 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter and Worse with Scale: How Contextual Entrainment Diverges with Model Size
Apr 14, 2026Larger language models become simultaneously better and worse at handling contextual information -- better at ignoring false claims, worse at ignoring irrelevant tokens. We formalize this apparent paradox through the first scaling laws for contextual entrainment, the tendency of models to favor tokens that appeared in context regardless of relevance. Analyzing the Cerebras-GPT (111M-13B) and Pythia (410M-12B) model families, we find entrainment follows predictable power-law scaling, but with opposite trends depending on context type: semantic contexts show decreasing entrainment with scale, while non-semantic contexts show increasing entrainment. Concretely, the largest models are four times more resistant to counterfactual misinformation than the smallest, yet simultaneously twice as prone to copying arbitrary tokens. These diverging trends, which replicate across model families, suggest that semantic filtering and mechanical copying are functionally distinct behaviors that scale in opposition -- scaling alone does not resolve context sensitivity, it reshapes it.
ReLA: Representation Learning and Aggregation for Job Scheduling with Reinforcement Learning
Jan 08, 2026Job scheduling is widely used in real-world manufacturing systems to assign ordered job operations to machines under various constraints. Existing solutions remain limited by long running time or insufficient schedule quality, especially when problem scale increases. In this paper, we propose ReLA, a reinforcement-learning (RL) scheduler built on structured representation learning and aggregation. ReLA first learns diverse representations from scheduling entities, including job operations and machines, using two intra-entity learning modules with self-attention and convolution and one inter-entity learning module with cross-attention. These modules are applied in a multi-scale architecture, and their outputs are aggregated to support RL decision-making. Across experiments on small, medium, and large job instances, ReLA achieves the best makespan in most tested settings over the latest solutions. On non-large instances, ReLA reduces the optimality gap of the SOTA baseline by 13.0%, while on large-scale instances it reduces the gap by 78.6%, with the average optimality gaps lowered to 7.3% and 2.1%, respectively. These results confirm that ReLA's learned representations and aggregation provide strong decision support for RL scheduling, and enable fast job completion and decision-making for real-world applications.
Feature-based Graph Attention Networks Improve Online Continual Learning
Feb 13, 2025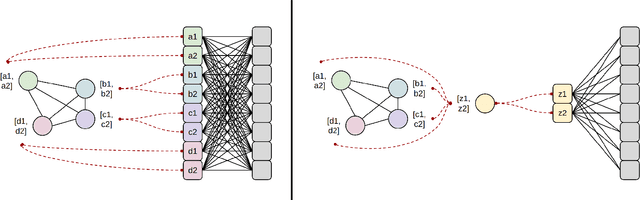
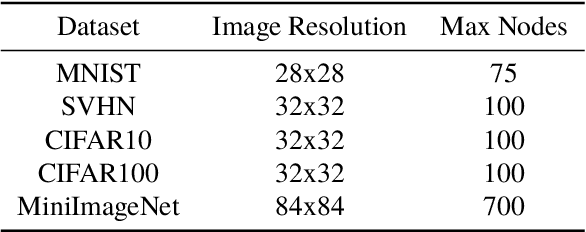
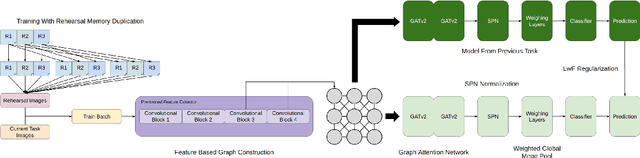

Online continual learning for image classification is crucial for models to adapt to new data while retaining knowledge of previously learned tasks. This capability is essential to address real-world challenges involving dynamic environments and evolving data distributions. Traditional approaches predominantly employ Convolutional Neural Networks, which are limited to processing images as grids and primarily capture local patterns rather than relational information. Although the emergence of transformer architectures has improved the ability to capture relationships, these models often require significantly larger resources. In this paper, we present a novel online continual learning framework based on Graph Attention Networks (GATs), which effectively capture contextual relationships and dynamically update the task-specific representation via learned attention weights. Our approach utilizes a pre-trained feature extractor to convert images into graphs using hierarchical feature maps, representing information at varying levels of granularity. These graphs are then processed by a GAT and incorporate an enhanced global pooling strategy to improve classification performance for continual learning. In addition, we propose the rehearsal memory duplication technique that improves the representation of the previous tasks while maintaining the memory budget. Comprehensive evaluations on benchmark datasets, including SVHN, CIFAR10, CIFAR100, and MiniImageNet, demonstrate the superiority of our method compared to the state-of-the-art methods.
