 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking for a better fit? An Incremental Learning Multimodal Object Referencing Framework adapting to Individual Drivers
Feb 07, 2024


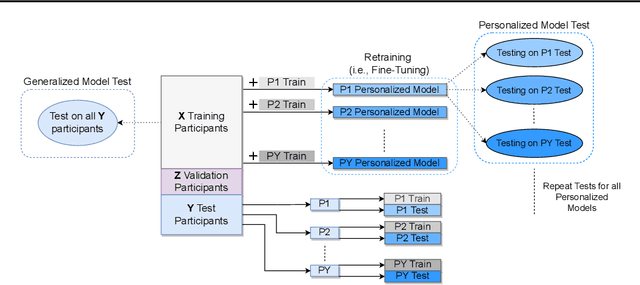
The rapid advancement of the automotive industry towards automated and semi-automated vehicles has rendered traditional methods of vehicle interaction, such as touch-based and voice command systems, inadequate for a widening range of non-driving related tasks, such as referencing objects outside of the vehicle. Consequently, research has shifted toward gestural input (e.g., hand, gaze, and head pose gestures) as a more suitable mode of interaction during driving. However, due to the dynamic nature of driving and individual variation, there are significant differences in drivers' gestural input performance. While, in theory, this inherent variability could be moderated by substantial data-driven machine learning models, prevalent methodologies lean towards constrained, single-instance trained models for object referencing. These models show a limited capacity to continuously adapt to the divergent behaviors of individual drivers and the variety of driving scenarios. To address this, we propose \textit{IcRegress}, a novel regression-based incremental learning approach that adapts to changing behavior and the unique characteristics of drivers engaged in the dual task of driving and referencing objects. We suggest a more personalized and adaptable solution for multimodal gestural interfaces, employing continuous lifelong learning to enhance driver experience, safety, and convenience. Our approach was evaluated using an outside-the-vehicle object referencing use case, highlighting the superiority of the incremental learning models adapted over a single trained model across various driver traits such as handedness, driving experience, and numerous driving conditions. Finally, to facilitate reproducibility, ease deployment, and promote further research, we offer our approach as an open-source framework at \url{https://github.com/amrgomaaelhady/IcRegress}.
It's all about you: Personalized in-Vehicle Gesture Recognition with a Time-of-Flight Camera
Oct 02, 2023



Despite significant advances in gesture recognition technology, recognizing gestures in a driving environment remains challenging due to limited and costly data and its dynamic, ever-changing nature. In this work, we propose a model-adaptation approach to personalize the training of a CNNLSTM model and improve recognition accuracy while reducing data requirements. Our approach contributes to the field of dynamic hand gesture recognition while driving by providing a more efficient and accurate method that can be customized for individual users, ultimately enhancing the safety and convenience of in-vehicle interactions, as well as driver's experience and system trust. We incorporate hardware enhancement using a time-of-flight camera and algorithmic enhancement through data augmentation, personalized adaptation, and incremental learning techniques. We evaluate the performance of our approach in terms of recognition accuracy, achieving up to 90\%, and show the effectiveness of personalized adaptation and incremental learning for a user-centered design.
Adaptive User-centered Neuro-symbolic Learning for Multimodal Interaction with Autonomous Systems
Sep 11, 2023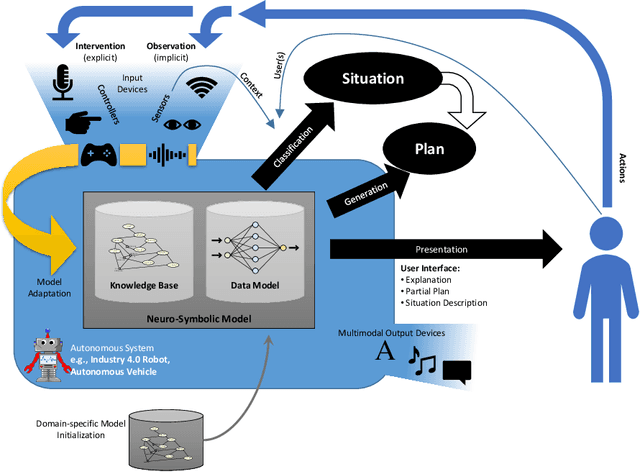
Recent advances in machine learning, particularly deep learning, have enabled autonomous systems to perceive and comprehend objects and their environments in a perceptual subsymbolic manner. These systems can now perform object detection, sensor data fusion, and language understanding tasks. However, there is a growing need to enhance these systems to understand objects and their environments more conceptually and symbolically. It is essential to consider both the explicit teaching provided by humans (e.g., describing a situation or explaining how to act) and the implicit teaching obtained by observing human behavior (e.g., through the system's sensors) to achieve this level of powerful artificial intelligence. Thus, the system must be designed with multimodal input and output capabilities to support implicit and explicit interaction models. In this position paper, we argue for considering both types of inputs, as well as human-in-the-loop and incremental learning techniques, for advancing the field of artificial intelligence and enabling autonomous systems to learn like humans. We propose several hypotheses and design guidelines and highlight a use case from related work to achieve this goal.
