 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-based Mask for Domain Adaptation
Apr 22, 2023



In computer vision, unsupervised domain adaptation (UDA) is an approach to transferring knowledge from a label-rich source domain to a fully-unlabeled target domain. Conventional UDA approaches have two problems. The first problem is that a class classifier can be biased to the source domain because it is trained using only source samples. The second is that previous approaches align image-level features regardless of foreground and background, although the classifier requires foreground features. To solve these problems, we introduce Weight-based Mask Network (WEMNet) composed of Domain Ignore Module (DIM) and Semantic Enhancement Module (SEM). DIM obtains domain-agnostic feature representations via the weight of the domain discriminator and predicts categories. In addition, SEM obtains class-related feature representations using the classifier weight and focuses on the foreground features for domain adaptation. Extensive experimental results reveal that the proposed WEMNet outperforms the competitive accuracy on representative UDA datasets.
Revisiting Image Pyramid Structure for High Resolution Salient Object Detection
Sep 26, 2022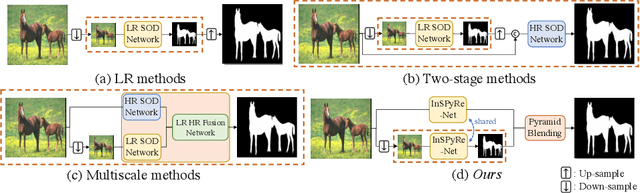
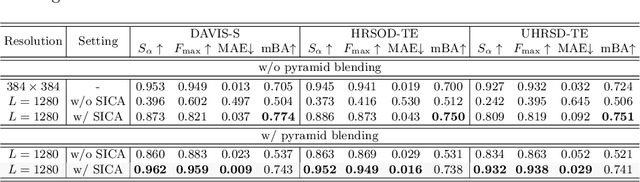

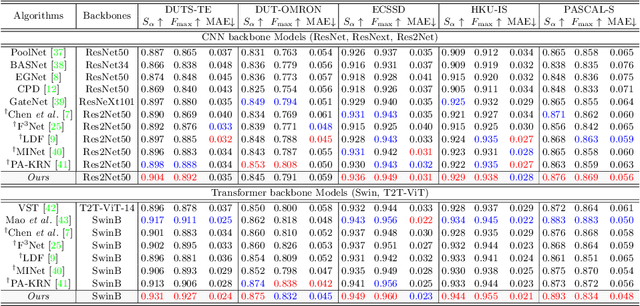
Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images and annotations. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluations on public LR and HR SOD benchmarks demonstrate that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.
Object Discovery via Contrastive Learning for Weakly Supervised Object Detection
Aug 16, 2022
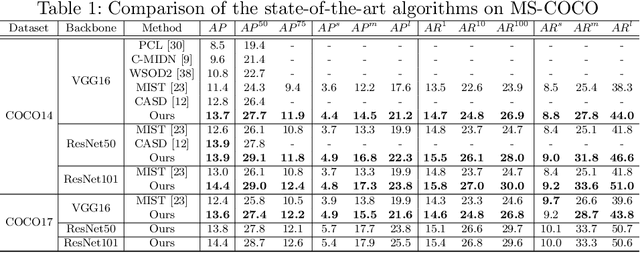
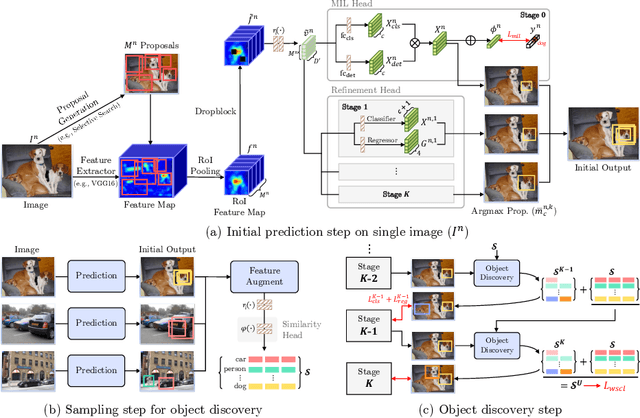
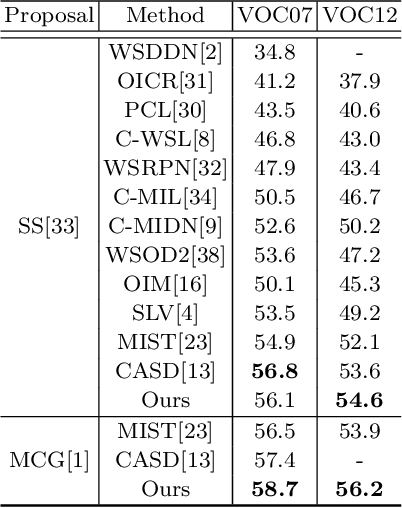
Weakly Supervised Object Detection (WSOD) is a task that detects objects in an image using a model trained only on image-level annotations. Current state-of-the-art models benefit from self-supervised instance-level supervision, but since weak supervision does not include count or location information, the most common ``argmax'' labeling method often ignores many instances of objects. To alleviate this issue, we propose a novel multiple instance labeling method called object discovery. We further introduce a new contrastive loss under weak supervision where no instance-level information is available for sampling, called weakly supervised contrastive loss (WSCL). WSCL aims to construct a credible similarity threshold for object discovery by leveraging consistent features for embedding vectors in the same class. As a result, we achieve new state-of-the-art results on MS-COCO 2014 and 2017 as well as PASCAL VOC 2012, and competitive results on PASCAL VOC 2007.