On-Device LLMs for SMEs: Challenges and Opportunities
Oct 21, 2024This paper presents a systematic review of the infrastructure requirements for deploying Large Language Models (LLMs) on-device within the context of small and medium-sized enterprises (SMEs), focusing on both hardware and software perspectives. From the hardware viewpoint, we discuss the utilization of processing units like GPUs and TPUs, efficient memory and storage solutions, and strategies for effective deployment, addressing the challenges of limited computational resources typical in SME settings. From the software perspective, we explore framework compatibility, operating system optimization, and the use of specialized libraries tailored for resource-constrained environments. The review is structured to first identify the unique challenges faced by SMEs in deploying LLMs on-device, followed by an exploration of the opportunities that both hardware innovations and software adaptations offer to overcome these obstacles. Such a structured review provides practical insights, contributing significantly to the community by enhancing the technological resilience of SMEs in integrating LLMs.
Nutrition Estimation for Dietary Management: A Transformer Approach with Depth Sensing
Jun 04, 2024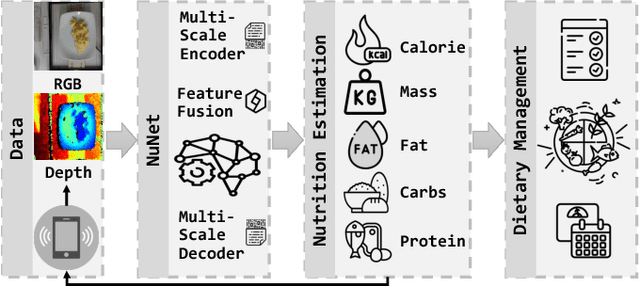
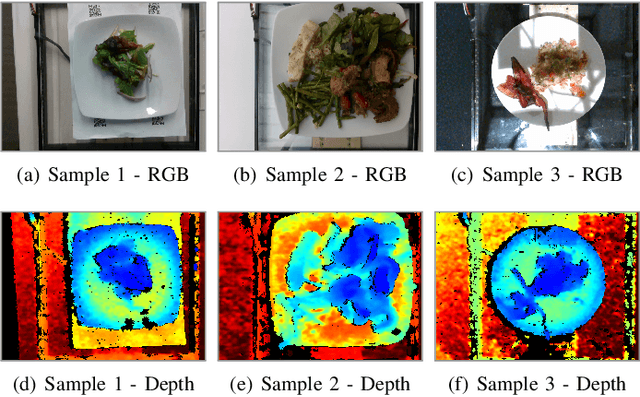
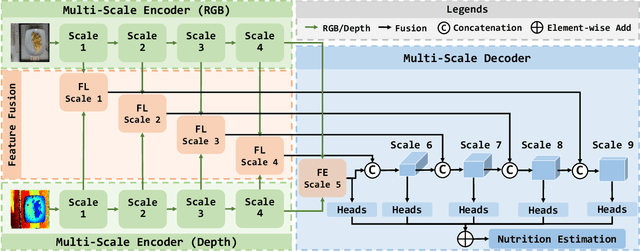
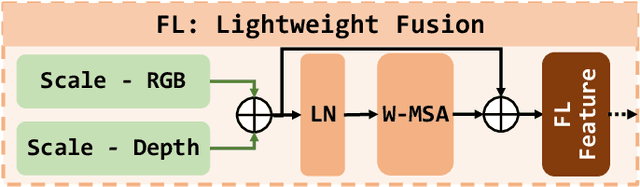
Nutrition estimation is crucial for effective dietary management and overall health and well-being. Existing methods often struggle with sub-optimal accuracy and can be time-consuming. In this paper, we propose NuNet, a transformer-based network designed for nutrition estimation that utilizes both RGB and depth information from food images. We have designed and implemented a multi-scale encoder and decoder, along with two types of feature fusion modules, specialized for estimating five nutritional factors. These modules effectively balance the efficiency and effectiveness of feature extraction with flexible usage of our customized attention mechanisms and fusion strategies. Our experimental study shows that NuNet outperforms its variants and existing solutions significantly for nutrition estimation. It achieves an error rate of 15.65%, the lowest known to us, largely due to our multi-scale architecture and fusion modules. This research holds practical values for dietary management with huge potential for transnational research and deployment and could inspire other applications involving multiple data types with varying degrees of importance.
