 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Navigation Among Humans with Optimal Control as a Supervisor
Mar 20, 2020
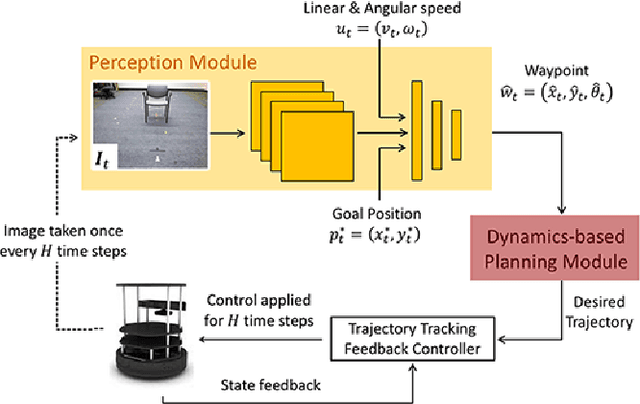
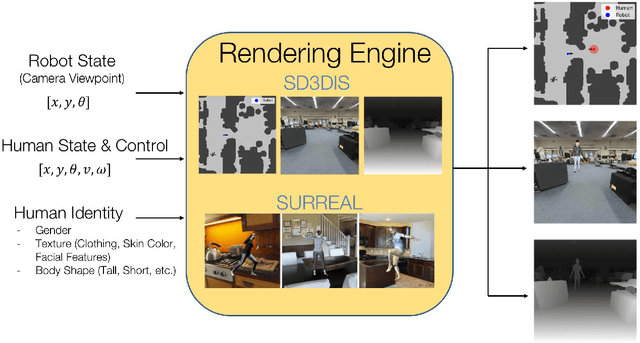

Real world navigation requires robots to operate in unfamiliar, dynamic environments, sharing spaces with humans. Navigating around humans is especially difficult because it requires predicting their future motion, which can be quite challenging. We propose a novel framework for navigation around humans which combines learning-based perception with model-based optimal control. Specifically, we train a Convolutional Neural Network (CNN)-based perception module which maps the robot's visual inputs to a waypoint, or next desired state. This waypoint is then input into planning and control modules which convey the robot safely and efficiently to the goal. To train the CNN we contribute a photo-realistic bench-marking dataset for autonomous robot navigation in the presence of humans. The CNN is trained using supervised learning on images rendered from our photo-realistic dataset. The proposed framework learns to anticipate and react to peoples' motion based only on a monocular RGB image, without explicitly predicting future human motion. Our method generalizes well to unseen buildings and humans in both simulation and real world environments. Furthermore, our experiments demonstrate that combining model-based control and learning leads to better and more data-efficient navigational behaviors as compared to a purely learning based approach. Videos describing our approach and experiments are available on the project website.
Generating Robust Supervision for Learning-Based Visual Navigation Using Hamilton-Jacobi Reachability
Dec 20, 2019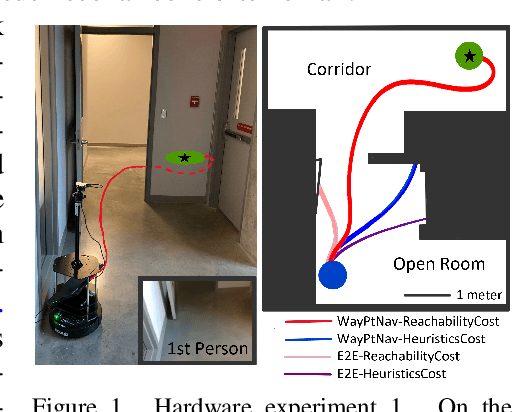

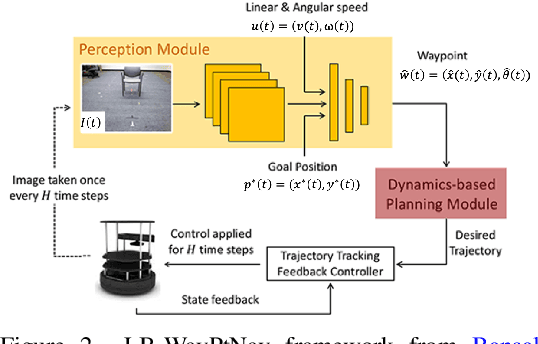
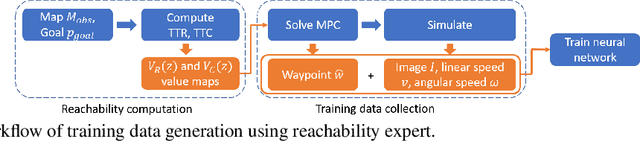
In Bansal et al. (2019), a novel visual navigation framework that combines learning-based and model-based approaches has been proposed. Specifically, a Convolutional Neural Network (CNN) predicts a waypoint that is used by the dynamics model for planning and tracking a trajectory to the waypoint. However, the CNN inevitably makes prediction errors, ultimately leading to collisions, especially when the robot is navigating through cluttered and tight spaces. In this paper, we present a novel Hamilton-Jacobi (HJ) reachability-based method to generate supervision for the CNN for waypoint prediction. By modeling the prediction error of the CNN as disturbances in dynamics, the proposed method generates waypoints that are robust to these disturbances, and consequently to the prediction errors. Moreover, using globally optimal HJ reachability analysis leads to predicting waypoints that are time-efficient and do not exhibit greedy behavior. Through simulations and experiments on a hardware testbed, we demonstrate the advantages of the proposed approach for navigation tasks where the robot needs to navigate through cluttered, narrow indoor environments.
