 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic loss guided data efficient supervised fine tuning for Safe Responses in LLMs
Dec 07, 2024



Large Language Models (LLMs) generating unsafe responses to toxic prompts is a significant issue in their applications. While various efforts aim to address this safety concern, previous approaches often demand substantial human data collection or rely on the less dependable option of using another LLM to generate corrective data. In this paper, we aim to take this problem and overcome limitations of requiring significant high-quality human data. Our method requires only a small set of unsafe responses to toxic prompts, easily obtained from the unsafe LLM itself. By employing a semantic cost combined with a negative Earth Mover Distance (EMD) loss, we guide the LLM away from generating unsafe responses. Additionally, we propose a novel lower bound for EMD loss, enabling more efficient optimization. Our results demonstrate superior performance and data efficiency compared to baselines, and we further examine the nuanced effects of over-alignment and potential degradation of language capabilities when using contrastive data.
Conditioning Hierarchical Reinforcement Learning on Flexible Constraints
Feb 21, 2023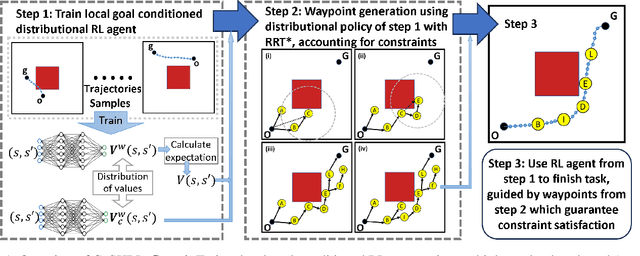
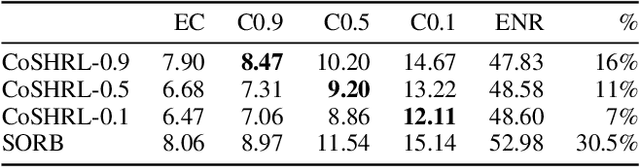
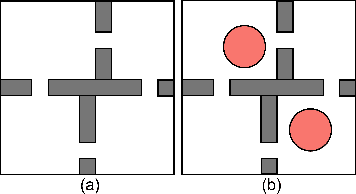
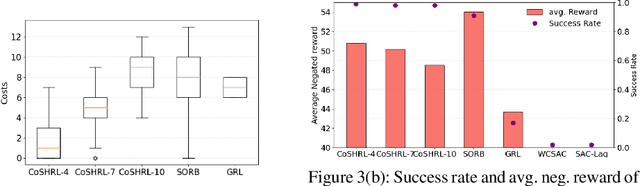
Safety in goal directed Reinforcement Learning (RL) settings has typically been handled through constraints over trajectories and have demonstrated good performance in primarily short horizon tasks (goal is not too far away). In this paper, we are specifically interested in the problem of solving temporally extended decision making problems such as (1) robots that have to clean different areas in a house while avoiding slippery and unsafe areas (e.g., stairs) and retaining enough charge to move to a charging dock; (2) autonomous electric vehicles that have to reach a far away destination while having to optimize charging locations along the way; in the presence of complex safety constraints. Our key contribution is a (safety) Constrained Planning with Reinforcement Learning (CoP-RL) mechanism that combines a high-level constrained planning agent (which computes a reward maximizing path from a given start to a far away goal state while satisfying cost constraints) with a low-level goal conditioned RL agent (which estimates cost and reward values to move between nearby states). A major advantage of CoP-RL is that it can handle constraints on the cost value distribution (e.g., on Conditional Value at Risk, CVaR, and also on expected value). We perform extensive experiments with different types of safety constraints to demonstrate the utility of our approach over leading best approaches in constrained and hierarchical RL.
FFConv: Fast Factorized Neural Network Inference on Encrypted Data
Feb 06, 2021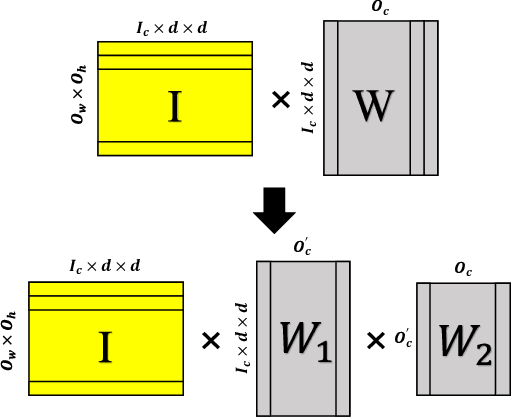
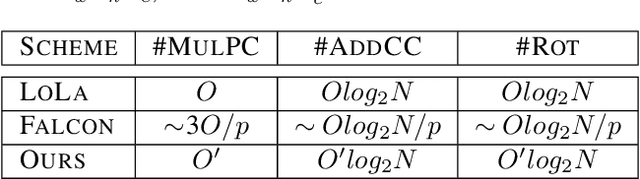
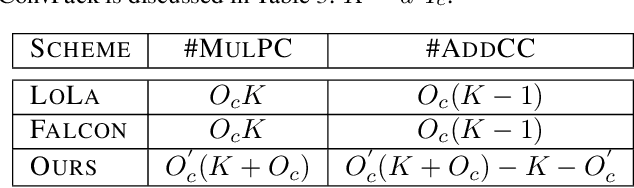
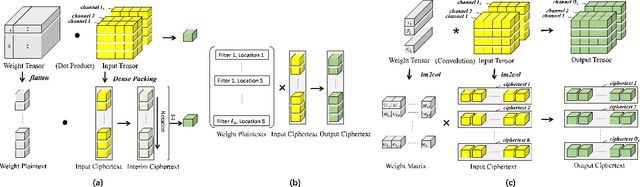
Homomorphic Encryption (HE), allowing computations on encrypted data (ciphertext) without decrypting it first, enables secure but prohibitively slow Neural Network (HENN) inference for privacy-preserving applications in clouds. To reduce HENN inference latency, one approach is to pack multiple messages into a single ciphertext in order to reduce the number of ciphertexts and support massive parallelism of Homomorphic Multiply-Add (HMA) operations between ciphertexts. However, different ciphertext packing schemes have to be designed for different convolution layers and each of them introduces overheads that are far more expensive than HMA operations. In this paper, we propose a low-rank factorization method called FFConv to unify convolution and ciphertext packing. To our knowledge, FFConv is the first work that is capable of accelerating the overheads induced by different ciphertext packing schemes simultaneously, without incurring a significant increase in noise budget. Compared to prior art LoLa and Falcon, our method reduces the inference latency by up to 87% and 12%, respectively, with comparable accuracy on MNIST and CIFAR-10.