 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Inference-Based Prompting for Natural Language Trading with Game NPCs
Jul 09, 2025Large Language Models enable dynamic game interactions but struggle with rule-governed trading systems. Current implementations suffer from rule violations, such as item hallucinations and calculation errors, that erode player trust. Here, State-Inference-Based Prompting (SIBP) enables reliable trading through autonomous dialogue state inference and context-specific rule adherence. The approach decomposes trading into six states within a unified prompt framework, implementing context-aware item referencing and placeholder-based price calculations. Evaluation across 100 trading dialogues demonstrates >97% state compliance, >95% referencing accuracy, and 99.7% calculation precision. SIBP maintains computational efficiency while outperforming baseline approaches, establishing a practical foundation for trustworthy NPC interactions in commercial games.
A Reinforcement Learning Formulation of the Lyapunov Optimization: Application to Edge Computing Systems with Queue Stability
Dec 15, 2020
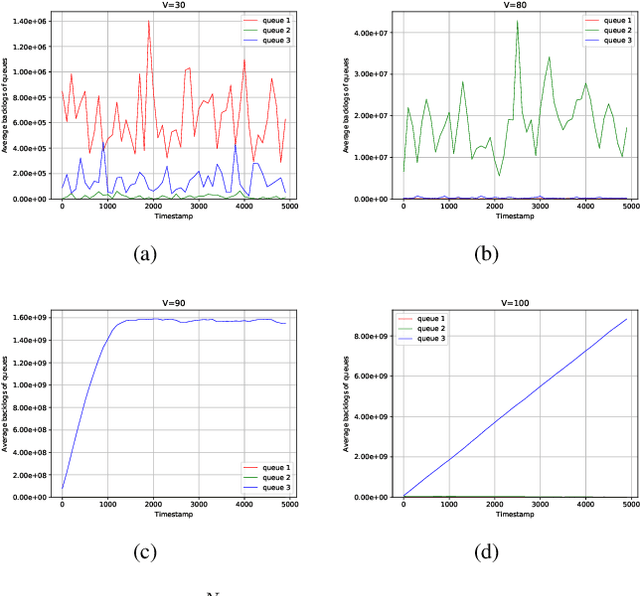
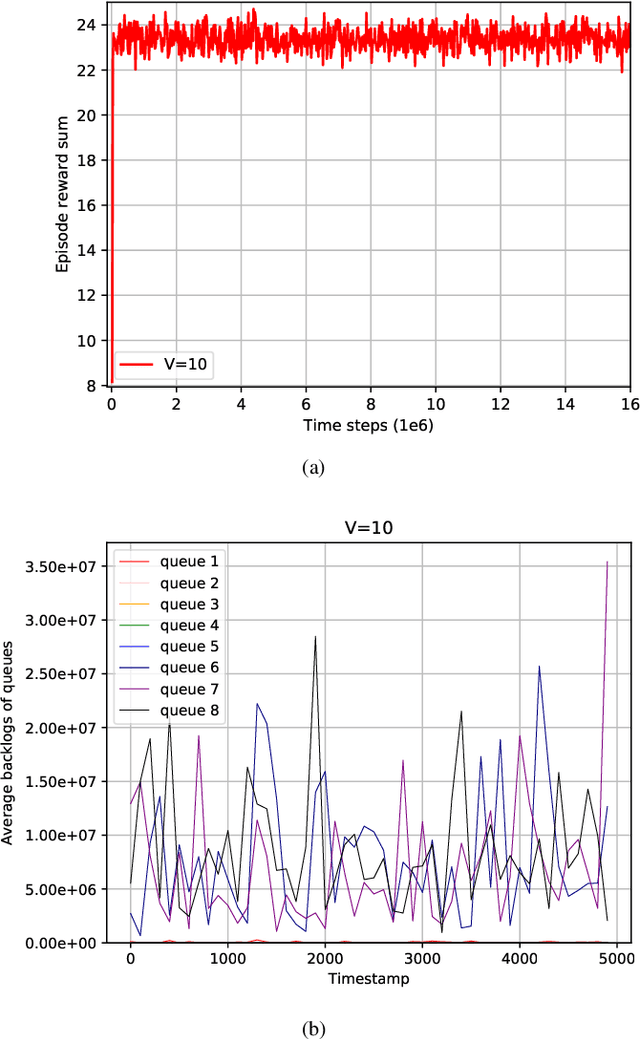

In this paper, a deep reinforcement learning (DRL)-based approach to the Lyapunov optimization is considered to minimize the time-average penalty while maintaining queue stability. A proper construction of state and action spaces is provided to form a proper Markov decision process (MDP) for the Lyapunov optimization. A condition for the reward function of reinforcement learning (RL) for queue stability is derived. Based on the analysis and practical RL with reward discounting, a class of reward functions is proposed for the DRL-based approach to the Lyapunov optimization. The proposed DRL-based approach to the Lyapunov optimization does not required complicated optimization at each time step and operates with general non-convex and discontinuous penalty functions. Hence, it provides an alternative to the conventional drift-plus-penalty (DPP) algorithm for the Lyapunov optimization. The proposed DRL-based approach is applied to resource allocation in edge computing systems with queue stability and numerical results demonstrate its successful operation.