 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation framework for Image Segmentation Algorithms
Apr 06, 2025This paper presents a comprehensive evaluation framework for image segmentation algorithms, encompassing naive methods, machine learning approaches, and deep learning techniques. We begin by introducing the fundamental concepts and importance of image segmentation, and the role of interactive segmentation in enhancing accuracy. A detailed background theory section explores various segmentation methods, including thresholding, edge detection, region growing, feature extraction, random forests, support vector machines, convolutional neural networks, U-Net, and Mask R-CNN. The implementation and experimental setup are thoroughly described, highlighting three primary approaches: algorithm assisting user, user assisting algorithm, and hybrid methods. Evaluation metrics such as Intersection over Union (IoU), computation time, and user interaction time are employed to measure performance. A comparative analysis presents detailed results, emphasizing the strengths, limitations, and trade-offs of each method. The paper concludes with insights into the practical applicability of these approaches across various scenarios and outlines future work, focusing on expanding datasets, developing more representative approaches, integrating real-time feedback, and exploring weakly supervised and self-supervised learning paradigms to enhance segmentation accuracy and efficiency. Keywords: Image Segmentation, Interactive Segmentation, Machine Learning, Deep Learning, Computer Vision
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.
Linguistic Typology Features from Text: Inferring the Sparse Features of World Atlas of Language Structures
May 04, 2020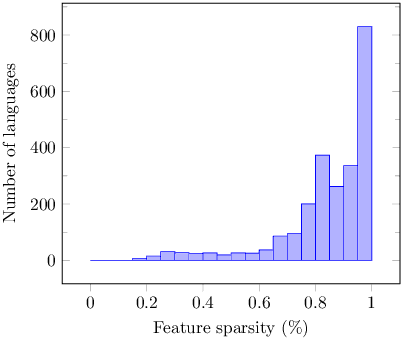
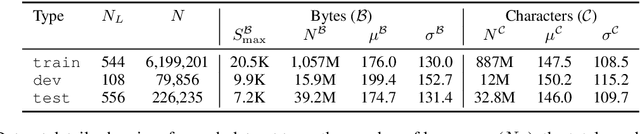
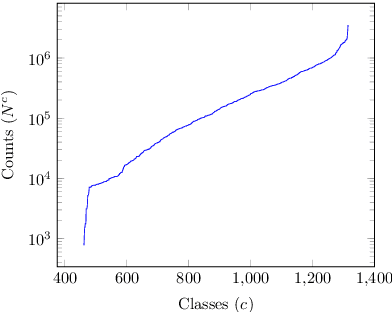
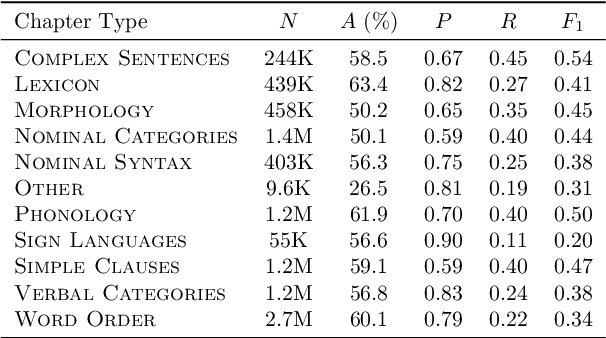
The use of linguistic typological resources in natural language processing has been steadily gaining more popularity. It has been observed that the use of typological information, often combined with distributed language representations, leads to significantly more powerful models. While linguistic typology representations from various resources have mostly been used for conditioning the models, there has been relatively little attention on predicting features from these resources from the input data. In this paper we investigate whether the various linguistic features from World Atlas of Language Structures (WALS) can be reliably inferred from multi-lingual text. Such a predictor can be used to infer structural features for a language never observed in training data. We frame this task as a multi-label classification involving predicting the set of non-mutually exclusive and extremely sparse multi-valued labels (WALS features). We construct a recurrent neural network predictor based on byte embeddings and convolutional layers and test its performance on 556 languages, providing analysis for various linguistic types, macro-areas, language families and individual features. We show that some features from various linguistic types can be predicted reliably.