 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImposing Consistency for Optical Flow Estimation
Paper and Code
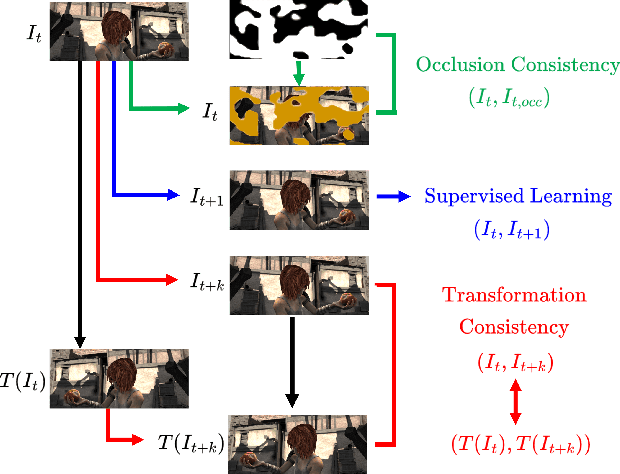
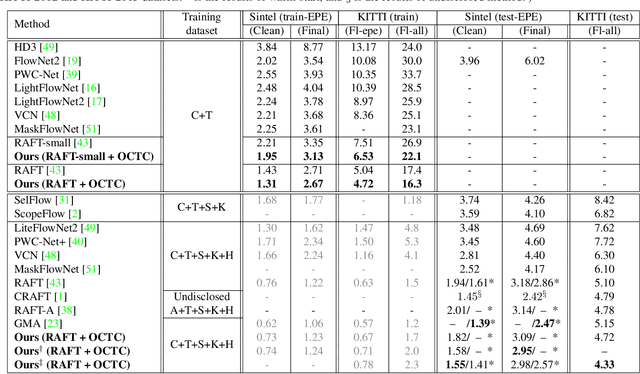

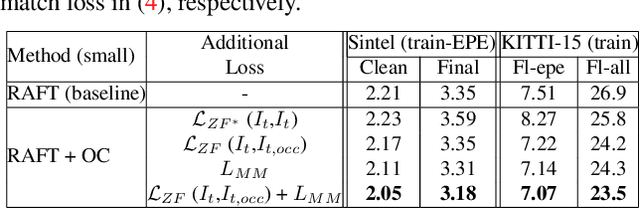
Imposing consistency through proxy tasks has been shown to enhance data-driven learning and enable self-supervision in various tasks. This paper introduces novel and effective consistency strategies for optical flow estimation, a problem where labels from real-world data are very challenging to derive. More specifically, we propose occlusion consistency and zero forcing in the forms of self-supervised learning and transformation consistency in the form of semi-supervised learning. We apply these consistency techniques in a way that the network model learns to describe pixel-level motions better while requiring no additional annotations. We demonstrate that our consistency strategies applied to a strong baseline network model using the original datasets and labels provide further improvements, attaining the state-of-the-art results on the KITTI-2015 scene flow benchmark in the non-stereo category. Our method achieves the best foreground accuracy (4.33% in Fl-all) over both the stereo and non-stereo categories, even though using only monocular image inputs.