 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepoQA: Evaluating Long Context Code Understanding
Jun 10, 2024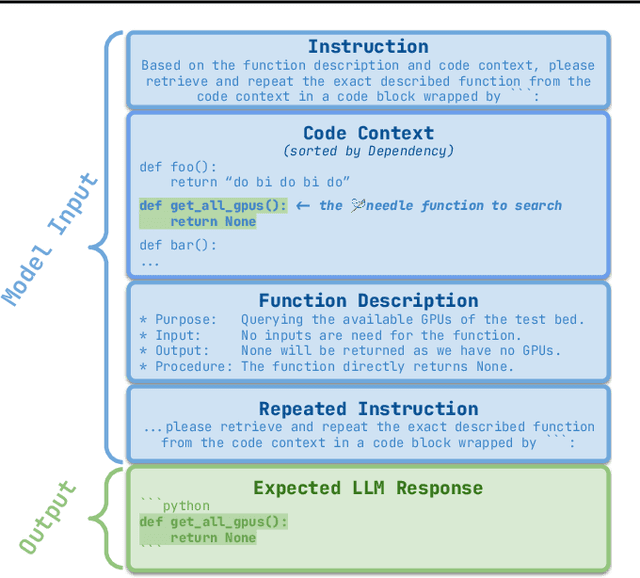
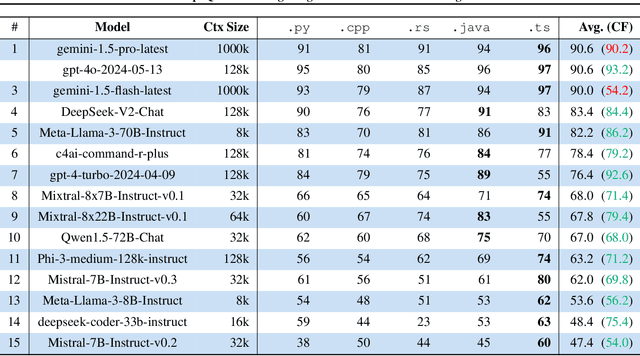
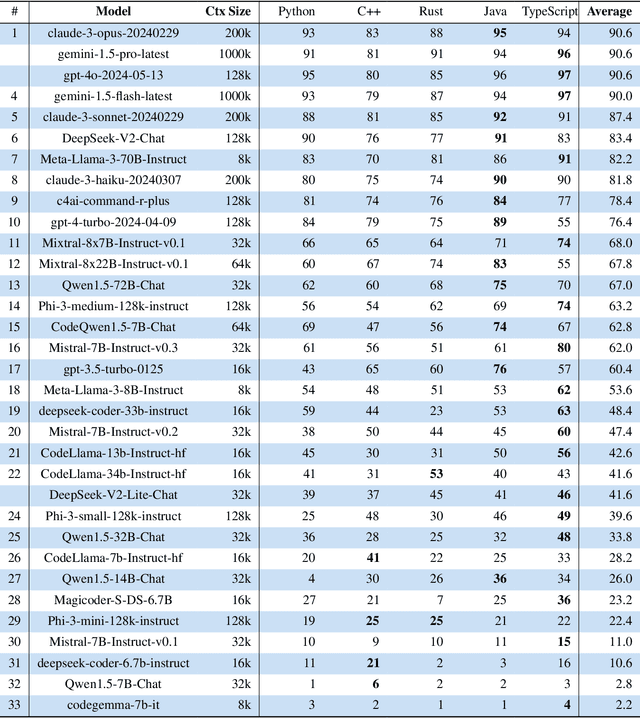
Recent advances have been improving the context windows of Large Language Models (LLMs). To quantify the real long-context capabilities of LLMs, evaluators such as the popular Needle in a Haystack have been developed to test LLMs over a large chunk of raw texts. While effective, current evaluations overlook the insight of how LLMs work with long-context code, i.e., repositories. To this end, we initiate the RepoQA benchmark to evaluate LLMs on long-context code understanding. Traditional needle testers ask LLMs to directly retrieve the answer from the context without necessary deep understanding. In RepoQA, we built our initial task, namely Searching Needle Function (SNF), which exercises LLMs to search functions given their natural-language description, i.e., LLMs cannot find the desired function if they cannot understand the description and code. RepoQA is multilingual and comprehensive: it includes 500 code search tasks gathered from 50 popular repositories across 5 modern programming languages. By evaluating 26 general and code-specific LLMs on RepoQA, we show (i) there is still a small gap between the best open and proprietary models; (ii) different models are good at different languages; and (iii) models may understand code better without comments.