 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Thought Machines
May 08, 2025



Biological brains demonstrate complex neural activity, where the timing and interplay between neurons is critical to how brains process information. Most deep learning architectures simplify neural activity by abstracting away temporal dynamics. In this paper we challenge that paradigm. By incorporating neuron-level processing and synchronization, we can effectively reintroduce neural timing as a foundational element. We present the Continuous Thought Machine (CTM), a model designed to leverage neural dynamics as its core representation. The CTM has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique weight parameters to process a history of incoming signals; and (2) neural synchronization employed as a latent representation. The CTM aims to strike a balance between oversimplified neuron abstractions that improve computational efficiency, and biological realism. It operates at a level of abstraction that effectively captures essential temporal dynamics while remaining computationally tractable for deep learning. We demonstrate the CTM's strong performance and versatility across a range of challenging tasks, including ImageNet-1K classification, solving 2D mazes, sorting, parity computation, question-answering, and RL tasks. Beyond displaying rich internal representations and offering a natural avenue for interpretation owing to its internal process, the CTM is able to perform tasks that require complex sequential reasoning. The CTM can also leverage adaptive compute, where it can stop earlier for simpler tasks, or keep computing when faced with more challenging instances. The goal of this work is to share the CTM and its associated innovations, rather than pushing for new state-of-the-art results. To that end, we believe the CTM represents a significant step toward developing more biologically plausible and powerful artificial intelligence systems.
Problem-Solving in Language Model Networks
Jun 18, 2024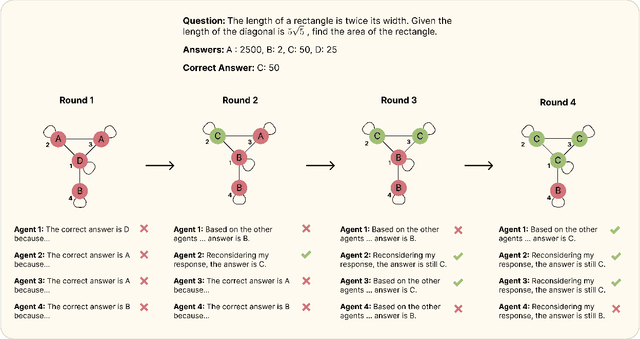
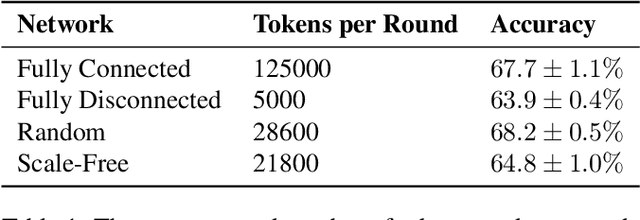
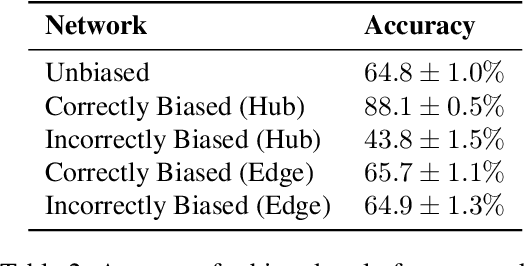

