 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Global Multimodal Contrastive Learning for Molecular Property Prediction
Jan 30, 2026Accurate molecular property prediction requires integrating complementary information from molecular structure and chemical semantics. In this work, we propose LGM-CL, a local-global multimodal contrastive learning framework that jointly models molecular graphs and textual representations derived from SMILES and chemistry-aware augmented texts. Local functional group information and global molecular topology are captured using AttentiveFP and Graph Transformer encoders, respectively, and aligned through self-supervised contrastive learning. In addition, chemically enriched textual descriptions are contrasted with original SMILES to incorporate physicochemical semantics in a task-agnostic manner. During fine-tuning, molecular fingerprints are further integrated via Dual Cross-attention multimodal fusion. Extensive experiments on MoleculeNet benchmarks demonstrate that LGM-CL achieves consistent and competitive performance across both classification and regression tasks, validating the effectiveness of unified local-global and multimodal representation learning.
DBGSA: A Novel Data Adaptive Bregman Clustering Algorithm
Jul 25, 2023With the development of Big data technology, data analysis has become increasingly important. Traditional clustering algorithms such as K-means are highly sensitive to the initial centroid selection and perform poorly on non-convex datasets. In this paper, we address these problems by proposing a data-driven Bregman divergence parameter optimization clustering algorithm (DBGSA), which combines the Universal Gravitational Algorithm to bring similar points closer in the dataset. We construct a gravitational coefficient equation with a special property that gradually reduces the influence factor as the iteration progresses. Furthermore, we introduce the Bregman divergence generalized power mean information loss minimization to identify cluster centers and build a hyperparameter identification optimization model, which effectively solves the problems of manual adjustment and uncertainty in the improved dataset. Extensive experiments are conducted on four simulated datasets and six real datasets. The results demonstrate that DBGSA significantly improves the accuracy of various clustering algorithms by an average of 63.8\% compared to other similar approaches like enhanced clustering algorithms and improved datasets. Additionally, a three-dimensional grid search was established to compare the effects of different parameter values within threshold conditions, and it was discovered the parameter set provided by our model is optimal. This finding provides strong evidence of the high accuracy and robustness of the algorithm.
A rule-general abductive learning by rough sets
May 31, 2023In real-world tasks, there is usually a large amount of unlabeled data and labeled data. The task of combining the two to learn is known as semi-supervised learning. Experts can use logical rules to label unlabeled data, but this operation is costly. The combination of perception and reasoning has a good effect in processing such semi-supervised tasks with domain knowledge. However, acquiring domain knowledge and the correction, reduction and generation of rules remain complex problems to be solved. Rough set theory is an important method for solving knowledge processing in information systems. In this paper, we propose a rule general abductive learning by rough set (RS-ABL). By transforming the target concept and sub-concepts of rules into information tables, rough set theory is used to solve the acquisition of domain knowledge and the correction, reduction and generation of rules at a lower cost. This framework can also generate more extensive negative rules to enhance the breadth of the knowledge base. Compared with the traditional semi-supervised learning method, RS-ABL has higher accuracy in dealing with semi-supervised tasks.
A Matrix Decomposition Model Based on Feature Factors in Movie Recommendation System
Jun 12, 2022
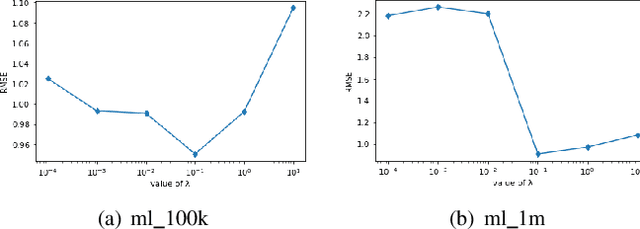
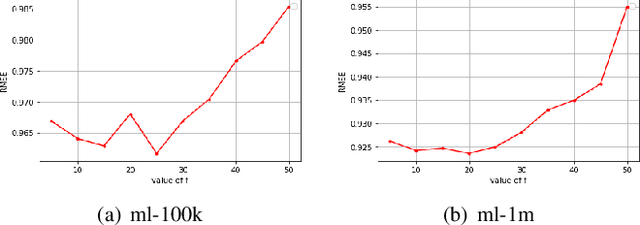
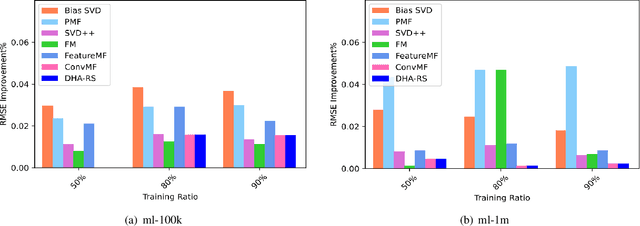
Matrix Factorization (MF) is one of the most successful Collaborative Filtering (CF) techniques used in recommender systems due to its effectiveness and ability to deal with very large user-item rating matrix. Among them, matrix decomposition method mainly uses the interactions records between users and items to predict ratings. Based on the characteristic attributes of items and users, this paper proposes a UISVD++ model that fuses the type attributes of movies and the age attributes of users into MF framework. Project and user representations in MF are enriched by projecting each user's age attribute and each movie's type attribute into the same potential factor space as users and items. Finally, the MovieLens-100K and MovieLens-1M datasets were used to compare with the traditional SVD++ and other models. The results show that the proposed model can achieve the best recommendation performance and better predict user ratings under all backgrounds.
