 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinity-Guided Discriminative Latent Diffusion for Privacy-Preserving Domain Adaptation
Oct 01, 2025Recent work on latent diffusion models (LDMs) has focused almost exclusively on generative tasks, leaving their potential for discriminative transfer largely unexplored. We introduce Discriminative Vicinity Diffusion (DVD), a novel LDM-based framework for a more practical variant of source-free domain adaptation (SFDA): the source provider may share not only a pre-trained classifier but also an auxiliary latent diffusion module, trained once on the source data and never exposing raw source samples. DVD encodes each source feature's label information into its latent vicinity by fitting a Gaussian prior over its k-nearest neighbors and training the diffusion network to drift noisy samples back to label-consistent representations. During adaptation, we sample from each target feature's latent vicinity, apply the frozen diffusion module to generate source-like cues, and use a simple InfoNCE loss to align the target encoder to these cues, explicitly transferring decision boundaries without source access. Across standard SFDA benchmarks, DVD outperforms state-of-the-art methods. We further show that the same latent diffusion module enhances the source classifier's accuracy on in-domain data and boosts performance in supervised classification and domain generalization experiments. DVD thus reinterprets LDMs as practical, privacy-preserving bridges for explicit knowledge transfer, addressing a core challenge in source-free domain adaptation that prior methods have yet to solve.
Uncertainty Herding: One Active Learning Method for All Label Budgets
Dec 30, 2024Most active learning research has focused on methods which perform well when many labels are available, but can be dramatically worse than random selection when label budgets are small. Other methods have focused on the low-budget regime, but do poorly as label budgets increase. As the line between "low" and "high" budgets varies by problem, this is a serious issue in practice. We propose uncertainty coverage, an objective which generalizes a variety of low- and high-budget objectives, as well as natural, hyperparameter-light methods to smoothly interpolate between low- and high-budget regimes. We call greedy optimization of the estimate Uncertainty Herding; this simple method is computationally fast, and we prove that it nearly optimizes the distribution-level coverage. In experimental validation across a variety of active learning tasks, our proposal matches or beats state-of-the-art performance in essentially all cases; it is the only method of which we are aware that reliably works well in both low- and high-budget settings.
What Has Been Overlooked in Contrastive Source-Free Domain Adaptation: Leveraging Source-Informed Latent Augmentation within Neighborhood Context
Dec 18, 2024Source-free domain adaptation (SFDA) involves adapting a model originally trained using a labeled dataset ({\em source domain}) to perform effectively on an unlabeled dataset ({\em target domain}) without relying on any source data during adaptation. This adaptation is especially crucial when significant disparities in data distributions exist between the two domains and when there are privacy concerns regarding the source model's training data. The absence of access to source data during adaptation makes it challenging to analytically estimate the domain gap. To tackle this issue, various techniques have been proposed, such as unsupervised clustering, contrastive learning, and continual learning. In this paper, we first conduct an extensive theoretical analysis of SFDA based on contrastive learning, primarily because it has demonstrated superior performance compared to other techniques. Motivated by the obtained insights, we then introduce a straightforward yet highly effective latent augmentation method tailored for contrastive SFDA. This augmentation method leverages the dispersion of latent features within the neighborhood of the query sample, guided by the source pre-trained model, to enhance the informativeness of positive keys. Our approach, based on a single InfoNCE-based contrastive loss, outperforms state-of-the-art SFDA methods on widely recognized benchmark datasets.
