 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Formation and Dynamics Among Multi-LLMs
Feb 16, 2024Social networks influence behaviors, preferences, and relationships and play a crucial role in the dissemination of information and norms within human societies. As large language models (LLMs) increasingly integrate into social and professional environments, understanding their behavior within the context of social networks and interactions becomes essential. Our study analyzes the behaviors of standard network structures and real-world networks to determine whether the dynamics of multiple LLMs align with human social dynamics. We explore various social network principles, including micro-level concepts such as preferential attachment, triadic closure, and homophily, as well as macro-level concepts like community structure and the small-world phenomenon. Our findings suggest that LLMs demonstrate all these principles when they are provided with network structures and asked about their preferences regarding network formation. Furthermore, we investigate LLMs' decision-making based on real-world networks to compare the strengths of these principles. Our results reveal that triadic closure and homophily have a stronger influence than preferential attachment and that LLMs substantially exceed random guessing in the task of network formation predictions. Overall, our study contributes to the development of socially aware LLMs by shedding light on LLMs' network formation behaviors and exploring their impacts on social dynamics and norms.
Group Decision-Making among Privacy-Aware Agents
Feb 15, 2024How can individuals exchange information to learn from each other despite their privacy needs and security concerns? For example, consider individuals deliberating a contentious topic and being concerned about divulging their private experiences. Preserving individual privacy and enabling efficient social learning are both important desiderata but seem fundamentally at odds with each other and very hard to reconcile. We do so by controlling information leakage using rigorous statistical guarantees that are based on differential privacy (DP). Our agents use log-linear rules to update their beliefs after communicating with their neighbors. Adding DP randomization noise to beliefs provides communicating agents with plausible deniability with regard to their private information and their network neighborhoods. We consider two learning environments one for distributed maximum-likelihood estimation given a finite number of private signals and another for online learning from an infinite, intermittent signal stream. Noisy information aggregation in the finite case leads to interesting tradeoffs between rejecting low-quality states and making sure all high-quality states are accepted in the algorithm output. Our results flesh out the nature of the trade-offs in both cases between the quality of the group decision outcomes, learning accuracy, communication cost, and the level of privacy protections that the agents are afforded.
Leveraging Large Language Models for Collective Decision-Making
Nov 03, 2023



In various work contexts, such as meeting scheduling, collaborating, and project planning, collective decision-making is essential but often challenging due to diverse individual preferences, varying work focuses, and power dynamics among members. To address this, we propose a system leveraging Large Language Models (LLMs) to facilitate group decision-making by managing conversations and balancing preferences among individuals. Our system extracts individual preferences and suggests options that satisfy a significant portion of the members. We apply this system to corporate meeting scheduling. We create synthetic employee profiles and simulate conversations at scale, leveraging LLMs to evaluate the system. Our results indicate efficient coordination with reduced interactions between members and the LLM-based system. The system also effectively refines proposed options over time, ensuring their quality and equity. Finally, we conduct a survey study involving human participants to assess our system's ability to aggregate preferences and reasoning. Our findings show that the system exhibits strong performance in both dimensions.
Differentially Private Distributed Estimation and Learning
Jun 28, 2023We study distributed estimation and learning problems in a networked environment in which agents exchange information to estimate unknown statistical properties of random variables from their privately observed samples. By exchanging information about their private observations, the agents can collectively estimate the unknown quantities, but they also face privacy risks. The goal of our aggregation schemes is to combine the observed data efficiently over time and across the network, while accommodating the privacy needs of the agents and without any coordination beyond their local neighborhoods. Our algorithms enable the participating agents to estimate a complete sufficient statistic from private signals that are acquired offline or online over time, and to preserve the privacy of their signals and network neighborhoods. This is achieved through linear aggregation schemes with adjusted randomization schemes that add noise to the exchanged estimates subject to differential privacy (DP) constraints. In every case, we demonstrate the efficiency of our algorithms by proving convergence to the estimators of a hypothetical, omniscient observer that has central access to all of the signals. We also provide convergence rate analysis and finite-time performance guarantees and show that the noise that minimizes the convergence time to the best estimates is the Laplace noise, with parameters corresponding to each agent's sensitivity to their signal and network characteristics. Finally, to supplement and validate our theoretical results, we run experiments on real-world data from the US Power Grid Network and electric consumption data from German Households to estimate the average power consumption of power stations and households under all privacy regimes.
GLINKX: A Scalable Unified Framework For Homophilous and Heterophilous Graphs
Nov 19, 2022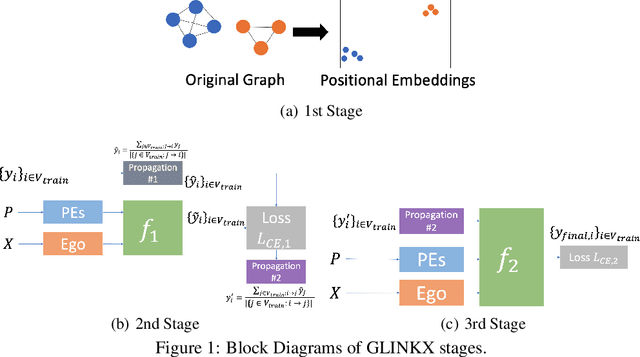



