 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFA-GAN: Feature-Aware GAN for Text to Image Synthesis
Paper and Code
Sep 02, 2021

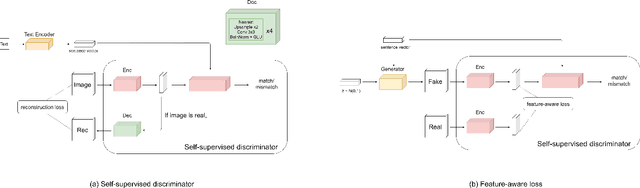

Text-to-image synthesis aims to generate a photo-realistic image from a given natural language description. Previous works have made significant progress with Generative Adversarial Networks (GANs). Nonetheless, it is still hard to generate intact objects or clear textures (Fig 1). To address this issue, we propose Feature-Aware Generative Adversarial Network (FA-GAN) to synthesize a high-quality image by integrating two techniques: a self-supervised discriminator and a feature-aware loss. First, we design a self-supervised discriminator with an auxiliary decoder so that the discriminator can extract better representation. Secondly, we introduce a feature-aware loss to provide the generator more direct supervision by employing the feature representation from the self-supervised discriminator. Experiments on the MS-COCO dataset show that our proposed method significantly advances the state-of-the-art FID score from 28.92 to 24.58.