 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFace: High Fidelity and Real-time Face Swapper Robust to Facial Pose
Jan 23, 2026Existing face-swapping methods often deliver competitive results in constrained settings but exhibit substantial quality degradation when handling extreme facial poses. To improve facial pose robustness, explicit geometric features are applied, but this approach remains problematic since it introduces additional dependencies and increases computational cost. Diffusion-based methods have achieved remarkable results; however, they are impractical for real-time processing. We introduce AlphaFace, which leverages an open-source vision-language model and CLIP image and text embeddings to apply novel visual and textual semantic contrastive losses. AlphaFace enables stronger identity representation and more precise attribute preservation, all while maintaining real-time performance. Comprehensive experiments across FF++, MPIE, and LPFF demonstrate that AlphaFace surpasses state-of-the-art methods in pose-challenging cases. The project is publicly available on `https://github.com/andrewyu90/Alphaface_Official.git'.
Adversarial Denoising Diffusion Model for Unsupervised Anomaly Detection
Dec 07, 2023

In this paper, we propose the Adversarial Denoising Diffusion Model (ADDM). The ADDM is based on the Denoising Diffusion Probabilistic Model (DDPM) but complementarily trained by adversarial learning. The proposed adversarial learning is achieved by classifying model-based denoised samples and samples to which random Gaussian noise is added to a specific sampling step. With the addition of explicit adversarial learning on data samples, ADDM can learn the semantic characteristics of the data more robustly during training, which achieves a similar data sampling performance with much fewer sampling steps than DDPM. We apply ADDM to anomaly detection in unsupervised MRI images. Experimental results show that the proposed ADDM outperformed existing generative model-based unsupervised anomaly detection methods. In particular, compared to other DDPM-based anomaly detection methods, the proposed ADDM shows better performance with the same number of sampling steps and similar performance with 50% fewer sampling steps.
Normality-Calibrated Autoencoder for Unsupervised Anomaly Detection on Data Contamination
Oct 28, 2021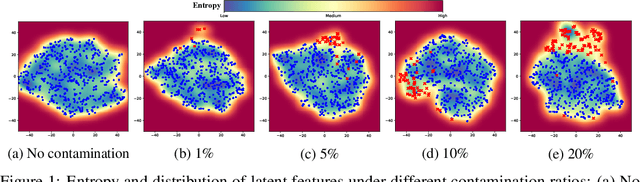
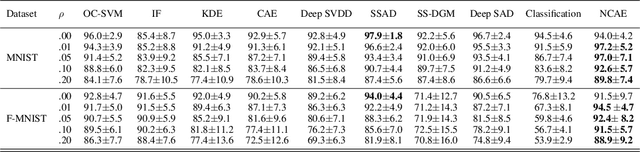
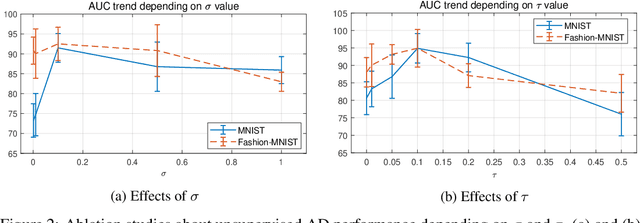
In this paper, we propose Normality-Calibrated Autoencoder (NCAE), which can boost anomaly detection performance on the contaminated datasets without any prior information or explicit abnormal samples in the training phase. The NCAE adversarially generates high confident normal samples from a latent space having low entropy and leverages them to predict abnormal samples in a training dataset. NCAE is trained to minimise reconstruction errors in uncontaminated samples and maximise reconstruction errors in contaminated samples. The experimental results demonstrate that our method outperforms shallow, hybrid, and deep methods for unsupervised anomaly detection and achieves comparable performance compared with semi-supervised methods using labelled anomaly samples in the training phase. The source code is publicly available on `https://github.com/andreYoo/NCAE_UAD.git'.
