 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Data Repetition Destroys Language Models
Jun 23, 2026Language models are running out of high-quality training data, and even aggressively deduplicated corpora retain some amount of repetition. Earlier controlled studies predated Chinchilla-style scaling laws and could only measure the cost of repetition indirectly. We revisit repetition in the Chinchilla era, using a fitted no-repetition scaling law to report Compute-Equivalent Gain and Compute-Equivalent Loss. We show that under this modernized paradigm, repetition damage is systematic in three ways. First, holding compute allocated to repeated data constant, eval loss peaks at an intermediate repeat count $\Rep$; repeating a moderately sized subset a moderate number of times damages performance more than repeating a large subset a few times or a small subset many times. Second, the location of this peak is well-fit by a power law in model size; this scaling law reveals that the most damaging number of repeated data grows more quickly than compute. Finally, when repeated documents consume 10\% of the FLOPs budget in a controlled exact-document repetition setting, the compute-equivalent loss can be large: on FineWeb-Edu-Dedup, the most damaging repeat count for a Qwen3-style 344M-parameter model at $\OT=1$ matches the loss of a no-repetition run using 67% of the FLOPs. We demonstrate that these phenomena are not language-model-specific, and can be analytically understood in a simple statistical model: a misspecified linear regression with verbatim duplicates reproduces the same qualitative loss peak, quantifying how such peaks can arise from a statistical tradeoff between memorization and generalization. Our findings add precision to the study of duplication in language models, allowing practitioners to quantify the wasted compute incurred by the presence and repeat structure of duplicates in pretraining corpora.
Statistical Properties of Training & Generalization
Jun 18, 2026Deep learning has managed to evade numerous intuitions from classical statistics to achieve unprecedented performance on a number of real-world tasks. In this article, we investigate the key features and surprises of deep learning from a physics-informed perspective, taking care to point out and justify where possible the many choices inherent in constructing a deep learning model. In particular, we review the phenomenon of neural scaling laws and discuss their interplay with the constraints and inductive biases which may be present when applying machine learning to problems in physics.
Generative models on phase space
Apr 02, 2026Deep generative models such as diffusion and flow matching are powerful machine learning tools capable of learning and sampling from high-dimensional distributions. They are particularly useful when the training data appears to be concentrated on a submanifold of the data embedding space. For high-energy physics data, consisting of collections of relativistic energy-momentum 4-vectors, this submanifold can enforce extremely strong physically-motivated priors, such as energy and momentum conservation. If these constraints are learned only approximately, rather than exactly, this can inhibit the interpretability and reliability of such generative models. To remedy this deficiency, we introduce generative models which are, by construction, confined at every step of their sampling trajectory to the manifold of massless N-particle Lorentz-invariant phase space in the center-of-momentum frame. In the case of diffusion models, the "pure noise" forward process endpoint corresponds to the uniform distribution on phase space, which provides a clear starting point from which to identify how correlations among the particles emerge during the reverse (de-noising) process. We demonstrate that our models are able to learn both few-particle and many-particle distributions with various singularity structures, paving the way for future interpretability studies using generative models trained on simulated jet data.
The Implicit Bias of Logit Regularization
Feb 13, 2026Logit regularization, the addition of a convex penalty directly in logit space, is widely used in modern classifiers, with label smoothing as a prominent example. While such methods often improve calibration and generalization, their mechanism remains under-explored. In this work, we analyze a general class of such logit regularizers in the context of linear classification, and demonstrate that they induce an implicit bias of logit clustering around finite per-sample targets. For Gaussian data, or whenever logits are sufficiently clustered, we prove that logit clustering drives the weight vector to align exactly with Fisher's Linear Discriminant. To demonstrate the consequences, we study a simple signal-plus-noise model in which this transition has dramatic effects: Logit regularization halves the critical sample complexity and induces grokking in the small-noise limit, while making generalization robust to noise. Our results extend the theoretical understanding of label smoothing and highlight the efficacy of a broader class of logit-regularization methods.
More Bang for the Buck: Improving the Inference of Large Language Models at a Fixed Budget using Reset and Discard (ReD)
Jan 29, 2026The performance of large language models (LLMs) on verifiable tasks is usually measured by pass@k, the probability of answering a question correctly at least once in k trials. At a fixed budget, a more suitable metric is coverage@cost, the average number of unique questions answered as a function of the total number of attempts. We connect the two metrics and show that the empirically-observed power-law behavior in pass@k leads to a sublinear growth of the coverage@cost (diminishing returns). To solve this problem, we propose Reset-and-Discard (ReD), a query method of LLMs that increases coverage@cost for any given budget, regardless of the pass@k form. Moreover, given a pass@k, we can quantitatively predict the savings in the total number of attempts using ReD. If pass@k is not available for the model, ReD can infer its power-law exponent. Experiments on three LLMs using HumanEval demonstrate that ReD substantially reduces the required attempts, tokens, and USD cost to reach a desired coverage, while also offering an efficient way to measure inference power-laws.
Learning Shrinks the Hard Tail: Training-Dependent Inference Scaling in a Solvable Linear Model
Jan 07, 2026We analyze neural scaling laws in a solvable model of last-layer fine-tuning where targets have intrinsic, instance-heterogeneous difficulty. In our Latent Instance Difficulty (LID) model, each input's target variance is governed by a latent ``precision'' drawn from a heavy-tailed distribution. While generalization loss recovers standard scaling laws, our main contribution connects this to inference. The pass@$k$ failure rate exhibits a power-law decay, $k^{-β_\text{eff}}$, but the observed exponent $β_\text{eff}$ is training-dependent. It grows with sample size $N$ before saturating at an intrinsic limit $β$ set by the difficulty distribution's tail. This coupling reveals that learning shrinks the ``hard tail'' of the error distribution: improvements in the model's generalization error steepen the pass@$k$ curve until irreducible target variance dominates. The LID model yields testable, closed-form predictions for this behavior, including a compute-allocation rule that favors training before saturation and inference attempts after. We validate these predictions in simulations and in two real-data proxies: CIFAR-10H (human-label variance) and a maths teacher-student distillation task.
A Simple Model of Inference Scaling Laws
Oct 21, 2024