In graph learning, there have been two predominant inductive biases regarding graph-inspired architectures: On the one hand, higher-order interactions and message passing work well on homophilous graphs and are leveraged by GCNs and GATs. Such architectures, however, cannot easily scale to large real-world graphs. On the other hand, shallow (or node-level) models using ego features and adjacency embeddings work well in heterophilous graphs. In this work, we propose a novel scalable shallow method -- GLINKX -- that can work both on homophilous and heterophilous graphs. GLINKX leverages (i) novel monophilous label propagations, (ii) ego/node features, (iii) knowledge graph embeddings as positional embeddings, (iv) node-level training, and (v) low-dimensional message passing. Formally, we prove novel error bounds and justify the components of GLINKX. Experimentally, we show its effectiveness on several homophilous and heterophilous datasets.
Core-periphery Models for Hypergraphs
Jun 01, 2022


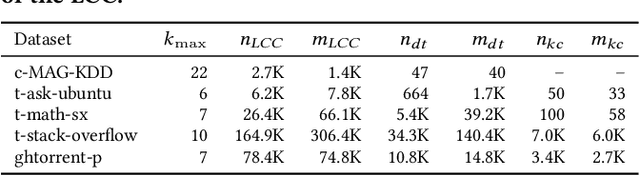
We introduce a random hypergraph model for core-periphery structure. By leveraging our model's sufficient statistics, we develop a novel statistical inference algorithm that is able to scale to large hypergraphs with runtime that is practically linear wrt. the number of nodes in the graph after a preprocessing step that is almost linear in the number of hyperedges, as well as a scalable sampling algorithm. Our inference algorithm is capable of learning embeddings that correspond to the reputation (rank) of a node within the hypergraph. We also give theoretical bounds on the size of the core of hypergraphs generated by our model. We experiment with hypergraph data that range to $\sim 10^5$ hyperedges mined from the Microsoft Academic Graph, Stack Exchange, and GitHub and show that our model outperforms baselines wrt. producing good fits.
Truncated Log-concave Sampling with Reflective Hamiltonian Monte Carlo
Feb 25, 2021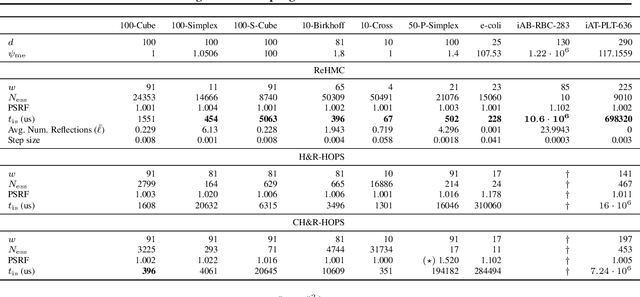
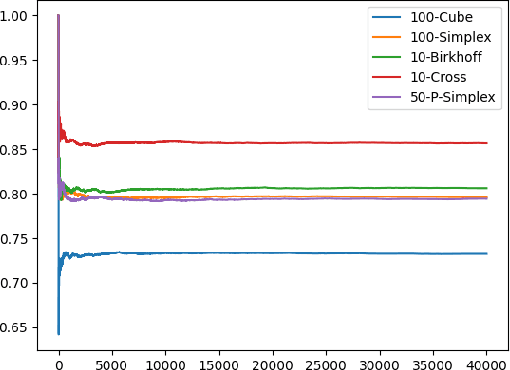
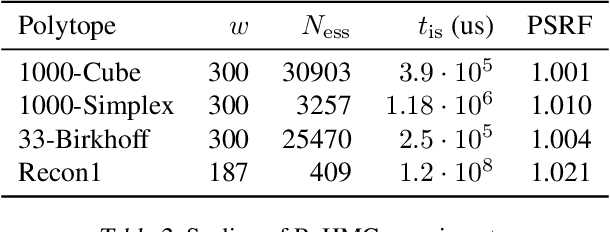
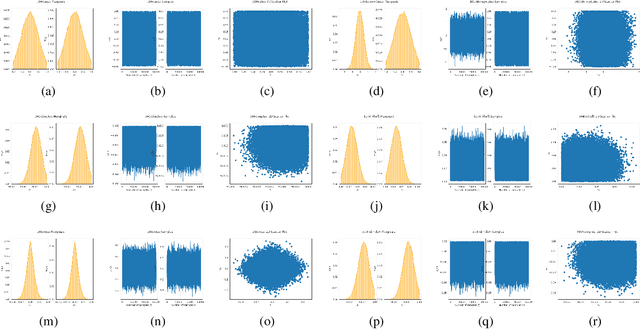
We introduce Reflective Hamiltonian Monte Carlo (ReHMC), an HMC-based algorithm, to sample from a log-concave distribution restricted to a convex polytope. We prove that, starting from a warm start, it mixes in $\widetilde O(\kappa d^2 \ell^2 \log (1 / \varepsilon))$ steps for a well-rounded polytope, ignoring logarithmic factors where $\kappa$ is the condition number of the negative log-density, $d$ is the dimension, $\ell$ is an upper bound on the number of reflections, and $\varepsilon$ is the accuracy parameter. We also developed an open source implementation of ReHMC and we performed an experimental study on various high-dimensional data-sets. Experiments suggest that ReHMC outperfroms Hit-and-Run and Coordinate-Hit-and-Run regarding the time it needs to produce an independent sample.