 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Driver Referencing: A Comparison of Pointing to Objects Inside and Outside the Vehicle
Feb 15, 2022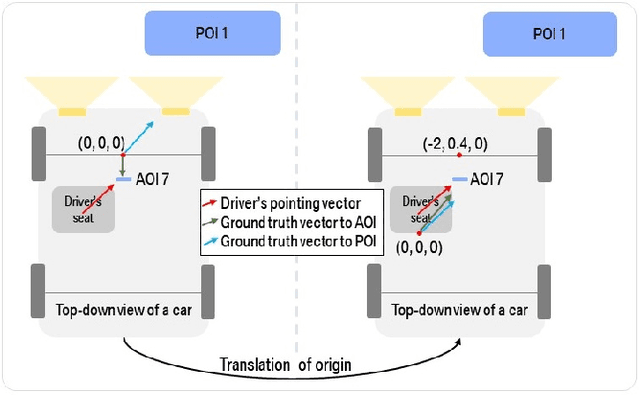
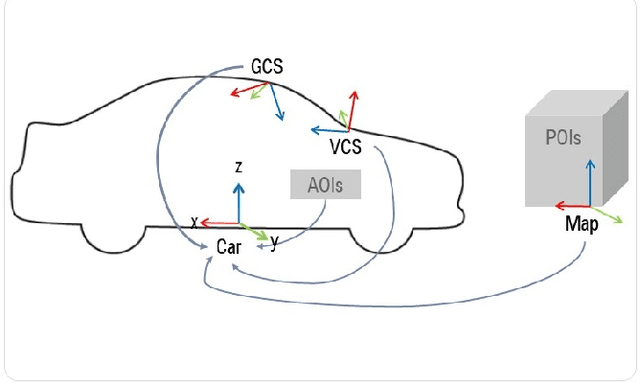
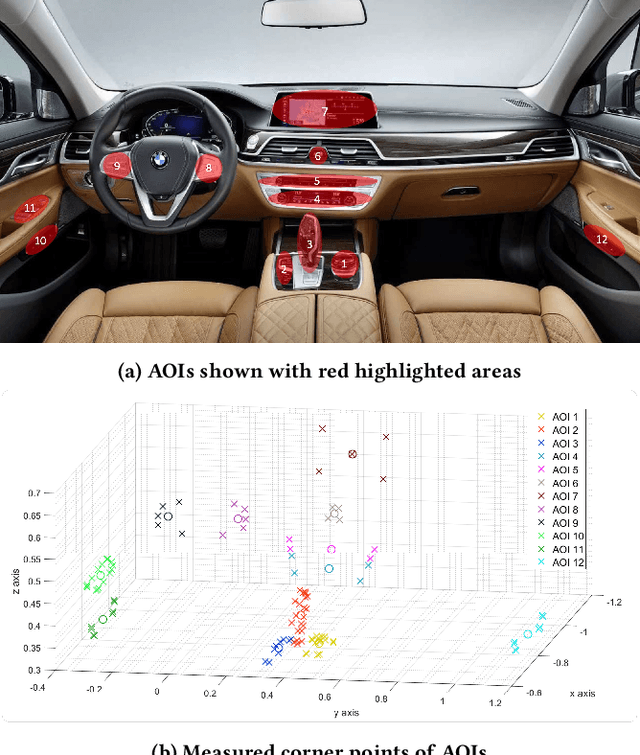

Advanced in-cabin sensing technologies, especially vision based approaches, have tremendously progressed user interaction inside the vehicle, paving the way for new applications of natural user interaction. Just as humans use multiple modes to communicate with each other, we follow an approach which is characterized by simultaneously using multiple modalities to achieve natural human-machine interaction for a specific task: pointing to or glancing towards objects inside as well as outside the vehicle for deictic references. By tracking the movements of eye-gaze, head and finger, we design a multimodal fusion architecture using a deep neural network to precisely identify the driver's referencing intent. Additionally, we use a speech command as a trigger to separate each referencing event. We observe differences in driver behavior in the two pointing use cases (i.e. for inside and outside objects), especially when analyzing the preciseness of the three modalities eye, head, and finger. We conclude that there is no single modality that is solely optimal for all cases as each modality reveals certain limitations. Fusion of multiple modalities exploits the relevant characteristics of each modality, hence overcoming the case dependent limitations of each individual modality. Ultimately, we propose a method to identity whether the driver's referenced object lies inside or outside the vehicle, based on the predicted pointing direction.
Multimodal Fusion Using Deep Learning Applied to Driver's Referencing of Outside-Vehicle Objects
Jul 26, 2021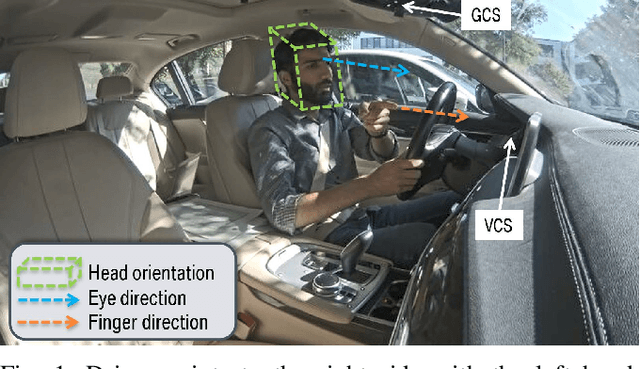
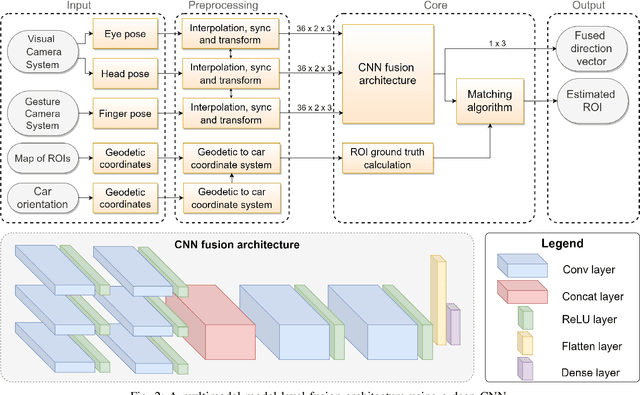
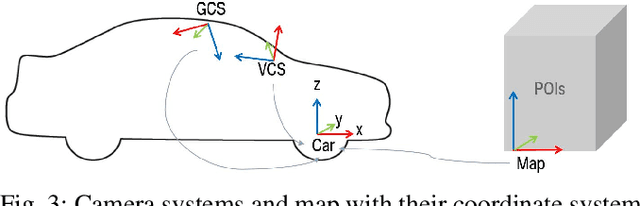

There is a growing interest in more intelligent natural user interaction with the car. Hand gestures and speech are already being applied for driver-car interaction. Moreover, multimodal approaches are also showing promise in the automotive industry. In this paper, we utilize deep learning for a multimodal fusion network for referencing objects outside the vehicle. We use features from gaze, head pose and finger pointing simultaneously to precisely predict the referenced objects in different car poses. We demonstrate the practical limitations of each modality when used for a natural form of referencing, specifically inside the car. As evident from our results, we overcome the modality specific limitations, to a large extent, by the addition of other modalities. This work highlights the importance of multimodal sensing, especially when moving towards natural user interaction. Furthermore, our user based analysis shows noteworthy differences in recognition of user behavior depending upon the vehicle pose.