 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Rank Factorization for Compact Multi-Head Self-Attention
Paper and Code
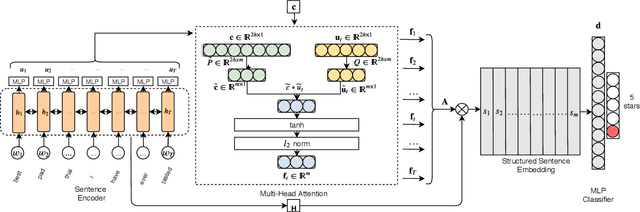
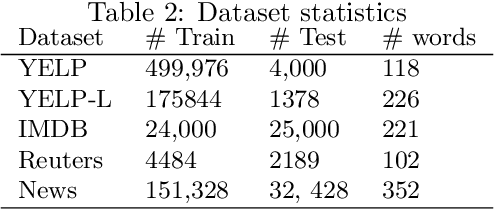
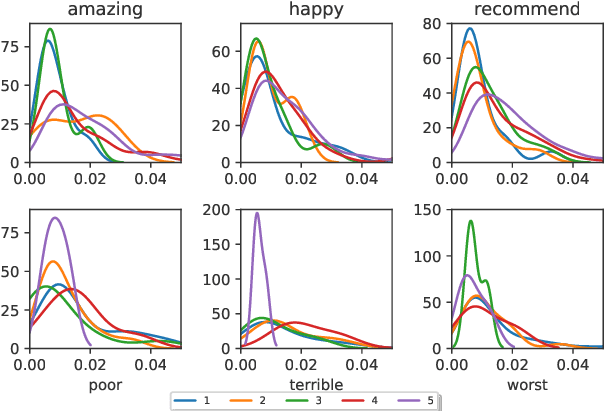
Effective representation learning from text has been an active area of research in the fields of NLP and text mining. Attention mechanisms have been at the forefront in order to learn contextual sentence representations. Current state-of-art approaches in representation learning use single-head and multi-head attention mechanisms to learn context-aware representations. However, these approaches can be largely parameter intensive resulting in low-resource bottlenecks. In this work we present a novel multi-head attention mechanism that uses low-rank bilinear pooling to efficiently construct a structured sentence representation that attends to multiple aspects of a sentence. We show that the proposed model is more effeffective than single-head attention mechanisms and is also more parameter efficient and faster to compute than existing multi-head approaches. We evaluate the performance of the proposed model on multiple datasets on two text classification benchmarks including: (i) Sentiment Analysis and (ii) News classification.