Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Memory Management for Deep Neural Net Inference
Paper and Code
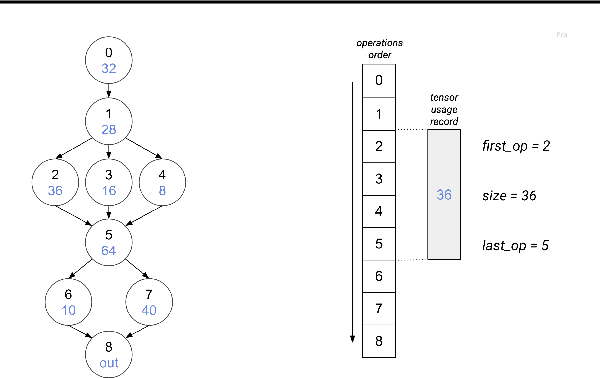
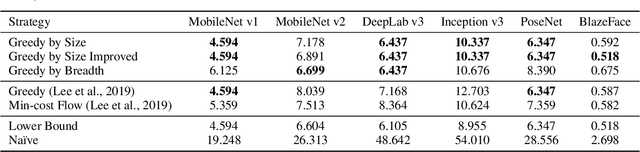
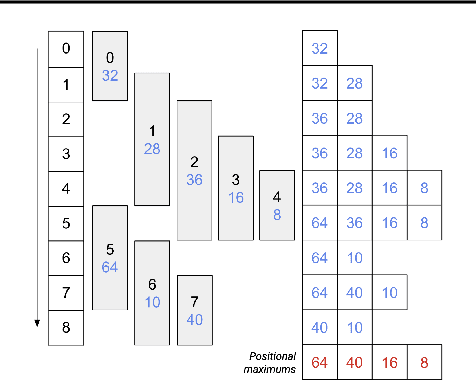
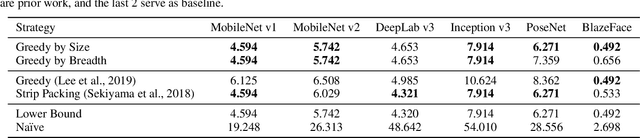
While deep neural net inference was considered a task for servers only, latest advances in technology allow the task of inference to be moved to mobile and embedded devices, desired for various reasons ranging from latency to privacy. These devices are not only limited by their compute power and battery, but also by their inferior physical memory and cache, and thus, an efficient memory manager becomes a crucial component for deep neural net inference at the edge. We explore various strategies to smartly share memory buffers among intermediate tensors in deep neural nets. Employing these can result in up to 11% smaller memory footprint than the state of the art.
* 6 pages, 6 figures, MLSys 2020 Workshop on Resource-Constrained
Machine Learning (ReCoML 2020)
View paper on