 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Road Marking Recognition with Generative Adversarial Networks
Oct 10, 2019
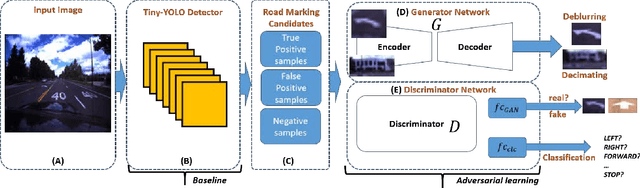
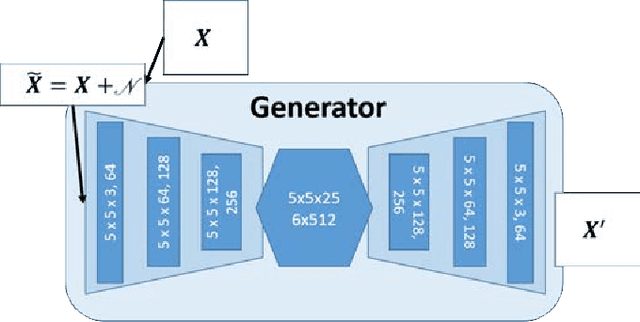
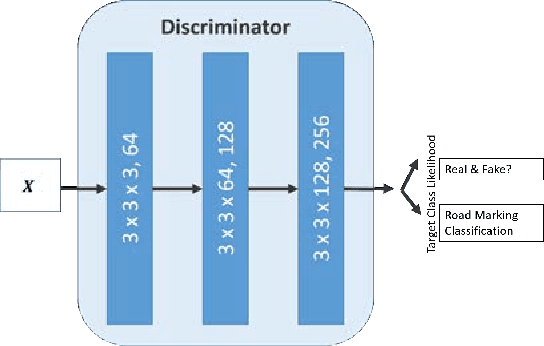
Recent road marking recognition has achieved great success in the past few years along with the rapid development of deep learning. Although considerable advances have been made, they are often over-dependent on unrepresentative datasets and constrained conditions. In this paper, to overcome these drawbacks, we propose an alternative method that achieves higher accuracy and generates high-quality samples as data augmentation. With the following two major contributions: 1) The proposed deblurring network can successfully recover a clean road marking from a blurred one by adopting generative adversarial networks (GAN). 2) The proposed data augmentation method, based on mutual information, can preserve and learn semantic context from the given dataset. We construct and train a class-conditional GAN to increase the size of training set, which makes it suitable to recognize target. The experimental results have shown that our proposed framework generates deblurred clean samples from blurry ones, and outperforms other methods even with unconstrained road marking datasets.
Practical License Plate Recognition in Unconstrained Surveillance Systems with Adversarial Super-Resolution
Oct 10, 2019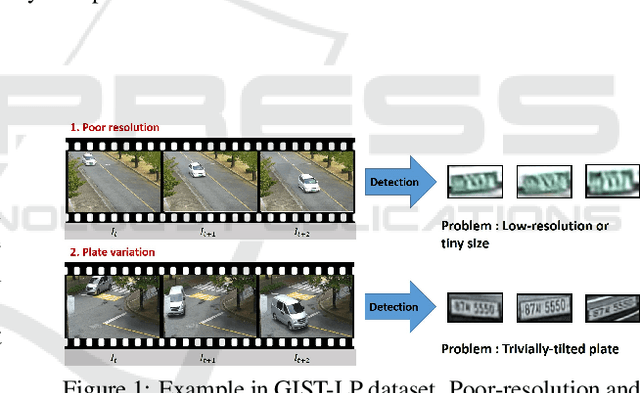
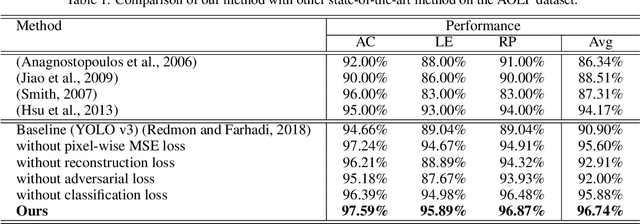
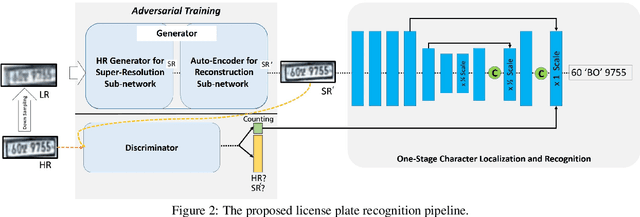
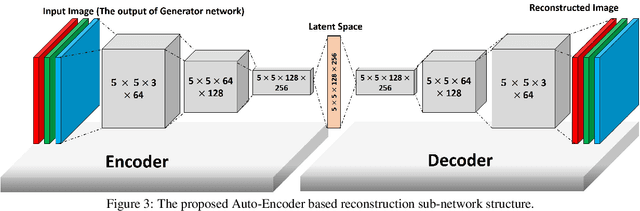
Although most current license plate (LP) recognition applications have been significantly advanced, they are still limited to ideal environments where training data are carefully annotated with constrained scenes. In this paper, we propose a novel license plate recognition method to handle unconstrained real world traffic scenes. To overcome these difficulties, we use adversarial super-resolution (SR), and one-stage character segmentation and recognition. Combined with a deep convolutional network based on VGG-net, our method provides simple but reasonable training procedure. Moreover, we introduce GIST-LP, a challenging LP dataset where image samples are effectively collected from unconstrained surveillance scenes. Experimental results on AOLP and GIST-LP dataset illustrate that our method, without any scene-specific adaptation, outperforms current LP recognition approaches in accuracy and provides visual enhancement in our SR results that are easier to understand than original data.