DAM-GAN : Image Inpainting using Dynamic Attention Map based on Fake Texture Detection
Apr 20, 2022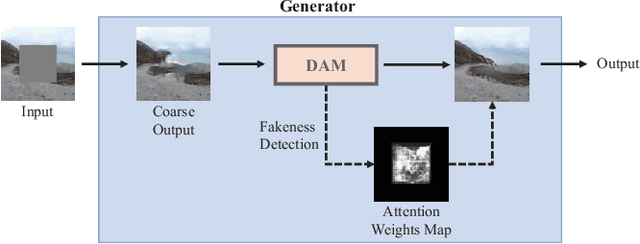
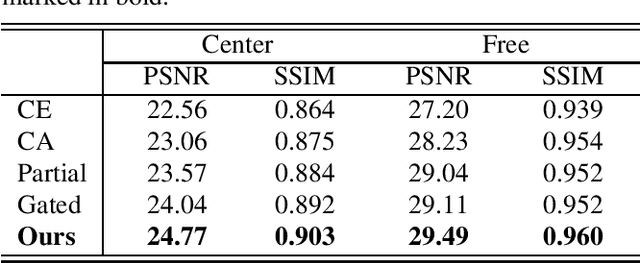
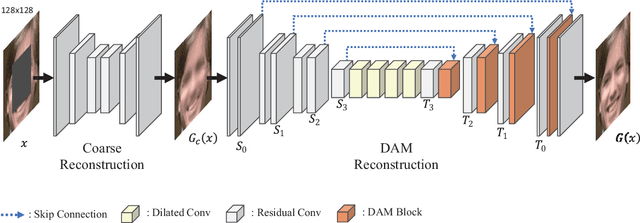
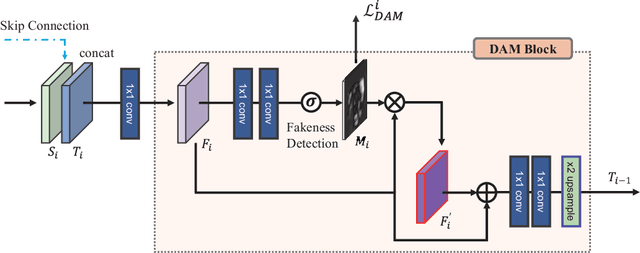
Deep neural advancements have recently brought remarkable image synthesis performance to the field of image inpainting. The adaptation of generative adversarial networks (GAN) in particular has accelerated significant progress in high-quality image reconstruction. However, although many notable GAN-based networks have been proposed for image inpainting, still pixel artifacts or color inconsistency occur in synthesized images during the generation process, which are usually called fake textures. To reduce pixel inconsistency disorder resulted from fake textures, we introduce a GAN-based model using dynamic attention map (DAM-GAN). Our proposed DAM-GAN concentrates on detecting fake texture and products dynamic attention maps to diminish pixel inconsistency from the feature maps in the generator. Evaluation results on CelebA-HQ and Places2 datasets with other image inpainting approaches show the superiority of our network.
