 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying Strategically: Learning to Mask for Closed-book QA
Paper and Code
Jan 01, 2021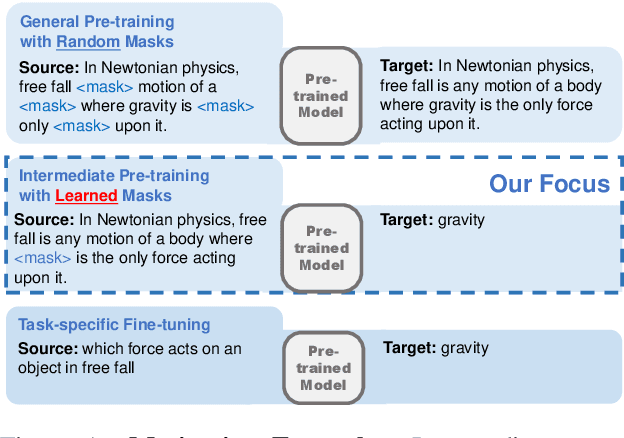
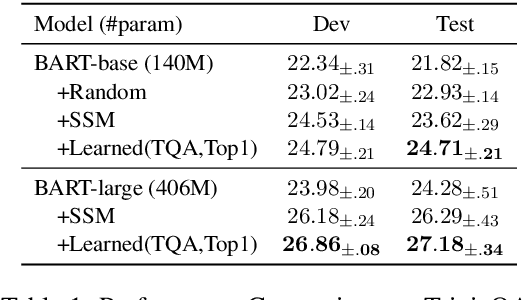
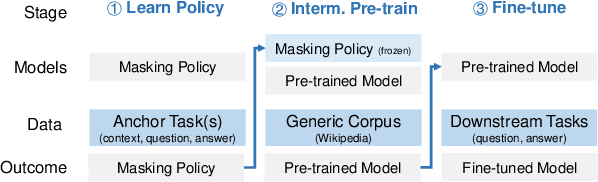

Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pre-training stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.