Generalized Coverage for More Robust Low-Budget Active Learning
Jul 16, 2024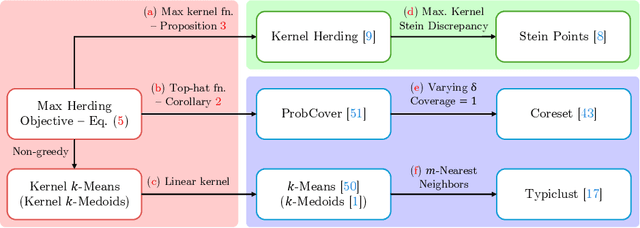
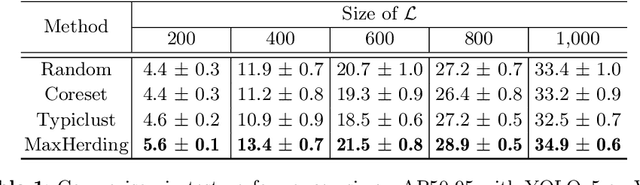
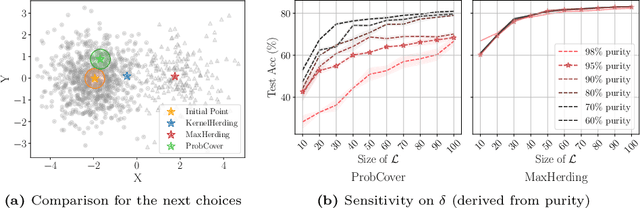
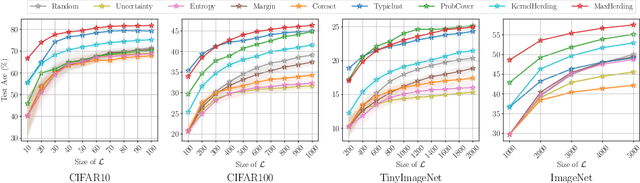
The ProbCover method of Yehuda et al. is a well-motivated algorithm for active learning in low-budget regimes, which attempts to "cover" the data distribution with balls of a given radius at selected data points. We demonstrate, however, that the performance of this algorithm is extremely sensitive to the choice of this radius hyper-parameter, and that tuning it is quite difficult, with the original heuristic frequently failing. We thus introduce (and theoretically motivate) a generalized notion of "coverage," including ProbCover's objective as a special case, but also allowing smoother notions that are far more robust to hyper-parameter choice. We propose an efficient greedy method to optimize this coverage, generalizing ProbCover's algorithm; due to its close connection to kernel herding, we call it "MaxHerding." The objective can also be optimized non-greedily through a variant of $k$-medoids, clarifying the relationship to other low-budget active learning methods. In comprehensive experiments, MaxHerding surpasses existing active learning methods across multiple low-budget image classification benchmarks, and does so with less computational cost than most competitive methods.
Exploring Active Learning in Meta-Learning: Enhancing Context Set Labeling
Nov 06, 2023Most meta-learning methods assume that the (very small) context set used to establish a new task at test time is passively provided. In some settings, however, it is feasible to actively select which points to label; the potential gain from a careful choice is substantial, but the setting requires major differences from typical active learning setups. We clarify the ways in which active meta-learning can be used to label a context set, depending on which parts of the meta-learning process use active learning. Within this framework, we propose a natural algorithm based on fitting Gaussian mixtures for selecting which points to label; though simple, the algorithm also has theoretical motivation. The proposed algorithm outperforms state-of-the-art active learning methods when used with various meta-learning algorithms across several benchmark datasets.
AdaFlood: Adaptive Flood Regularization
Nov 06, 2023Although neural networks are conventionally optimized towards zero training loss, it has been recently learned that targeting a non-zero training loss threshold, referred to as a flood level, often enables better test time generalization. Current approaches, however, apply the same constant flood level to all training samples, which inherently assumes all the samples have the same difficulty. We present AdaFlood, a novel flood regularization method that adapts the flood level of each training sample according to the difficulty of the sample. Intuitively, since training samples are not equal in difficulty, the target training loss should be conditioned on the instance. Experiments on datasets covering four diverse input modalities - text, images, asynchronous event sequences, and tabular - demonstrate the versatility of AdaFlood across data domains and noise levels.