A Style-aware Discriminator for Controllable Image Translation
Mar 29, 2022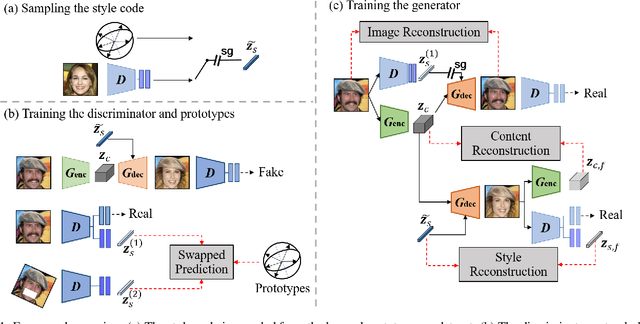
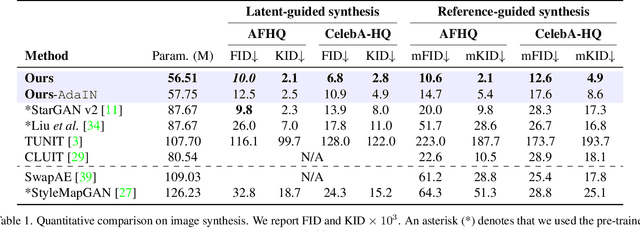

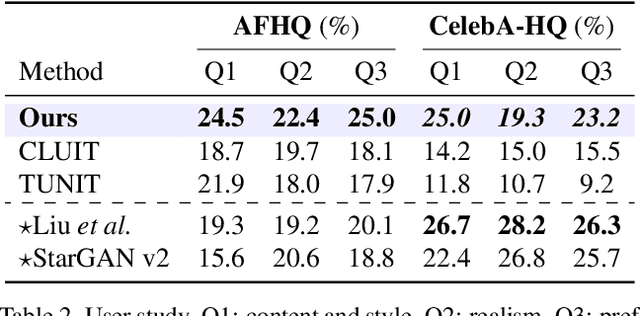
Current image-to-image translations do not control the output domain beyond the classes used during training, nor do they interpolate between different domains well, leading to implausible results. This limitation largely arises because labels do not consider the semantic distance. To mitigate such problems, we propose a style-aware discriminator that acts as a critic as well as a style encoder to provide conditions. The style-aware discriminator learns a controllable style space using prototype-based self-supervised learning and simultaneously guides the generator. Experiments on multiple datasets verify that the proposed model outperforms current state-of-the-art image-to-image translation methods. In contrast with current methods, the proposed approach supports various applications, including style interpolation, content transplantation, and local image translation.
FA-GAN: Feature-Aware GAN for Text to Image Synthesis
Sep 02, 2021

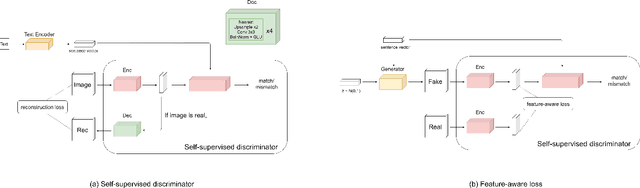

Text-to-image synthesis aims to generate a photo-realistic image from a given natural language description. Previous works have made significant progress with Generative Adversarial Networks (GANs). Nonetheless, it is still hard to generate intact objects or clear textures (Fig 1). To address this issue, we propose Feature-Aware Generative Adversarial Network (FA-GAN) to synthesize a high-quality image by integrating two techniques: a self-supervised discriminator and a feature-aware loss. First, we design a self-supervised discriminator with an auxiliary decoder so that the discriminator can extract better representation. Secondly, we introduce a feature-aware loss to provide the generator more direct supervision by employing the feature representation from the self-supervised discriminator. Experiments on the MS-COCO dataset show that our proposed method significantly advances the state-of-the-art FID score from 28.92 to 24.58.
