 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblem-Solving in Language Model Networks
Paper and Code
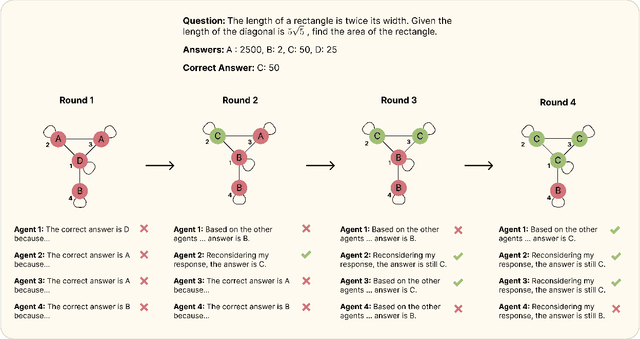
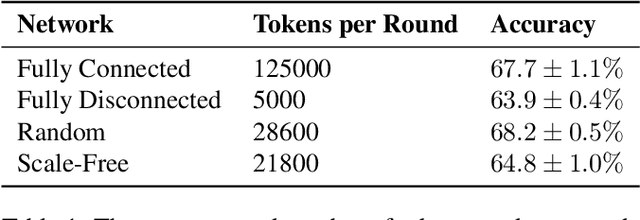
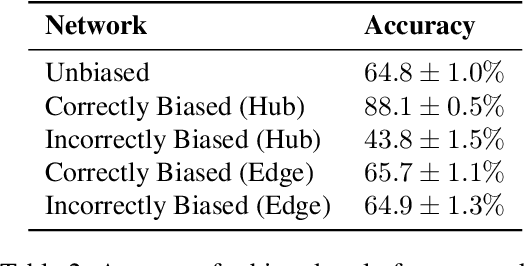

To improve the reasoning and question-answering capabilities of Large Language Models (LLMs), several multi-agent approaches have been introduced. While these methods enhance performance, the application of collective intelligence-based approaches to complex network structures and the dynamics of agent interactions remain underexplored. This work extends the concept of multi-agent debate to more general network topologies, measuring the question-answering accuracy, influence, consensus, and the effects of bias on the collective. The results show that random networks perform similarly to fully connected networks despite using significantly fewer tokens. Furthermore, a strong consensus among agents in correlates with correct answers, whereas divided responses typically indicate incorrect answers. Analysing the influence of the agents reveals a balance between self-reflection and interconnectedness; self-reflection aids when local interactions are incorrect, and local interactions aid when the agent itself is incorrect. Additionally, bias plays a strong role in system performance with correctly biased hub nodes boosting performance. These insights suggest that using random networks or scale-free networks with knowledgeable agents placed in central positions can enhance the overall performance of multi-agent systems.