 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Retrieval Augmented Language Model with Self-Reasoning
Jul 29, 2024The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
A novel active learning framework for classification: using weighted rank aggregation to achieve multiple query criteria
Sep 27, 2018

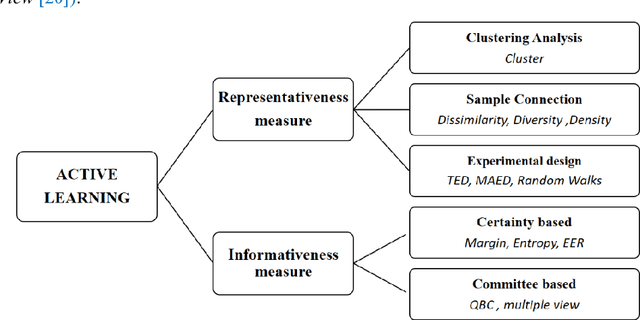
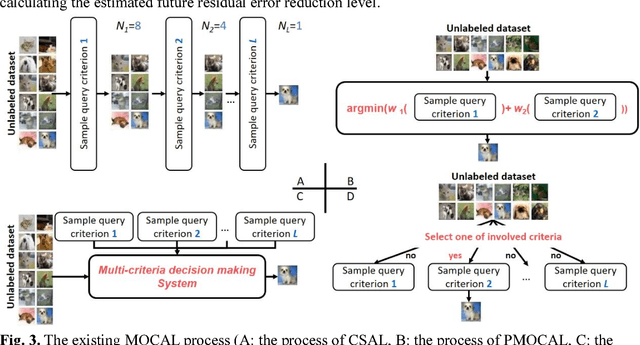
Multiple query criteria active learning (MQCAL) methods have a higher potential performance than conventional active learning methods in which only one criterion is deployed for sample selection. A central issue related to MQCAL methods concerns the development of an integration criteria strategy (ICS) that makes full use of all criteria. The conventional ICS adopted in relevant research all facilitate the desired effects, but several limitations still must be addressed. For instance, some of the strategies are not sufficiently scalable during the design process, and the number and type of criteria involved are dictated. Thus, it is challenging for the user to integrate other criteria into the original process unless modifications are made to the algorithm. Other strategies are too dependent on empirical parameters, which can only be acquired by experience or cross-validation and thus lack generality; additionally, these strategies are counter to the intention of active learning, as samples need to be labeled in the validation set before the active learning process can begin. To address these limitations, we propose a novel MQCAL method for classification tasks that employs a third strategy via weighted rank aggregation. The proposed method serves as a heuristic means to select high-value samples of high scalability and generality and is implemented through a three-step process: (1) the transformation of the sample selection to sample ranking and scoring, (2) the computation of the self-adaptive weights of each criterion, and (3) the weighted aggregation of each sample rank list. Ultimately, the sample at the top of the aggregated ranking list is the most comprehensively valuable and must be labeled. Several experiments generating 257 wins, 194 ties and 49 losses against other state-of-the-art MQCALs are conducted to verify that the proposed method can achieve superior results.