 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Multilingual Language Model Pretraining for Social Media Text via Translation Pair Prediction
Paper and Code
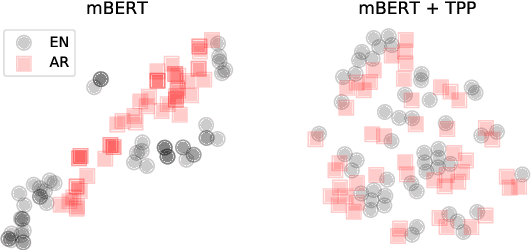
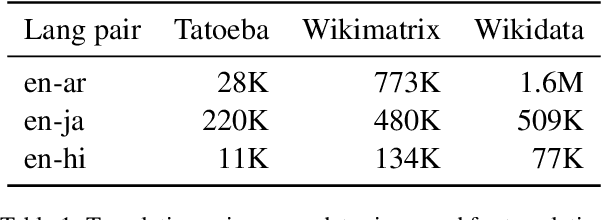
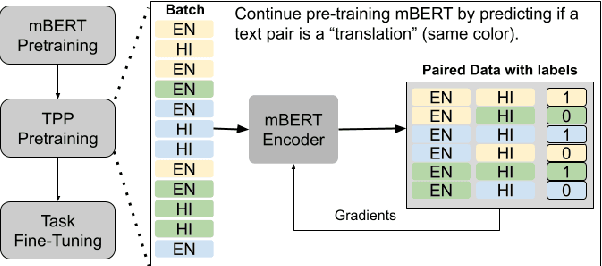
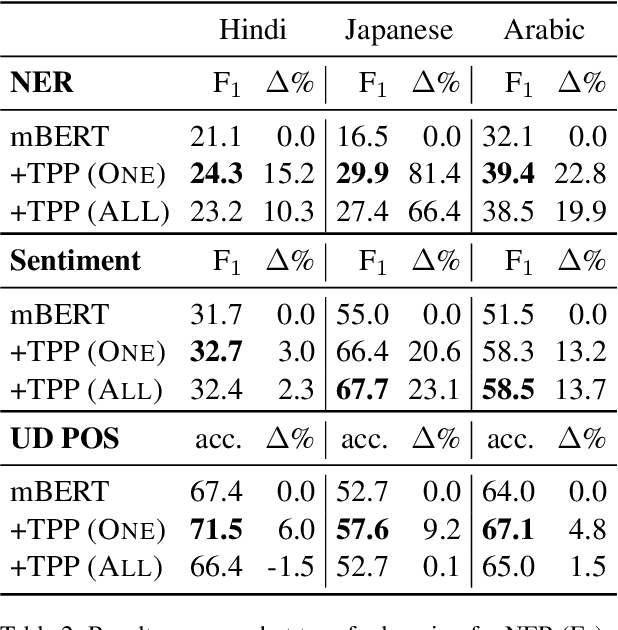
We evaluate a simple approach to improving zero-shot multilingual transfer of mBERT on social media corpus by adding a pretraining task called translation pair prediction (TPP), which predicts whether a pair of cross-lingual texts are a valid translation. Our approach assumes access to translations (exact or approximate) between source-target language pairs, where we fine-tune a model on source language task data and evaluate the model in the target language. In particular, we focus on language pairs where transfer learning is difficult for mBERT: those where source and target languages are different in script, vocabulary, and linguistic typology. We show improvements from TPP pretraining over mBERT alone in zero-shot transfer from English to Hindi, Arabic, and Japanese on two social media tasks: NER (a 37% average relative improvement in F1 across target languages) and sentiment classification (12% relative improvement in F1) on social media text, while also benchmarking on a non-social media task of Universal Dependency POS tagging (6.7% relative improvement in accuracy). Our results are promising given the lack of social media bitext corpus. Our code can be found at: https://github.com/twitter-research/multilingual-alignment-tpp.