RNNCTPs: A Neural Symbolic Reasoning Method Using Dynamic Knowledge Partitioning Technology
Apr 19, 2022
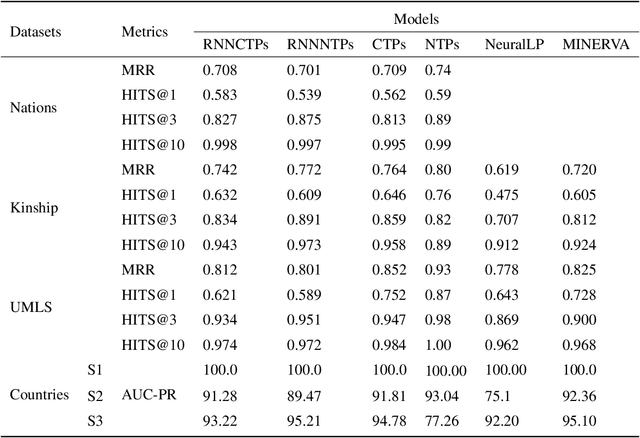
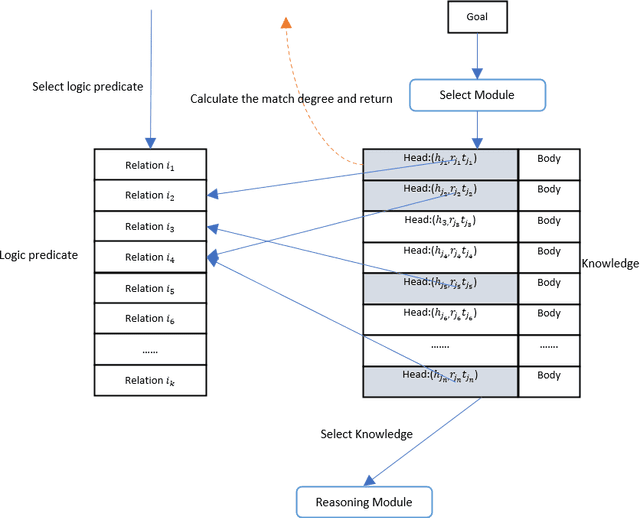
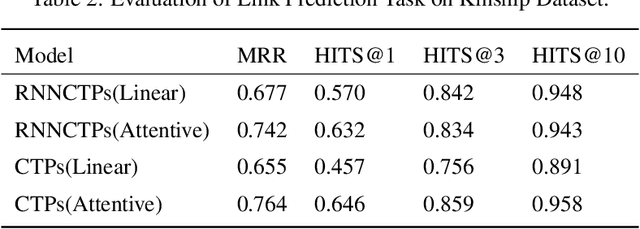
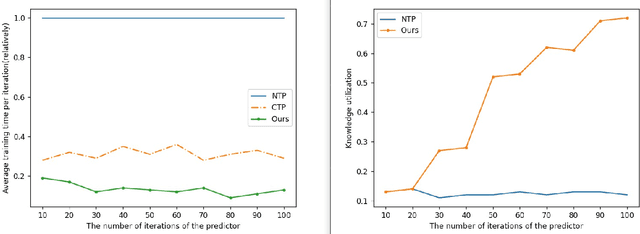
Although traditional symbolic reasoning methods are highly interpretable, their application in knowledge graph link prediction is limited due to their low computational efficiency. In this paper, we propose a new neural symbolic reasoning method: RNNCTPs, which improves computational efficiency by re-filtering the knowledge selection of Conditional Theorem Provers (CTPs), and is less sensitive to the embedding size parameter. RNNCTPs are divided into relation selectors and predictors. The relation selectors are trained efficiently and interpretably, so that the whole model can dynamically generate knowledge for the inference of the predictor. In all four datasets, the method shows competitive performance against traditional methods on the link prediction task, and can have higher applicability to the selection of datasets relative to CTPs.
Neural Theorem Provers Delineating Search Area Using RNN
Mar 14, 2022


Although traditional symbolic reasoning methods are highly interpretable, their application in knowledge graphs link prediction has been limited due to their computational inefficiency. A new RNNNTP method is proposed in this paper, using a generalized EM-based approach to continuously improve the computational efficiency of Neural Theorem Provers(NTPs). The RNNNTP is divided into relation generator and predictor. The relation generator is trained effectively and interpretably, so that the whole model can be carried out according to the development of the training, and the computational efficiency is also greatly improved. In all four data-sets, this method shows competitive performance on the link prediction task relative to traditional methods as well as one of the current strong competitive methods.