 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Trustworthiness: Rethinking Tasks and Model Evaluation
Oct 23, 2023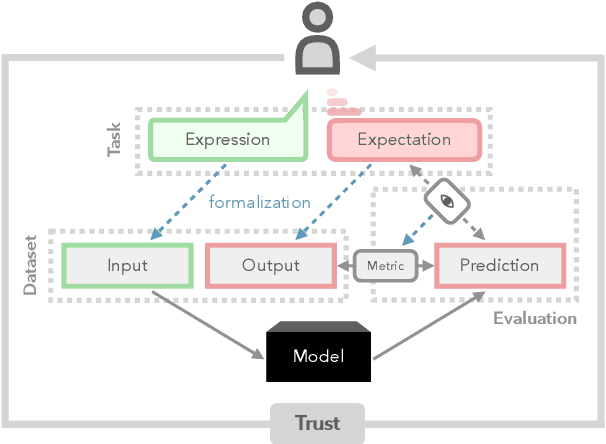
Language understanding is a multi-faceted cognitive capability, which the Natural Language Processing (NLP) community has striven to model computationally for decades. Traditionally, facets of linguistic intelligence have been compartmentalized into tasks with specialized model architectures and corresponding evaluation protocols. With the advent of large language models (LLMs) the community has witnessed a dramatic shift towards general purpose, task-agnostic approaches powered by generative models. As a consequence, the traditional compartmentalized notion of language tasks is breaking down, followed by an increasing challenge for evaluation and analysis. At the same time, LLMs are being deployed in more real-world scenarios, including previously unforeseen zero-shot setups, increasing the need for trustworthy and reliable systems. Therefore, we argue that it is time to rethink what constitutes tasks and model evaluation in NLP, and pursue a more holistic view on language, placing trustworthiness at the center. Towards this goal, we review existing compartmentalized approaches for understanding the origins of a model's functional capacity, and provide recommendations for more multi-faceted evaluation protocols.
ActiveAED: A Human in the Loop Improves Annotation Error Detection
May 31, 2023



Manually annotated datasets are crucial for training and evaluating Natural Language Processing models. However, recent work has discovered that even widely-used benchmark datasets contain a substantial number of erroneous annotations. This problem has been addressed with Annotation Error Detection (AED) models, which can flag such errors for human re-annotation. However, even though many of these AED methods assume a final curation step in which a human annotator decides whether the annotation is erroneous, they have been developed as static models without any human-in-the-loop component. In this work, we propose ActiveAED, an AED method that can detect errors more accurately by repeatedly querying a human for error corrections in its prediction loop. We evaluate ActiveAED on eight datasets spanning five different tasks and find that it leads to improvements over the state of the art on seven of them, with gains of up to six percentage points in average precision.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023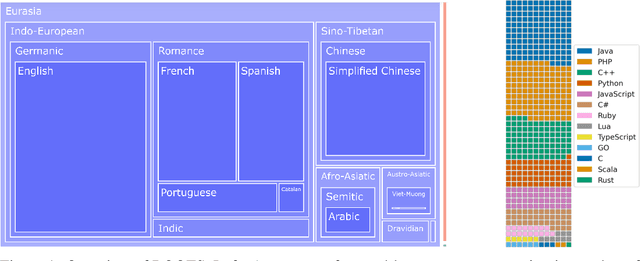


As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022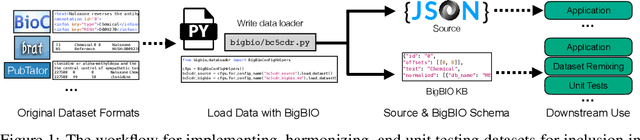
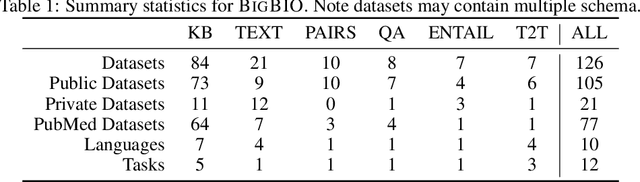