Teach Me How to Learn: A Perspective Review towards User-centered Neuro-symbolic Learning for Robotic Surgical Systems
Jul 07, 2023Recent advances in machine learning models allowed robots to identify objects on a perceptual nonsymbolic level (e.g., through sensor fusion and natural language understanding). However, these primarily black-box learning models still lack interpretation and transferability and require high data and computational demand. An alternative solution is to teach a robot on both perceptual nonsymbolic and conceptual symbolic levels through hybrid neurosymbolic learning approaches with expert feedback (i.e., human-in-the-loop learning). This work proposes a concept for this user-centered hybrid learning paradigm that focuses on robotic surgical situations. While most recent research focused on hybrid learning for non-robotic and some generic robotic domains, little work focuses on surgical robotics. We survey this related research while focusing on human-in-the-loop surgical robotic systems. This evaluation highlights the most prominent solutions for autonomous surgical robots and the challenges surgeons face when interacting with these systems. Finally, we envision possible ways to address these challenges using online apprenticeship learning based on implicit and explicit feedback from expert surgeons.
ML-PersRef: A Machine Learning-based Personalized Multimodal Fusion Approach for Referencing Outside Objects From a Moving Vehicle
Nov 03, 2021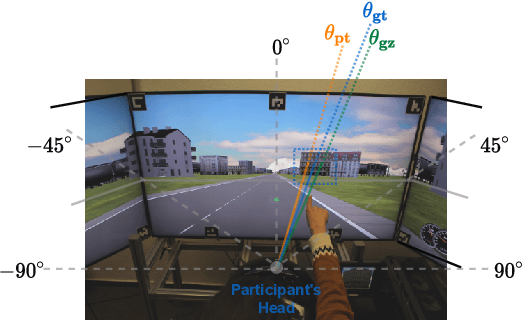

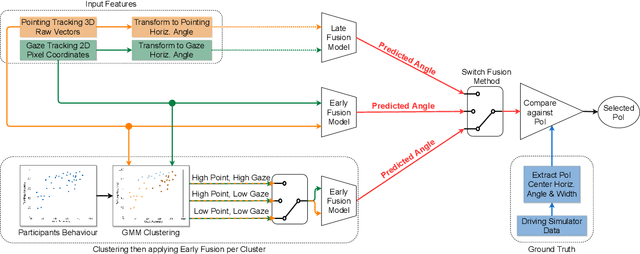
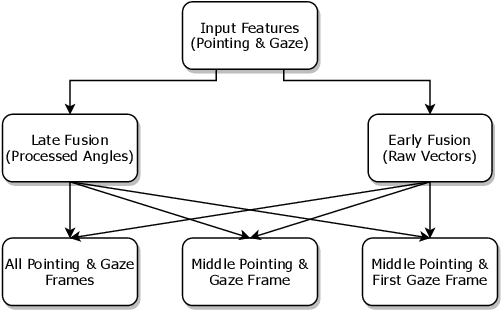
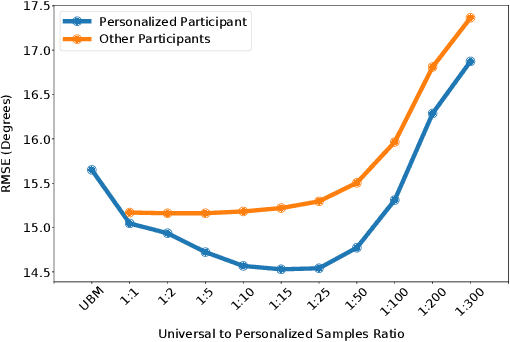
Over the past decades, the addition of hundreds of sensors to modern vehicles has led to an exponential increase in their capabilities. This allows for novel approaches to interaction with the vehicle that go beyond traditional touch-based and voice command approaches, such as emotion recognition, head rotation, eye gaze, and pointing gestures. Although gaze and pointing gestures have been used before for referencing objects inside and