 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-based Mask for Domain Adaptation
Apr 22, 2023



In computer vision, unsupervised domain adaptation (UDA) is an approach to transferring knowledge from a label-rich source domain to a fully-unlabeled target domain. Conventional UDA approaches have two problems. The first problem is that a class classifier can be biased to the source domain because it is trained using only source samples. The second is that previous approaches align image-level features regardless of foreground and background, although the classifier requires foreground features. To solve these problems, we introduce Weight-based Mask Network (WEMNet) composed of Domain Ignore Module (DIM) and Semantic Enhancement Module (SEM). DIM obtains domain-agnostic feature representations via the weight of the domain discriminator and predicts categories. In addition, SEM obtains class-related feature representations using the classifier weight and focuses on the foreground features for domain adaptation. Extensive experimental results reveal that the proposed WEMNet outperforms the competitive accuracy on representative UDA datasets.
Localization Uncertainty-Based Attention for Object Detection
Aug 25, 2021
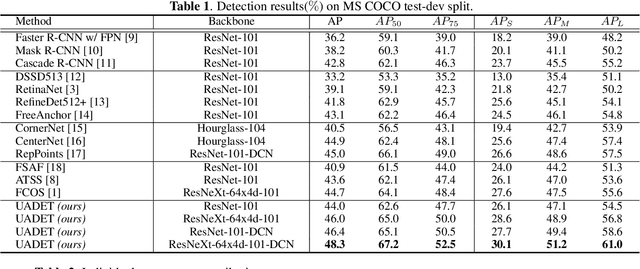
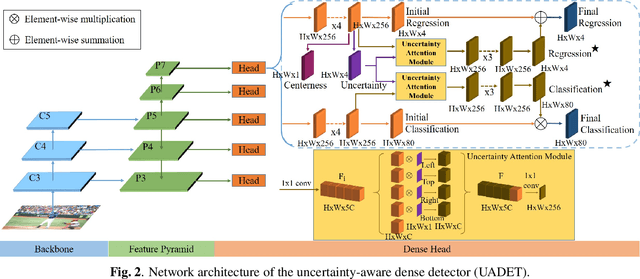
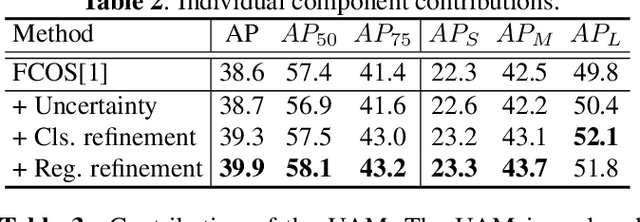
Object detection has been applied in a wide variety of real world scenarios, so detection algorithms must provide confidence in the results to ensure that appropriate decisions can be made based on their results. Accordingly, several studies have investigated the probabilistic confidence of bounding box regression. However, such approaches have been restricted to anchor-based detectors, which use box confidence values as additional screening scores during non-maximum suppression (NMS) procedures. In this paper, we propose a more efficient uncertainty-aware dense detector (UADET) that predicts four-directional localization uncertainties via Gaussian modeling. Furthermore, a simple uncertainty attention module (UAM) that exploits box confidence maps is proposed to improve performance through feature refinement. Experiments using the MS COCO benchmark show that our UADET consistently surpasses baseline FCOS, and that our best model, ResNext-64x4d-101-DCN, obtains a single model, single-scale AP of 48.3% on COCO test-dev, thus achieving the state-of-the-art among various object detectors.