Localization Uncertainty-Based Attention for Object Detection
Aug 25, 2021
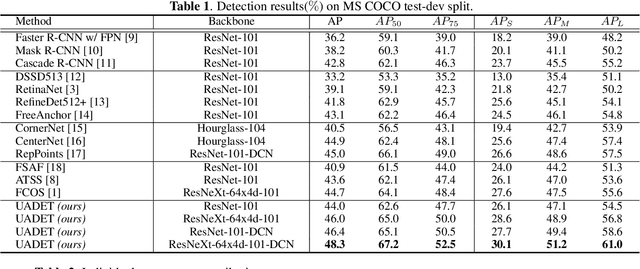
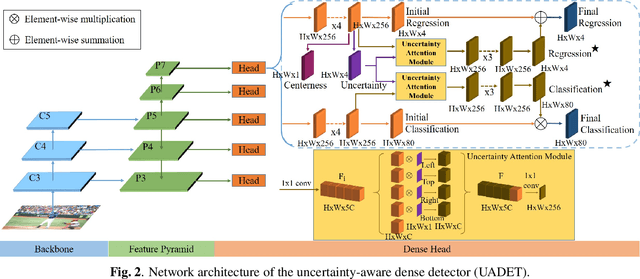
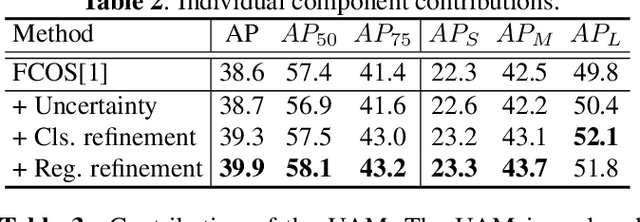
Object detection has been applied in a wide variety of real world scenarios, so detection algorithms must provide confidence in the results to ensure that appropriate decisions can be made based on their results. Accordingly, several studies have investigated the probabilistic confidence of bounding box regression. However, such approaches have been restricted to anchor-based detectors, which use box confidence values as additional screening scores during non-maximum suppression (NMS) procedures. In this paper, we propose a more efficient uncertainty-aware dense detector (UADET) that predicts four-directional localization uncertainties via Gaussian modeling. Furthermore, a simple uncertainty attention module (UAM) that exploits box confidence maps is proposed to improve performance through feature refinement. Experiments using the MS COCO benchmark show that our UADET consistently surpasses baseline FCOS, and that our best model, ResNext-64x4d-101-DCN, obtains a single model, single-scale AP of 48.3% on COCO test-dev, thus achieving the state-of-the-art among various object detectors.
UACANet: Uncertainty Augmented Context Attention for Polyp Segmentation
Jul 22, 2021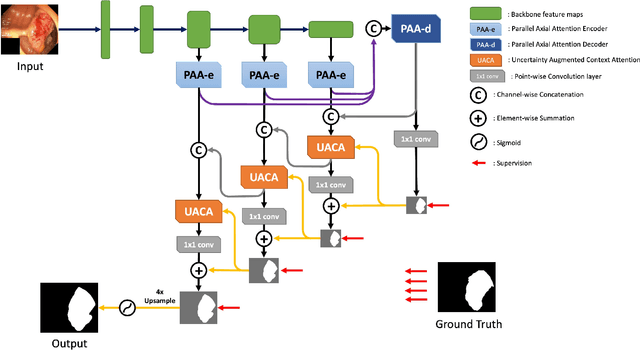
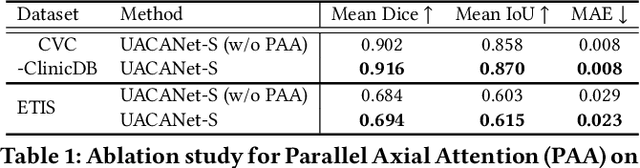
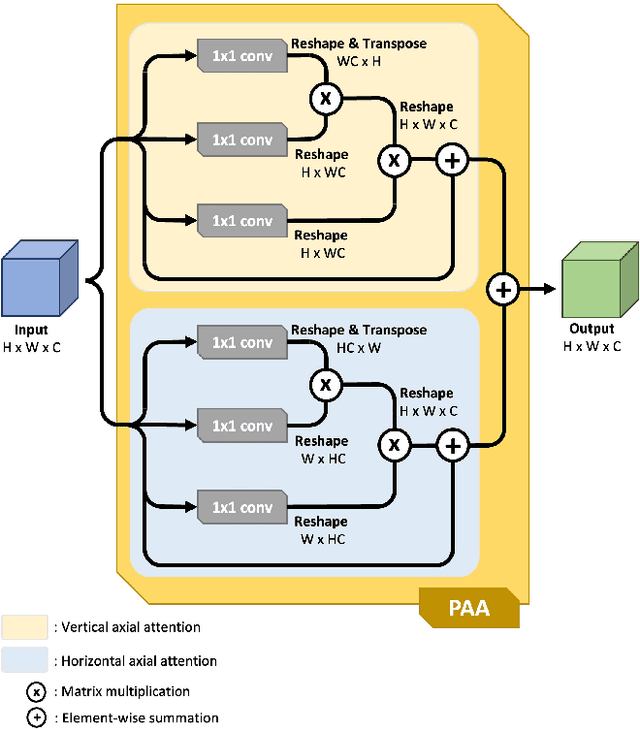
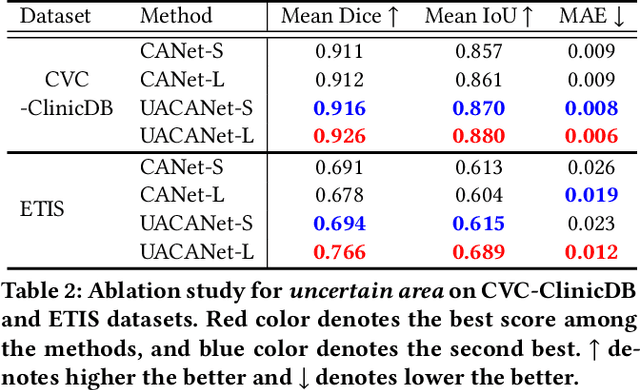
We propose Uncertainty Augmented Context Attention network (UACANet) for polyp segmentation which consider a uncertain area of the saliency map. We construct a modified version of U-Net shape network with additional encoder and decoder and compute a saliency map in each bottom-up stream prediction module and propagate to the next prediction module. In each prediction module, previously