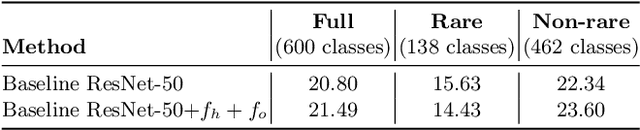
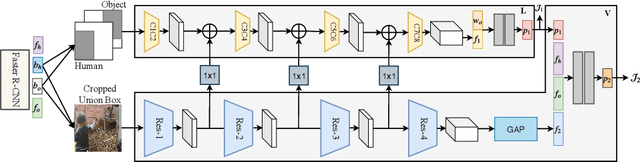
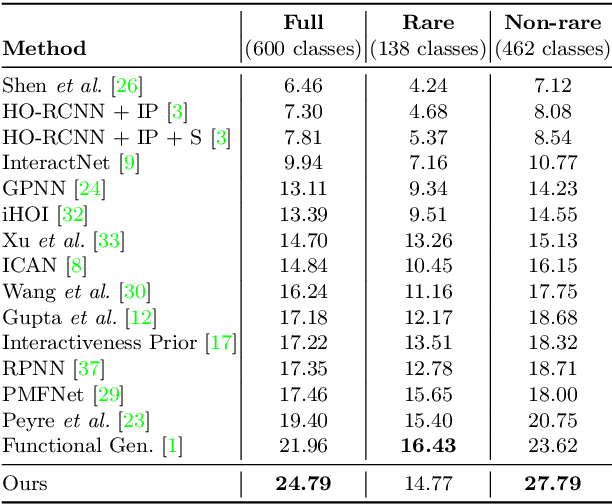
The relative spatial layout of a human and an object is an important cue for determining how they interact. However, until now, spatial layout has been used just as side-information for detecting human-object interactions (HOIs). In this paper, we present a method for exploiting this spatial layout information for detecting HOIs in images. The proposed method consists of a layout module which primes a visual module to predict the type of interaction between a human and an object. The visual and layout modules share information through lateral connections at several stages. The model uses predictions from the layout module as a prior to the visual module and the prediction from the visual module is given as the final output. It also incorporates semantic information about the object using word2vec vectors. The proposed model reaches an mAP of 24.79% for HICO-Det dataset which is about 2.8% absolute points higher than the current state-of-the-art.