How to prepare your task head for finetuning
Feb 11, 2023In deep learning, transferring information from a pretrained network to a downstream task by finetuning has many benefits. The choice of task head plays an important role in fine-tuning, as the pretrained and downstream tasks are usually different. Although there exist many different designs for finetuning, a full understanding of when and why these algorithms work has been elusive. We analyze how the choice of task head controls feature adaptation and hence influences the downstream performance. By decomposing the learning dynamics of adaptation, we find that the key aspect is the training accuracy and loss at the beginning of finetuning, which determines the "energy" available for the feature's adaptation. We identify a significant trend in the effect of changes in this initial energy on the resulting features after fine-tuning. Specifically, as the energy increases, the Euclidean and cosine distances between the resulting and original features increase, while their dot products (and the resulting features' norm) first increase and then decrease. Inspired by this, we give several practical principles that lead to better downstream performance. We analytically prove this trend in an overparamterized linear setting and verify its applicability to different experimental settings.
Meta Temporal Point Processes
Jan 27, 2023



A temporal point process (TPP) is a stochastic process where its realization is a sequence of discrete events in time. Recent work in TPPs model the process using a neural network in a supervised learning framework, where a training set is a collection of all the sequences. In this work, we propose to train TPPs in a meta learning framework, where each sequence is treated as a different task, via a novel framing of TPPs as neural processes (NPs). We introduce context sets to model TPPs as an instantiation of NPs. Motivated by attentive NP, we also introduce local history matching to help learn more informative features. We demonstrate the potential of the proposed method on popular public benchmark datasets and tasks, and compare with state-of-the-art TPP methods.
Object Discovery via Contrastive Learning for Weakly Supervised Object Detection
Aug 16, 2022
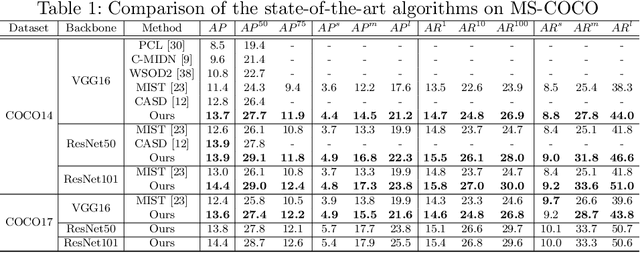
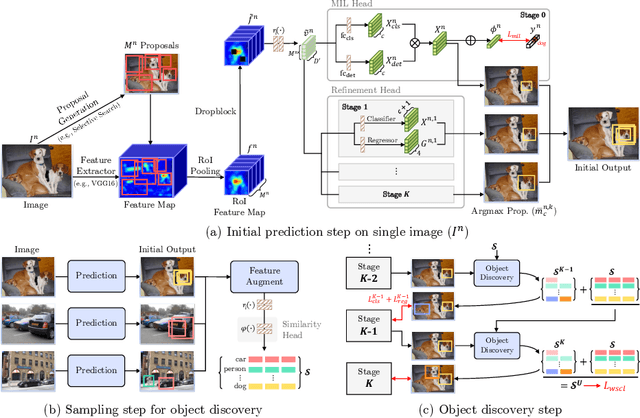
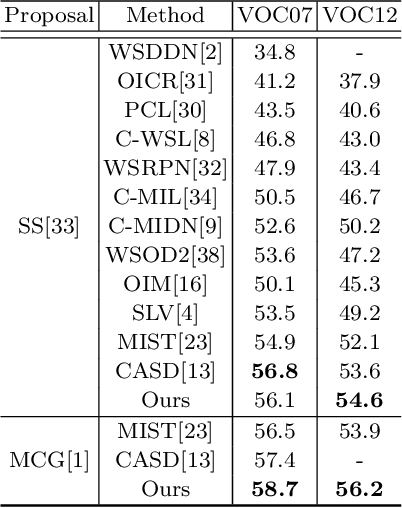
Weakly Supervised Object Detection (WSOD) is a task that detects objects in an image using a model trained only on image-level annotations. Current state-of-the-art models benefit from self-supervised instance-level supervision, but since weak supervision does not include count or location information, the most common ``argmax'' labeling method often ignores many instances of objects. To alleviate this issue, we propose a novel multiple instance labeling method called object discovery. We further introduce a new contrastive loss under weak supervision where no instance-level information is available for sampling, called weakly supervised contrastive loss (WSCL). WSCL aims to construct a credible similarity threshold for object discovery by leveraging consistent features for embedding vectors in the same class. As a result, we achieve new state-of-the-art results on MS-COCO 2014 and 2017 as well as PASCAL VOC 2012, and competitive results on PASCAL VOC 2007.