outside vehicles, the multimodal interaction and fusion of these gestures have so far not been extensively studied. We propose a novel learning-based multimodal fusion approach for referencing outside-the-vehicle objects while maintaining a long driving route in a simulated environment. The proposed multimodal approaches outperform single-modality approaches in multiple aspects and conditions. Moreover, we also demonstrate possible ways to exploit behavioral differences between users when completing the referencing task to realize an adaptable personalized system for each driver. We propose a personalization technique based on the transfer-of-learning concept for exceedingly small data sizes to enhance prediction and adapt to individualistic referencing behavior. Our code is publicly available at https://github.com/amr-gomaa/ML-PersRef.
Multimodal Fusion Using Deep Learning Applied to Driver's Referencing of Outside-Vehicle Objects
Jul 26, 2021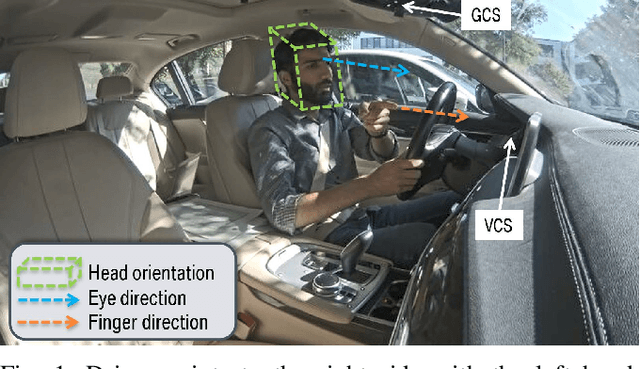
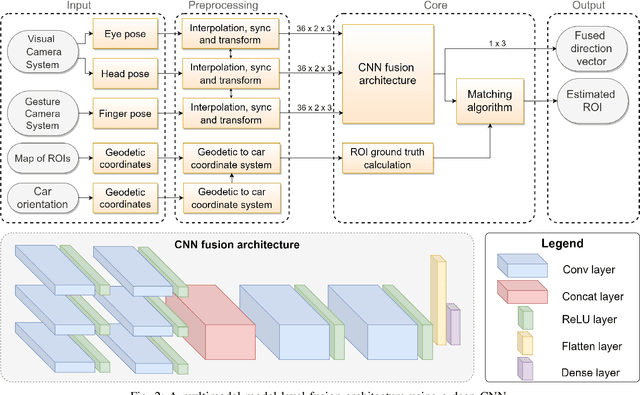
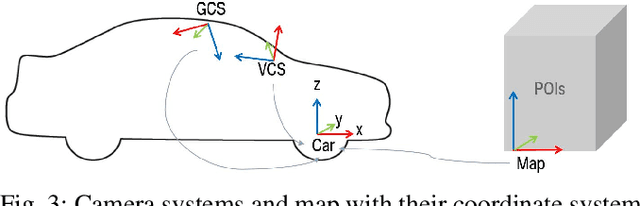

There is a growing interest in more intelligent natural user interaction with the car. Hand gestures and speech are already being applied for driver-car interaction. Moreover, multimodal approaches are also showing promise in the automotive industry. In this paper, we utilize deep learning for a multimodal fusion network for referencing objects outside the vehicle. We use features from gaze, head pose and finger pointing simultaneously to precisely predict the referenced objects in different car poses. We demonstrate the practical limitations of each modality when used for a natural form of referencing, specifically inside the car. As evident from our results, we overcome the modality specific limitations, to a large extent, by the addition of other modalities. This work highlights the importance of multimodal sensing, especially when moving towards natural user interaction. Furthermore, our user based analysis shows noteworthy differences in recognition of user behavior depending upon the vehicle pose.
