 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the generalization of network based relative pose regression: dimension reduction as a regularizer
Paper and Code
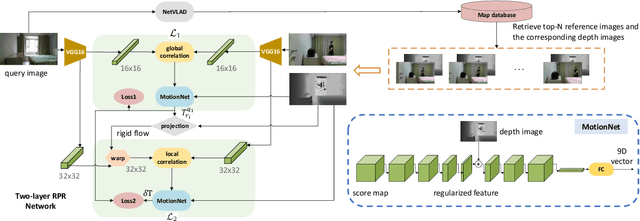
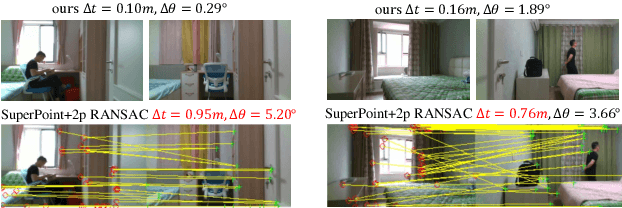
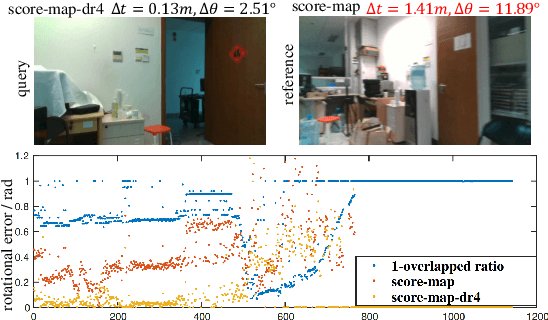

Visual localization occupies an important position in many areas such as Augmented Reality, robotics and 3D reconstruction. The state-of-the-art visual localization methods perform pose estimation using geometry based solver within the RANSAC framework. However, these methods require accurate pixel-level matching at high image resolution, which is hard to satisfy under significant changes from appearance, dynamics or perspective of view. End-to-end learning based regression networks provide a solution to circumvent the requirement for precise pixel-level correspondences, but demonstrate poor performance towards cross-scene generalization. In this paper, we explicitly add a learnable matching layer within the network to isolate the pose regression solver from the absolute image feature values, and apply dimension regularization on both the correlation feature channel and the image scale to further improve performance towards generalization and large viewpoint change. We implement this dimension regularization strategy within a two-layer pyramid based framework to regress the localization results from coarse to fine. In addition, the depth information is fused for absolute translational scale recovery. Through experiments on real world RGBD datasets we validate the effectiveness of our design in terms of improving both generalization performance and robustness towards viewpoint change, and also show the potential of regression based visual localization networks towards challenging occasions that are difficult for geometry based visual localization methods.