To improve the reasoning and question-answering capabilities of Large Language Models (LLMs), several multi-agent approaches have been introduced. While these methods enhance performance, the application of collective intelligence-based approaches to complex network structures and the dynamics of agent interactions remain underexplored. This work extends the concept of multi-agent debate to more general network topologies, measuring the question-answering accuracy, influence, consensus, and the effects of bias on the collective. The results show that random networks perform similarly to fully connected networks despite using significantly fewer tokens. Furthermore, a strong consensus among agents in correlates with correct answers, whereas divided responses typically indicate incorrect answers. Analysing the influence of the agents reveals a balance between self-reflection and interconnectedness; self-reflection aids when local interactions are incorrect, and local interactions aid when the agent itself is incorrect. Additionally, bias plays a strong role in system performance with correctly biased hub nodes boosting performance. These insights suggest that using random networks or scale-free networks with knowledgeable agents placed in central positions can enhance the overall performance of multi-agent systems.
LLM-POET: Evolving Complex Environments using Large Language Models
Jun 07, 2024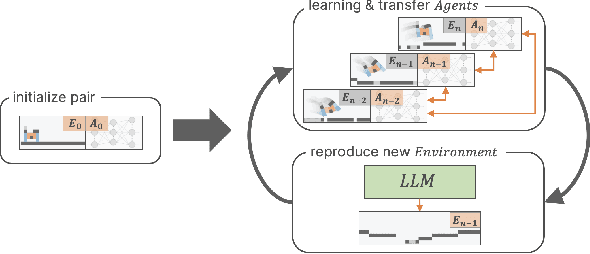
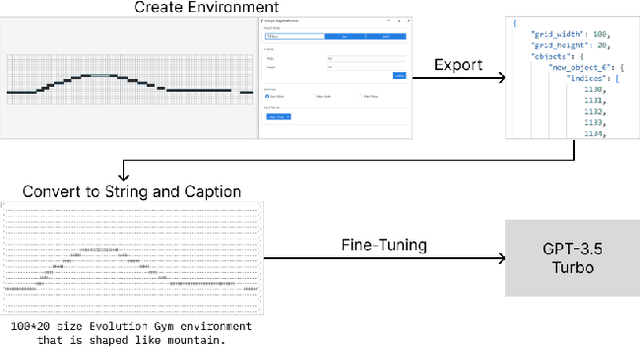
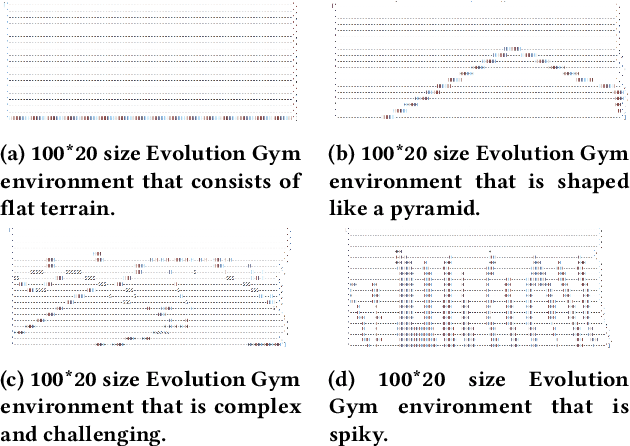
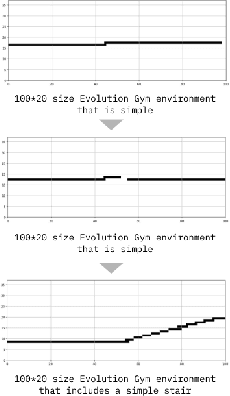
Creating systems capable of generating virtually infinite variations of complex and novel behaviour without predetermined goals or limits is a major challenge in the field of AI. This challenge has been addressed through the development of several open-ended algorithms that can continuously generate new and diverse behaviours, such as the POET and Enhanced-POET algorithms for co-evolving environments and agent behaviour. One of the challenges with existing methods however, is that they struggle to continuously generate complex environments. In this work, we propose LLM-POET, a modification of the POET algorithm where the environment is both created and mutated using a Large Language Model (LLM). By fine-tuning a LLM with text representations of Evolution Gym environments and captions that describe the environment, we were able to generate complex and diverse environments using natural language. We found that not only could the LLM produce a diverse range of environments, but compared to the CPPNs used in Enhanced-POET for environment generation, the LLM allowed for a 34% increase in the performance gain of co-evolution. This increased performance suggests that the agents were able to learn a more diverse set of skills by training on more complex environments.
Can Generative Agents Predict Emotion?
Feb 07, 2024
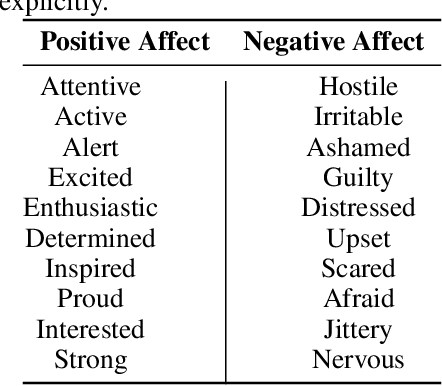


Large Language Models (LLMs) have demonstrated a number of human-like abilities, however the empathic understanding and emotional state of LLMs is yet to be aligned to that of humans. In this work, we investigate how the emotional state of generative LLM agents evolves as they perceive new events, introducing a novel architecture in which new experiences are compared to past memories. Through this comparison, the agent gains the ability to understand new experiences in context, which according to the appraisal theory of emotion is vital in emotion creation. First, the agent perceives new experiences as time series text data. After perceiving each new input, the agent generates a summary of past relevant memories, referred to as the norm, and compares the new experience to this norm. Through this comparison we can analyse how the agent reacts to the new experience in context. The PANAS, a test of affect, is administered to the agent, capturing the emotional state of the agent after the perception of the new event. Finally, the new experience is then added to the agents memory to be used in the creation of future norms. By creating multiple experiences in natural language from emotionally charged situations, we test the proposed architecture on a wide range of scenarios. The mixed results suggests that introducing context can occasionally improve the emotional alignment of the agent, but further study and comparison with human evaluators is necessary. We hope that this paper is another step towards the alignment of generative agents.