 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Points Estimation and Point Instance Segmentation Approach for Lane Detection
Feb 18, 2020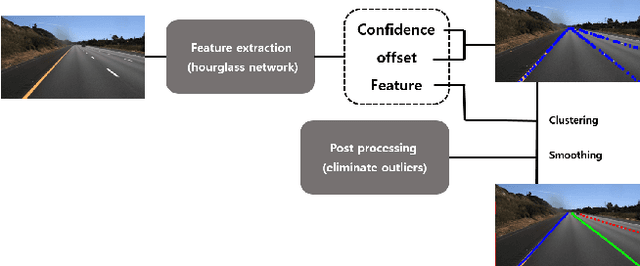
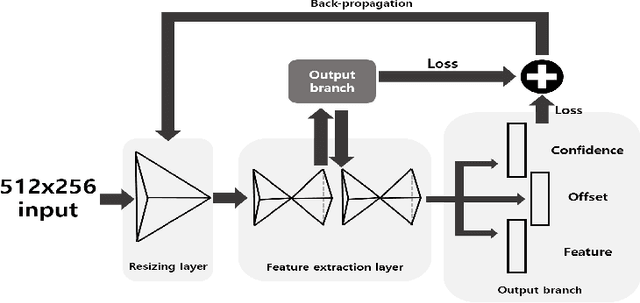
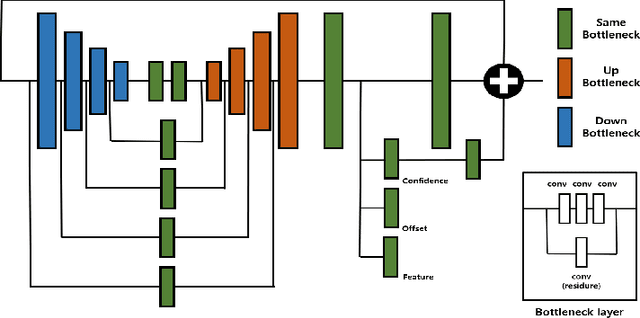

State-of-the-art lane detection methods achieve successful performance. Despite their advantages, these methods have critical deficiencies such as the limited number of detectable lanes and high false positive. In especial, high false positive can cause wrong and dangerous control. In this paper, we propose a novel lane detection method for the arbitrary number of lanes using the deep learning method, which has the lower number of false positives than other recent lane detection methods. The architecture of the proposed method has the shared feature extraction layers and several branches for detection and embedding to cluster lanes. The proposed method can generate exact points on the lanes, and we cast a clustering problem for the generated points as a point cloud instance segmentation problem. The proposed method is more compact because it generates fewer points than the original image pixel size. Our proposed post processing method eliminates outliers successfully and increases the performance notably. Whole proposed framework achieves competitive results on the tuSimple dataset.
Practical License Plate Recognition in Unconstrained Surveillance Systems with Adversarial Super-Resolution
Oct 10, 2019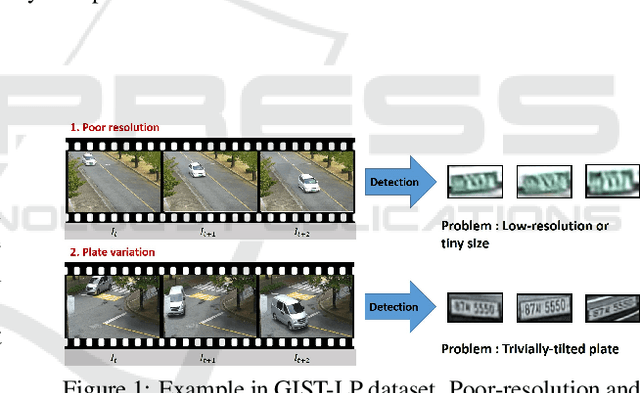
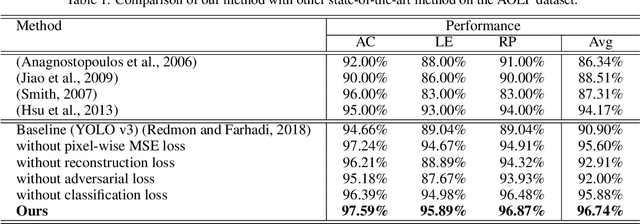
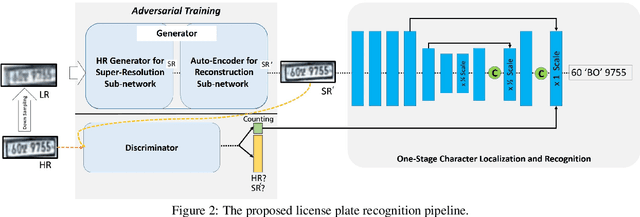
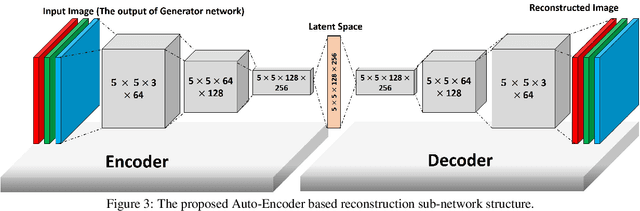
Although most current license plate (LP) recognition applications have been significantly advanced, they are still limited to ideal environments where training data are carefully annotated with constrained scenes. In this paper, we propose a novel license plate recognition method to handle unconstrained real world traffic scenes. To overcome these difficulties, we use adversarial super-resolution (SR), and one-stage character segmentation and recognition. Combined with a deep convolutional network based on VGG-net, our method provides simple but reasonable training procedure. Moreover, we introduce GIST-LP, a challenging LP dataset where image samples are effectively collected from unconstrained surveillance scenes. Experimental results on AOLP and GIST-LP dataset illustrate that our method, without any scene-specific adaptation, outperforms current LP recognition approaches in accuracy and provides visual enhancement in our SR results that are easier to understand than original data.