Neural scaling laws have garnered significant interest due to their ability to predict model performance as a function of increasing parameters, data, and compute. In this work, we propose a simple statistical ansatz based on memorization to study scaling laws in the context of inference, specifically how performance improves with multiple inference attempts. We explore the coverage, or pass@k metric, which measures the chance of success over repeated attempts and provide a motivation for the observed functional form of the inference scaling behavior of the coverage in large language models (LLMs) on reasoning tasks. We then define an "inference loss", which exhibits a power law decay as the number of trials increases, and connect this result with prompting costs. We further test our construction by conducting experiments on a simple generative model, and find that our predictions are in agreement with the empirical coverage curves in a controlled setting. Our simple framework sets the ground for incorporating inference scaling with other known scaling laws.
Grokking at the Edge of Linear Separability
Oct 06, 2024



We study the generalization properties of binary logistic classification in a simplified setting, for which a "memorizing" and "generalizing" solution can always be strictly defined, and elucidate empirically and analytically the mechanism underlying Grokking in its dynamics. We analyze the asymptotic long-time dynamics of logistic classification on a random feature model with a constant label and show that it exhibits Grokking, in the sense of delayed generalization and non-monotonic test loss. We find that Grokking is amplified when classification is applied to training sets which are on the verge of linear separability. Even though a perfect generalizing solution always exists, we prove the implicit bias of the logisitc loss will cause the model to overfit if the training data is linearly separable from the origin. For training sets that are not separable from the origin, the model will always generalize perfectly asymptotically, but overfitting may occur at early stages of training. Importantly, in the vicinity of the transition, that is, for training sets that are almost separable from the origin, the model may overfit for arbitrarily long times before generalizing. We gain more insights by examining a tractable one-dimensional toy model that quantitatively captures the key features of the full model. Finally, we highlight intriguing common properties of our findings with recent literature, suggesting that grokking generally occurs in proximity to the interpolation threshold, reminiscent of critical phenomena often observed in physical systems.
Classifying Overlapping Gaussian Mixtures in High Dimensions: From Optimal Classifiers to Neural Nets
May 28, 2024


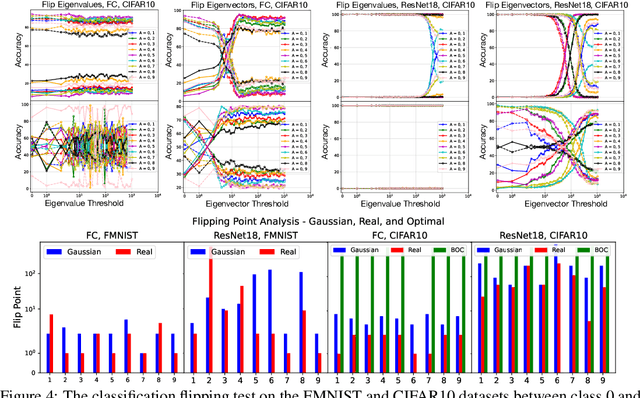
We derive closed-form expressions for the Bayes optimal decision boundaries in binary classification of high dimensional overlapping Gaussian mixture model (GMM) data, and show how they depend on the eigenstructure of the class covariances, for particularly interesting structured data. We empirically demonstrate, through experiments on synthetic GMMs inspired by real-world data, that deep neural networks trained for classification, learn predictors which approximate the derived optimal classifiers. We further extend our study to networks trained on authentic data, observing that decision thresholds correlate with the covariance eigenvectors rather than the eigenvalues, mirroring our GMM analysis. This provides theoretical insights regarding neural networks' ability to perform probabilistic inference and distill statistical patterns from intricate distributions.
Decoupled Weight Decay for Any $p$ Norm
Apr 16, 2024



With the success of deep neural networks (NNs) in a variety of domains, the computational and storage requirements for training and deploying large NNs have become a bottleneck for further improvements. Sparsification has consequently emerged as a leading approach to tackle these issues. In this work, we consider a simple yet effective approach to sparsification, based on the Bridge, or $L_p$ regularization during training. We introduce a novel weight decay scheme, which generalizes the standard $L_2$ weight decay to any $p$ norm. We show that this scheme is compatible with adaptive optimizers, and avoids the gradient divergence associated with $0<p<1$ norms. We empirically demonstrate that it leads to highly sparse networks, while maintaining generalization performance comparable to standard $L_2$ regularization.