predicted saliency map is utilized to compute foreground, background and uncertain area map and we aggregate the feature map with three area maps for each representation. Then we compute the relation between each representation and each pixel in the feature map. We conduct experiments on five popular polyp segmentation benchmarks, Kvasir, CVC-ClinicDB, ETIS, CVC-ColonDB and CVC-300, and achieve state-of-the-art performance. Especially, we achieve 76.6% mean Dice on ETIS dataset which is 13.8% improvement compared to the previous state-of-the-art method. Source code is publicly available at https://github.com/plemeri/UACANet
SpaceMeshLab: Spatial Context Memoization and Meshgrid Atrous Convolution Consensus for Semantic Segmentation
Jun 08, 2021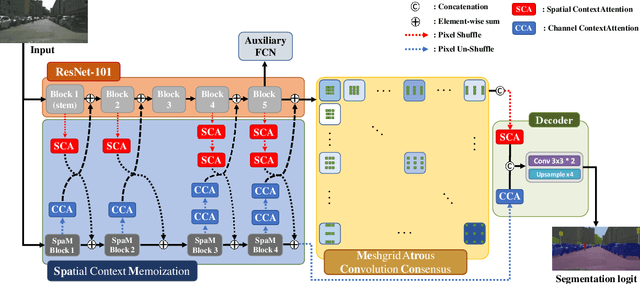

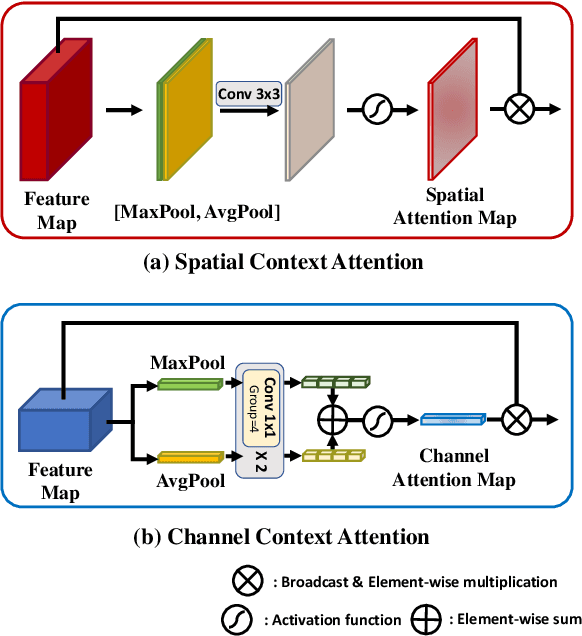

Semantic segmentation networks adopt transfer learning from image classification networks which occurs a shortage of spatial context information. For this reason, we propose Spatial Context Memoization (SpaM), a bypassing branch for spatial context by retaining the input dimension and constantly communicating its spatial context and rich semantic information mutually with the backbone network. Multi-scale context information for semantic segmentation is crucial for dealing with diverse sizes and shapes of target objects in the given scene. Conventional multi-scale context scheme adopts multiple effective receptive fields by multiple dilation rates or pooling operations, but often suffer from misalignment problem with respect to the target pixel. To this end, we propose Meshgrid Atrous Convolution Consensus (MetroCon^2) which brings multi-scale scheme into fine-grained multi-scale object context using convolutions with meshgrid-like scattered dilation rates. SpaceMeshLab (ResNet-101 + SpaM + MetroCon^2) achieves 82.0% mIoU in Cityscapes test and 53.5% mIoU on Pascal-Context validation set.