Camera-Tracklet-Aware Contrastive Learning for Unsupervised Vehicle Re-Identification
Sep 14, 2021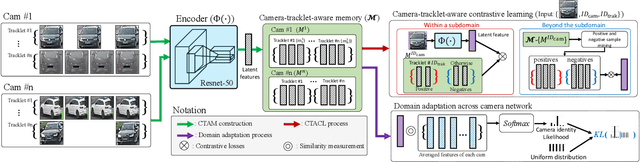
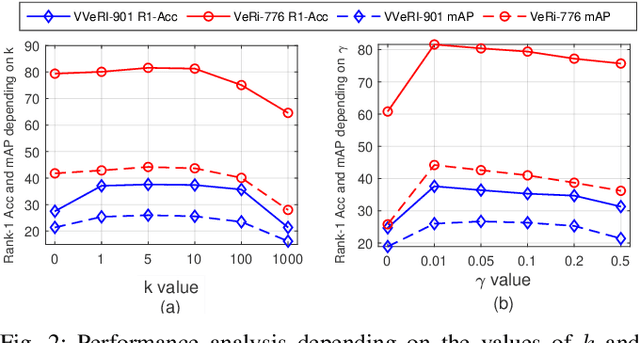
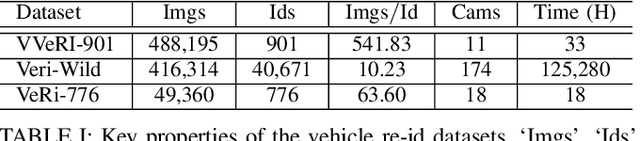
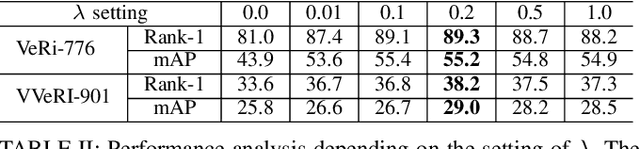
Recently, vehicle re-identification methods based on deep learning constitute remarkable achievement. However, this achievement requires large-scale and well-annotated datasets. In constructing the dataset, assigning globally available identities (Ids) to vehicles captured from a great number of cameras is labour-intensive, because it needs to consider their subtle appearance differences or viewpoint variations. In this paper, we propose camera-tracklet-aware contrastive learning (CTACL) using the multi-camera tracklet information without vehicle identity labels. The proposed CTACL divides an unlabelled domain, i.e., entire vehicle images, into multiple camera-level subdomains and conducts contrastive learning within and beyond the subdomains. The positive and negative samples for contrastive learning are defined using tracklet Ids of each camera. Additionally, the domain adaptation across camera networks is introduced to improve the generalisation performance of learnt representations and alleviate the performance degradation resulted from the domain gap between the subdomains. We demonstrate the effectiveness of our approach on video-based and image-based vehicle Re-ID datasets. Experimental results show that the proposed method outperforms the recent state-of-the-art unsupervised vehicle Re-ID methods. The source code for this paper is publicly available on `https://github.com/andreYoo/CTAM-CTACL-VVReID.git'.
Unsupervised Person Re-identification via Multi-Label Prediction and Classification based on Graph-Structural Insight
Jun 16, 2021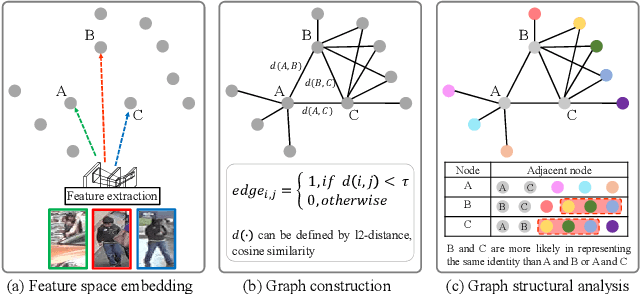

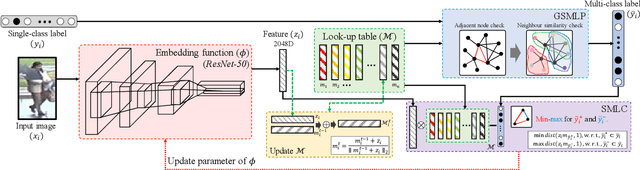
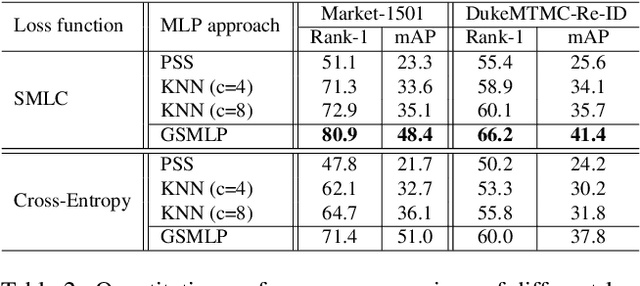
This paper addresses unsupervised person re-identification (Re-ID) using multi-label prediction and classification based on graph-structural insight. Our method extracts features from person images and produces a graph that consists of the features and a pairwise similarity of them as nodes and edges, respectively. Based on the graph, the proposed graph structure based multi-label prediction (GSMLP) method predicts multi-labels by considering the pairwise similarity and the adjacency node distribution of each node. The multi-labels created by GSMLP are applied to the proposed selective multi-label classification (SMLC) loss. SMLC integrates a hard-sample mining scheme and a multi-label classification. The proposed GSMLP and SMLC boost the performance of unsupervised person Re-ID without any pre-labelled dataset. Experimental results justify the superiority of the proposed method in unsupervised person Re-ID by producing state-of-the-art performance. The source code for this paper is publicly available on 'https://github.com/uknownpioneer/GSMLP-SMLC.git'.
