 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023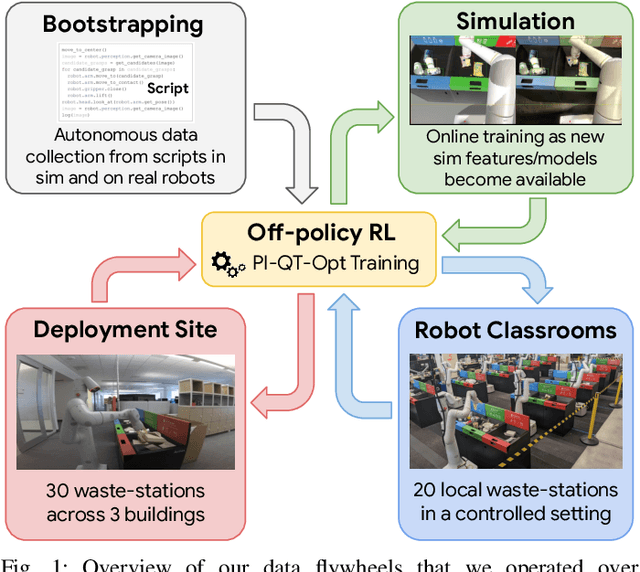


We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Action Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

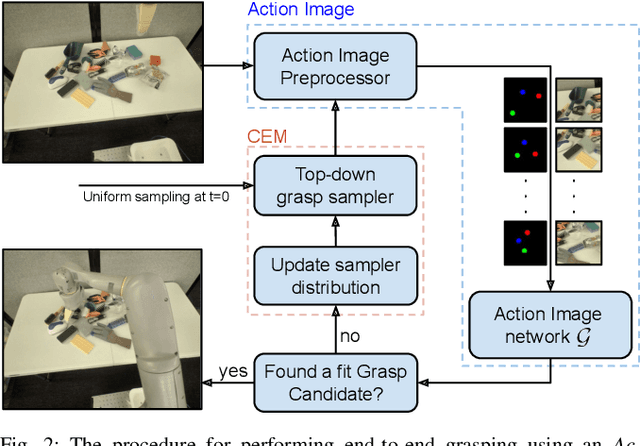
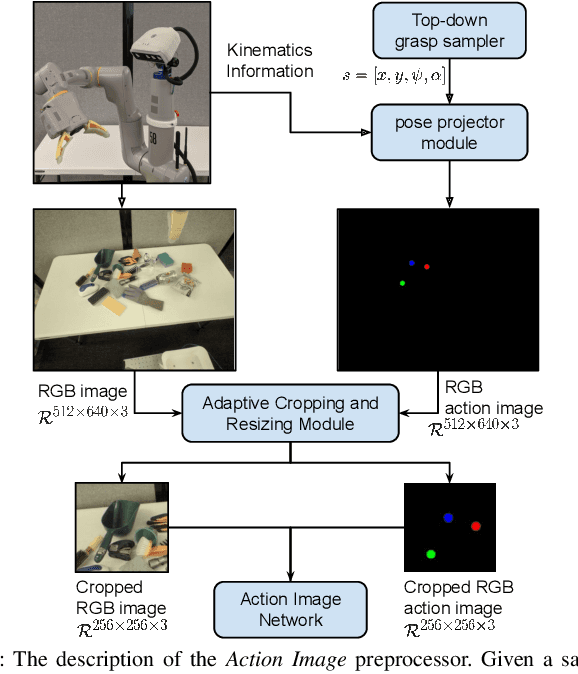
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.