Detector With Focus: Normalizing Gradient In Image Pyramid
Sep 05, 2019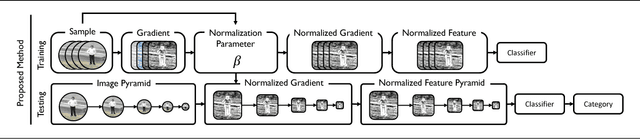
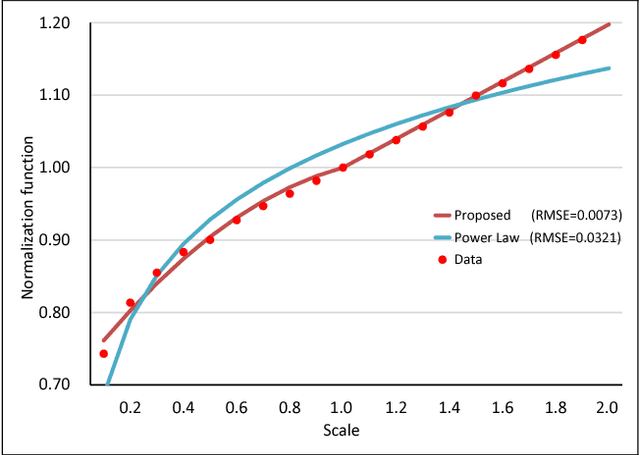
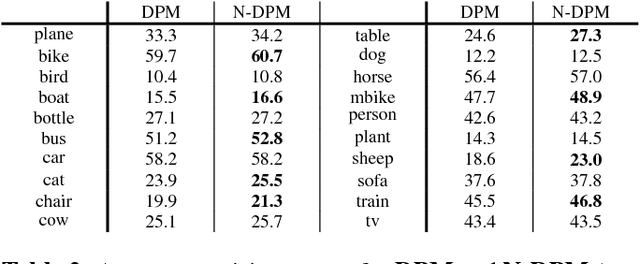
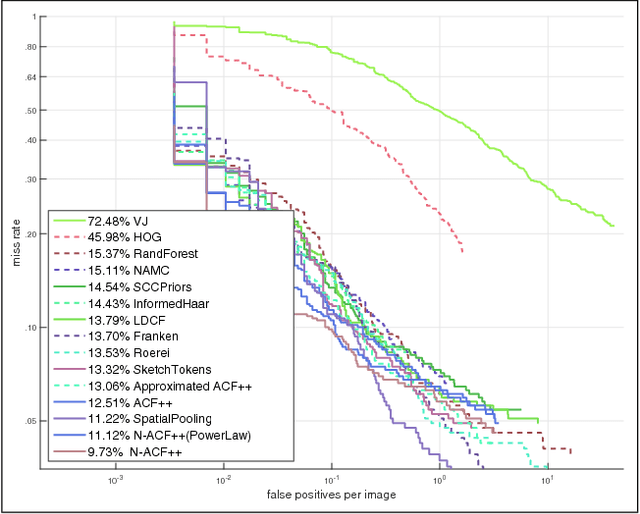
An image pyramid can extend many object detection algorithms to solve detection on multiple scales. However, interpolation during the resampling process of an image pyramid causes gradient variation, which is the difference of the gradients between the original image and the scaled images. Our key insight is that the increased variance of gradients makes the classifiers have difficulty in correctly assigning categories. We prove the existence of the gradient variation by formulating the ratio of gradient expectations between an original image and scaled images, then propose a simple and novel gradient normalization method to eliminate the effect of this variation. The proposed normalization method reduce the variance in an image pyramid and allow the classifier to focus on a smaller coverage. We show the improvement in three different visual recognition problems: pedestrian detection, pose estimation, and object detection. The method is generally applicable to many vision algorithms based on an image pyramid with gradients.