Unsupervised Vehicle Re-Identification via Self-supervised Metric Learning using Feature Dictionary
Mar 03, 2021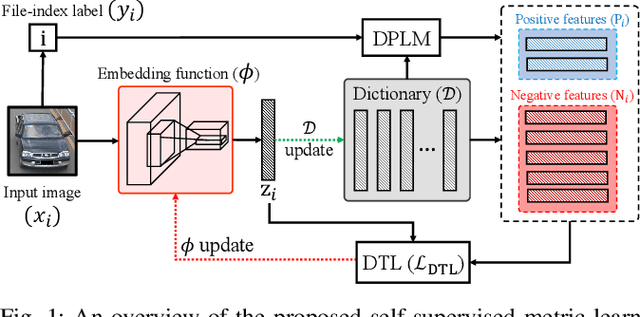
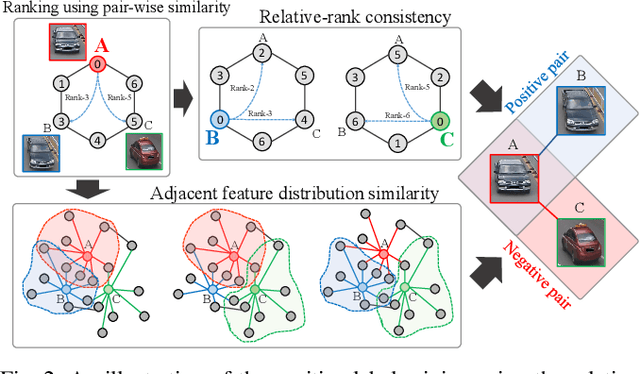
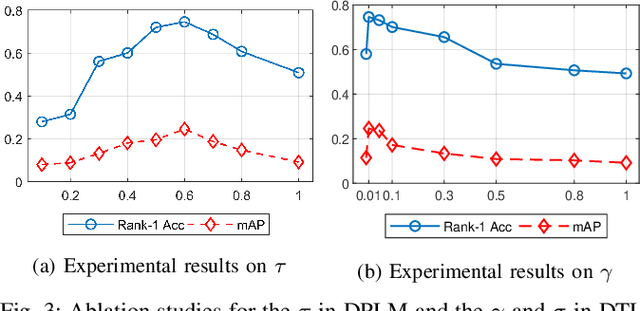
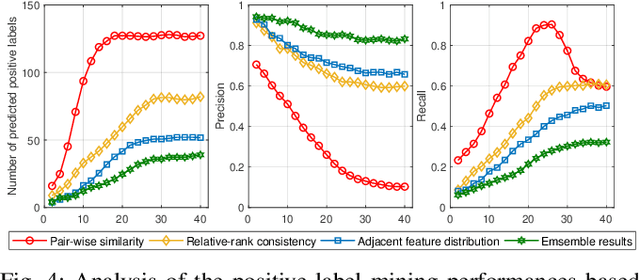
The key challenge of unsupervised vehicle re-identification (Re-ID) is learning discriminative features from unlabelled vehicle images. Numerous methods using domain adaptation have achieved outstanding performance, but those methods still need a labelled dataset as a source domain. This paper addresses an unsupervised vehicle Re-ID method, which no need any types of a labelled dataset, through a Self-supervised Metric Learning (SSML) based on a feature dictionary. Our method initially extracts features from vehicle images and stores them in a dictionary. Thereafter, based on the dictionary, the proposed method conducts dictionary-based positive label mining (DPLM) to search for positive labels. Pair-wise similarity, relative-rank consistency, and adjacent feature distribution similarity are jointly considered to find images that may belong to the same vehicle of a given probe image. The results of DPLM are applied to dictionary-based triplet loss (DTL) to improve the discriminativeness of learnt features and to refine the quality of the results of DPLM progressively. The iterative process with DPLM and DTL boosts the performance of unsupervised vehicle Re-ID. Experimental results demonstrate the effectiveness of the proposed method by producing promising vehicle Re-ID performance without a pre-labelled dataset. The source code for this paper is publicly available on `https://github.com/andreYoo/VeRI_SSML_FD.git'.