Making Look-Ahead Active Learning Strategies Feasible with Neural Tangent Kernels
Jun 25, 2022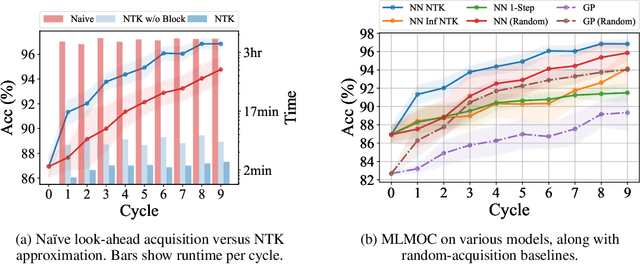
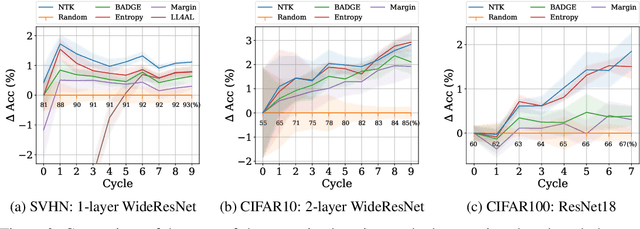
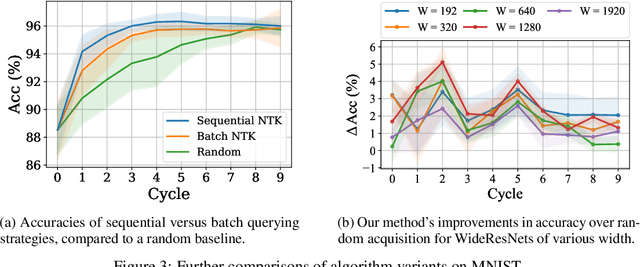
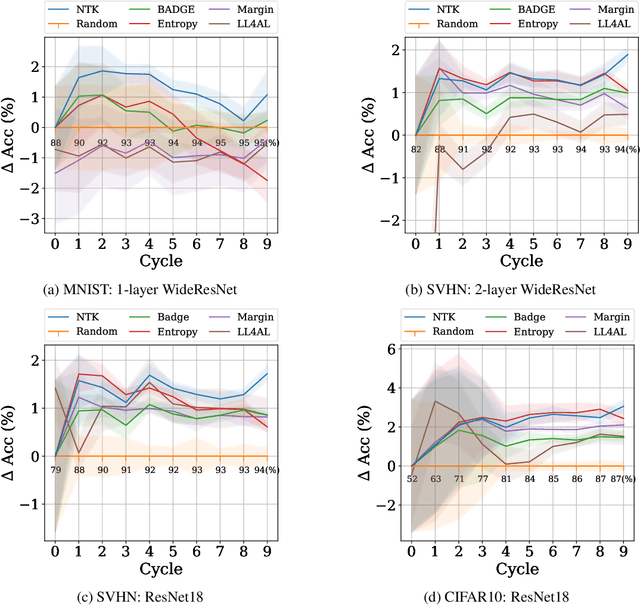
We propose a new method for approximating active learning acquisition strategies that are based on retraining with hypothetically-labeled candidate data points. Although this is usually infeasible with deep networks, we use the neural tangent kernel to approximate the result of retraining, and prove that this approximation works asymptotically even in an active learning setup -- approximating "look-ahead" selection criteria with far less computation required. This also enables us to conduct sequential active learning, i.e. updating the model in a streaming regime, without needing to retrain the model with SGD after adding each new data point. Moreover, our querying strategy, which better understands how the model's predictions will change by adding new data points in comparison to the standard ("myopic") criteria, beats other look-ahead strategies by large margins, and achieves equal or better performance compared to state-of-the-art methods on several benchmark datasets in pool-based active learning.