Towards Coarse and Fine-grained Multi-Graph Multi-Label Learning
Dec 19, 2020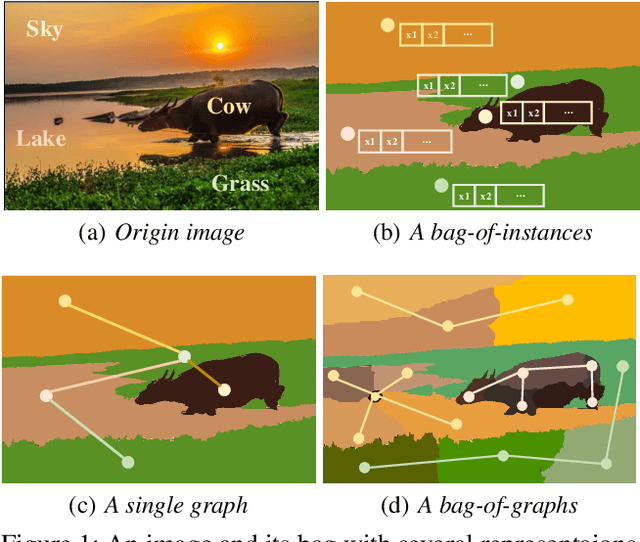

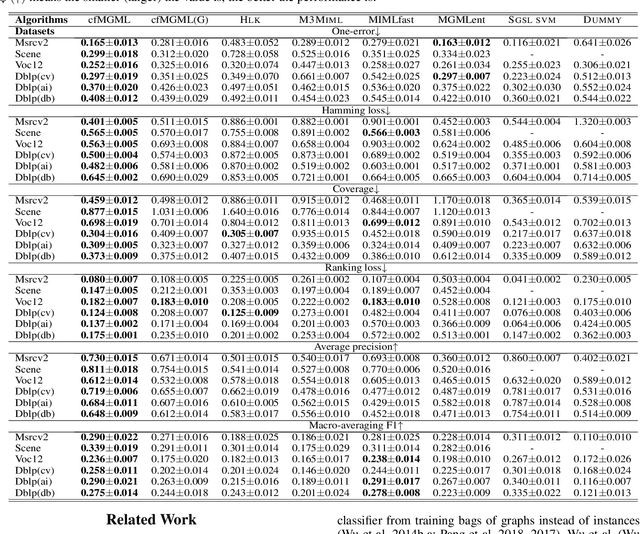
Multi-graph multi-label learning (\textsc{Mgml}) is a supervised learning framework, which aims to learn a multi-label classifier from a set of labeled bags each containing a number of graphs. Prior techniques on the \textsc{Mgml} are developed based on transfering graphs into instances and focus on learning the unseen labels only at the bag level. In this paper, we propose a \textit{coarse} and \textit{fine-grained} Multi-graph Multi-label (cfMGML) learning framework which directly builds the learning model over the graphs and empowers the label prediction at both the \textit{coarse} (aka. bag) level and \textit{fine-grained} (aka. graph in each bag) level. In particular, given a set of labeled multi-graph bags, we design the scoring functions at both graph and bag levels to model the relevance between the label and data using specific graph kernels. Meanwhile, we propose a thresholding rank-loss objective function to rank the labels for the graphs and bags and minimize the hamming-loss simultaneously at one-step, which aims to addresses the error accumulation issue in traditional rank-loss algorithms. To tackle the non-convex optimization problem, we further develop an effective sub-gradient descent algorithm to handle high-dimensional space computation required in cfMGML. Experiments over various real-world datasets demonstrate cfMGML achieves superior performance than the state-of-arts algorithms.
TwiInsight: Discovering Topics and Sentiments from Social Media Datasets
May 23, 2017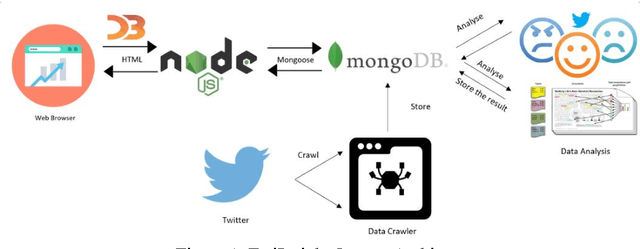



Social media platforms contain a great wealth of information which provides opportunities for us to explore hidden patterns or unknown correlations, and understand people's satisfaction with what they are discussing. As one showcase, in this paper, we present a system, TwiInsight which explores the insight of Twitter data. Different from other Twitter analysis systems, TwiInsight automatically extracts the popular topics under different categories (e.g., healthcare, food, technology, sports and transport) discussed in Twitter via topic modeling and also identifies the correlated topics across different categories. Additionally, it also discovers the people's opinions on the tweets and topics via the sentiment analysis. The system also employs an intuitive and informative visualization to show the uncovered insight. Furthermore, we also develop and compare six most popular algorithms - three for sentiment analysis and three for topic modeling.