An Efficient Reachability-Based Framework for Provably Safe Autonomous Navigation in Unknown Environments
May 01, 2019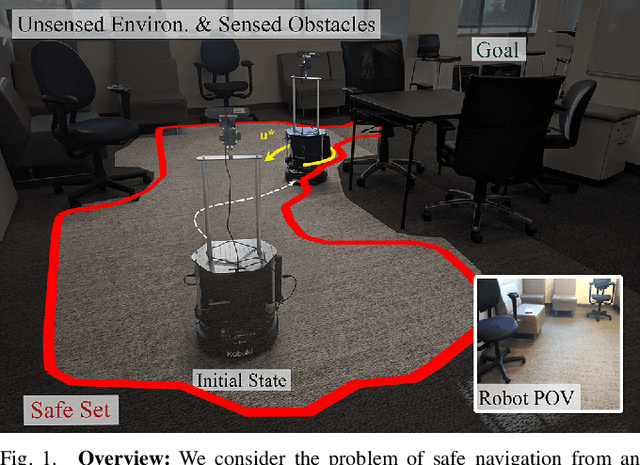
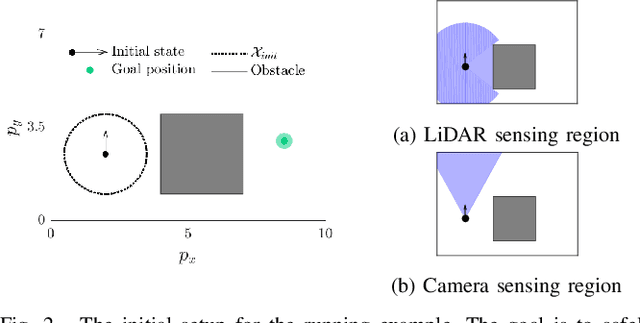
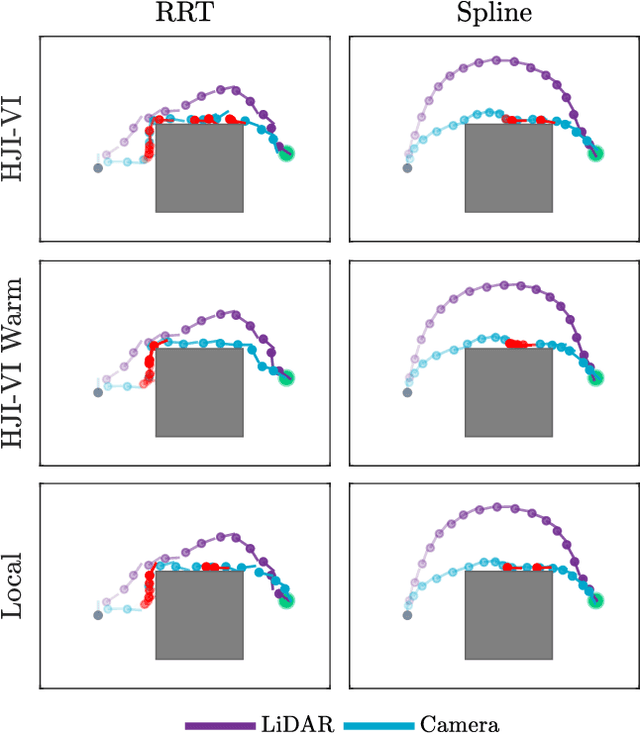
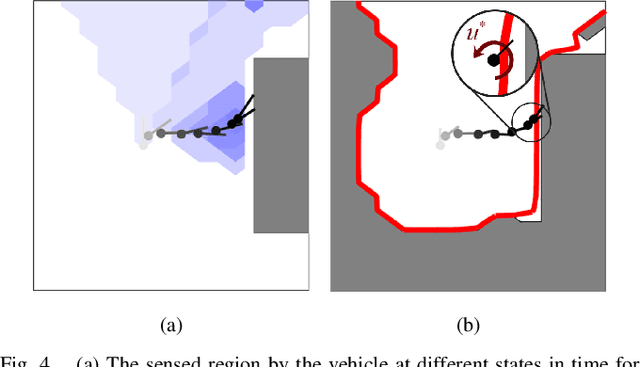
Real-world autonomous vehicles often operate in a priori unknown environments. Since most of these systems are safety-critical, it is important to ensure they operate safely in the face of environment uncertainty, such as unseen obstacles. Current safety analysis tools enable autonomous systems to reason about safety given full information about the state of the environment a priori. However, these tools do not scale well to scenarios where the environment is being sensed in real time, such as during navigation tasks. In this work, we propose a novel, real-time safety analysis method based on Hamilton-Jacobi reachability that provides strong safety guarantees despite environment uncertainty. Our safety method is planner-agnostic and provides guarantees for a variety of mapping sensors. We demonstrate our approach in simulation and in hardware to provide safety guarantees around a state-of-the-art vision-based, learning-based planner.