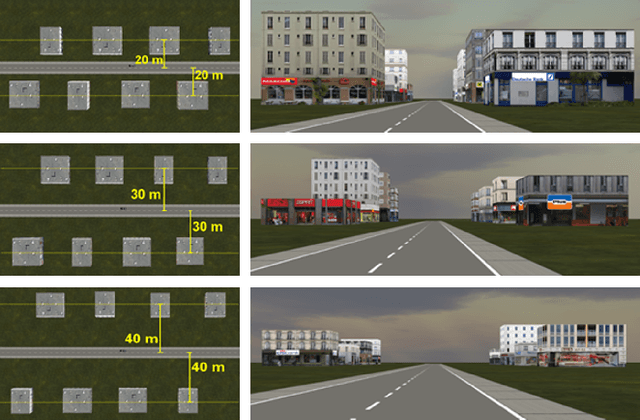
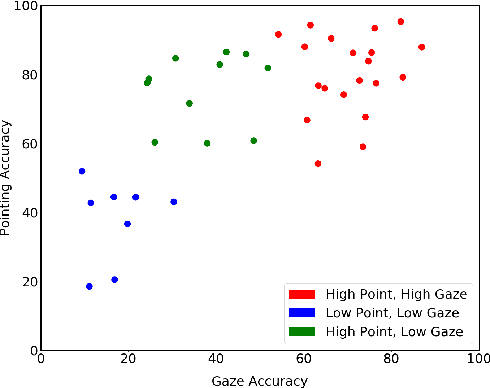
Studying Person-Specific Pointing and Gaze Behavior for Multimodal Referencing of Outside Objects from a Moving Vehicle
Sep 23, 2020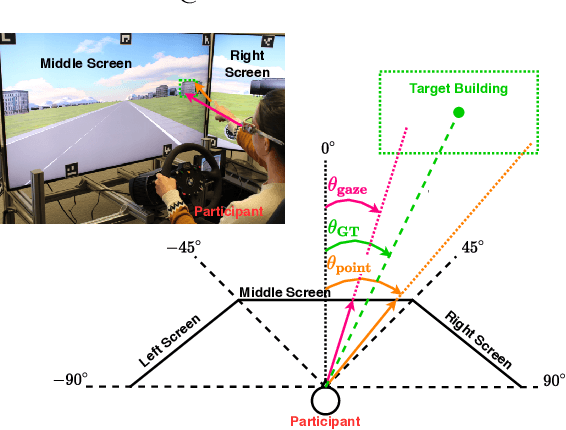


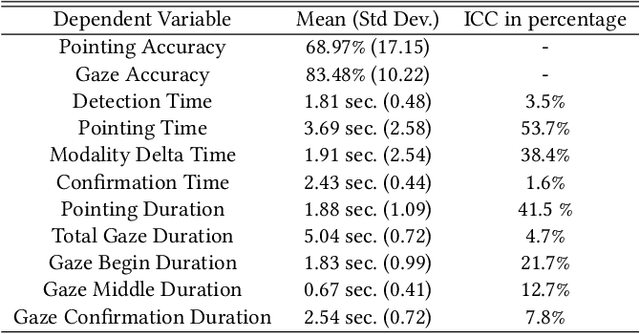
Hand pointing and eye gaze have been extensively investigated in automotive applications for object selection and referencing. Despite significant advances, existing outside-the-vehicle referencing methods consider these modalities separately. Moreover, existing multimodal referencing methods focus on a static situation, whereas the situation in a moving vehicle is highly dynamic and subject to safety-critical constraints. In this paper, we investigate the specific characteristics of each modality and the interaction between them when used in the task of referencing outside objects (e.g. buildings) from the vehicle. We furthermore explore person-specific differences in this interaction by analyzing individuals' performance for pointing and gaze patterns, along with their effect on the driving task. Our statistical analysis shows significant differences in individual behaviour based on object's location (i.e. driver's right side vs. left side), object's surroundings, driving mode (i.e. autonomous vs. normal driving) as well as pointing and gaze duration, laying the foundation for a user-adaptive approach.