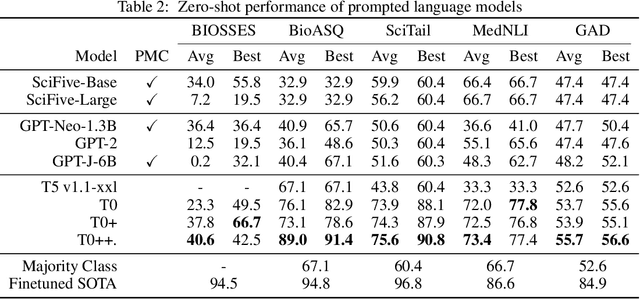
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
HunFlair: An Easy-to-Use Tool for State-of-the-Art Biomedical Named Entity Recognition
Aug 18, 2020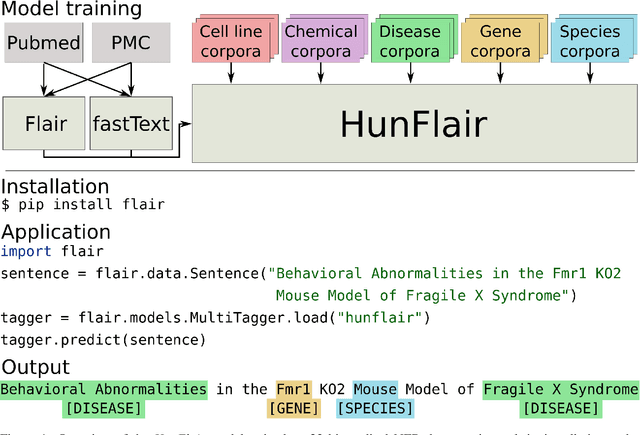
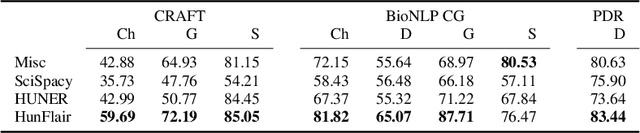
Summary: Named Entity Recognition (NER) is an important step in biomedical information extraction pipelines. Tools for NER should be easy to use, cover multiple entity types, highly accurate, and robust towards variations in text genre and style. To this end, we propose HunFlair, an NER tagger covering multiple entity types integrated into the widely used NLP framework Flair. HunFlair outperforms other state-of-the-art standalone NER tools with an average gain of 7.26 pp over the next best tool, can be installed with a single command and is applied with only four lines of code. Availability: HunFlair is freely available through the Flair framework under an MIT license: https://github.com/flairNLP/flair and is compatible with all major operating systems. Contact:{weberple,saengema,alan.akbik}@informatik.hu-berlin.de
NLProlog: Reasoning with Weak Unification for Question Answering in Natural Language
Jun 14, 2019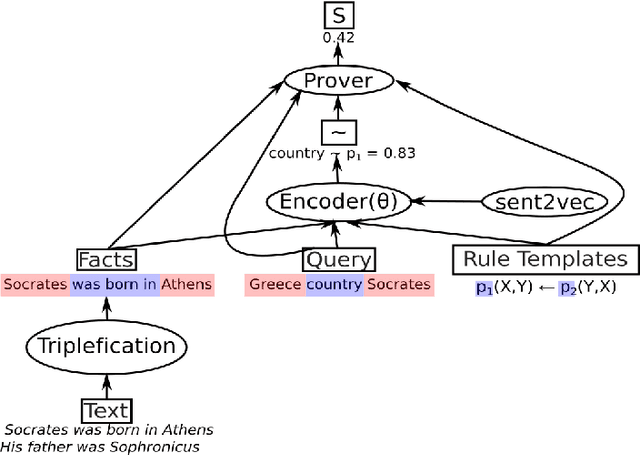
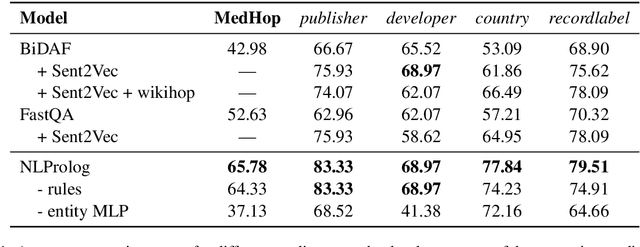
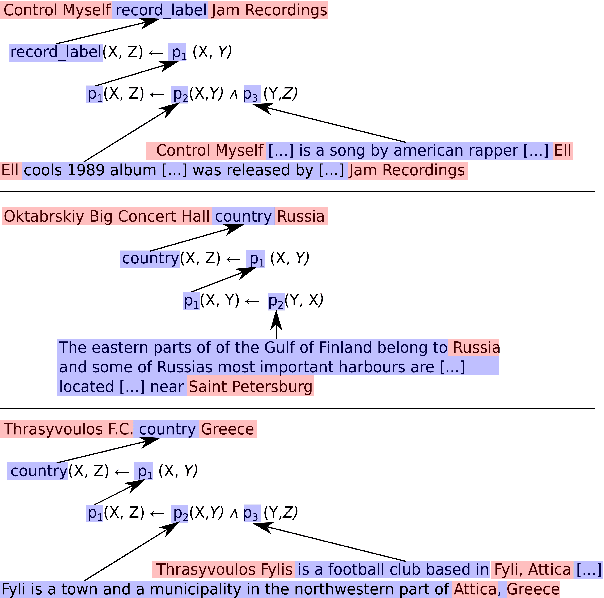
Rule-based models are attractive for various tasks because they inherently lead to interpretable and explainable decisions and can easily incorporate prior knowledge. However, such systems are difficult to apply to problems involving natural language, due to its linguistic variability. In contrast, neural models can cope very well with ambiguity by learning distributed representations of words and their composition from data, but lead to models that are difficult to interpret. In this paper, we describe a model combining neural networks with logic programming in a novel manner for solving multi-hop reasoning tasks over natural language. Specifically, we propose to use a Prolog prover which we extend to utilize a similarity function over pretrained sentence encoders. We fine-tune the representations for the similarity function via backpropagation. This leads to a system that can apply rule-based reasoning to natural language, and induce domain-specific rules from training data. We evaluate the proposed system on two different question answering tasks, showing that it outperforms two baselines -- BIDAF (Seo et al., 2016a) and FAST QA (Weissenborn et al., 2017b) on a subset of the WikiHop corpus and achieves competitive results on the MedHop data set (Welbl et al., 2017).