Combining Optimal Control and Learning for Visual Navigation in Novel Environments
Mar 06, 2019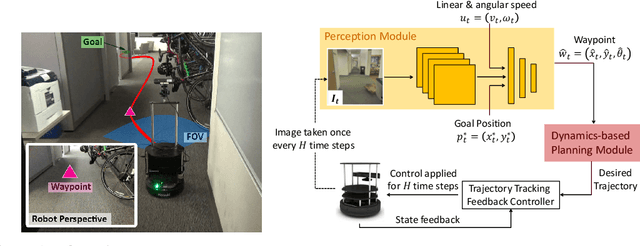


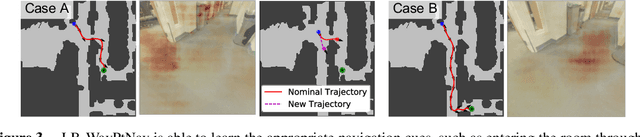
Model-based control is a popular paradigm for robot navigation because it can leverage a known dynamics model to efficiently plan robust robot trajectories. However, it is challenging to use model-based methods in settings where the environment is a priori unknown and can only be observed partially through on-board sensors on the robot. In this work, we address this short-coming by coupling model-based control with learning-based perception. The learning-based perception module produces a series of waypoints that guide the robot to the goal via a collision-free path. These waypoints are used by a model-based planner to generate a smooth and dynamically feasible trajectory that is executed on the physical system using feedback control. Our experiments in simulated real-world cluttered environments and on an actual ground vehicle demonstrate that the proposed approach can reach goal locations more reliably and efficiently in novel, previously-unknown environments as compared to a purely end-to-end learning-based alternative. Our approach is successfully able to exhibit goal-driven behavior without relying on detailed explicit 3D maps of the environment, works well with low frame rates, and generalizes well from simulation to the real world. Videos describing our approach and experiments are available on the project website.
Cognitive Mapping and Planning for Visual Navigation
Feb 07, 2019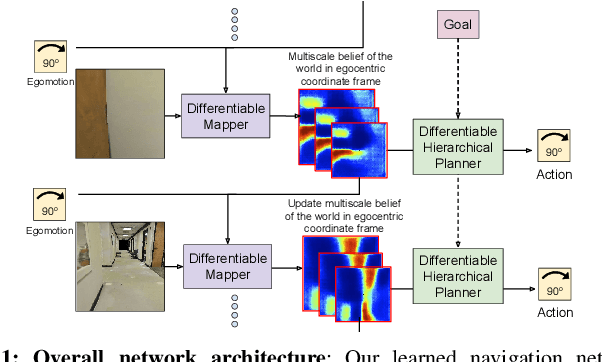
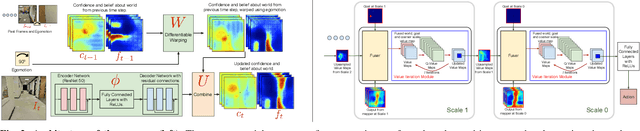
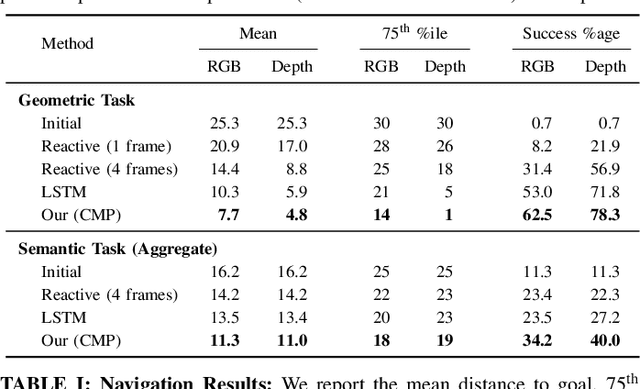
We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.