 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Multi-Task Learning for Traffic Scene Recognition in Autonomous Vehicles
Paper and Code
Apr 03, 2020
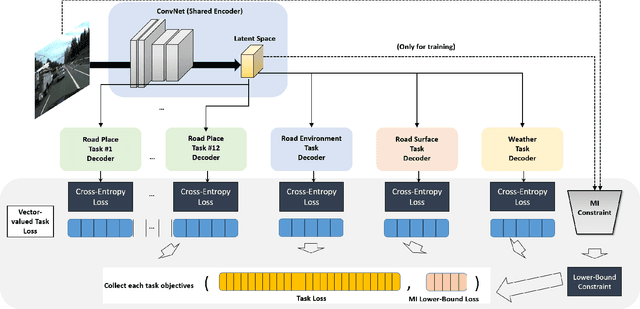

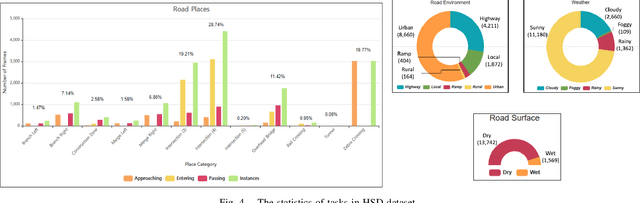
Traffic scene recognition, which requires various visual classification tasks, is a critical ingredient in autonomous vehicles. However, most existing approaches treat each relevant task independently from one another, never considering the entire system as a whole. Because of this, they are limited to utilizing a task-specific set of features for all possible tasks of inference-time, which ignores the capability to leverage common task-invariant contextual knowledge for the task at hand. To address this problem, we propose an algorithm to jointly learn the task-specific and shared representations by adopting a multi-task learning network. Specifically, we present a lower bound for the mutual information constraint between shared feature embedding and input that is considered to be able to extract common contextual information across tasks while preserving essential information of each task jointly. The learned representations capture richer contextual information without additional task-specific network. Extensive experiments on the large-scale dataset HSD demonstrate the effectiveness and superiority of our network over state-of-the-art methods.