 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated Data Processing Framework for Pretraining Foundation Models
Paper and Code
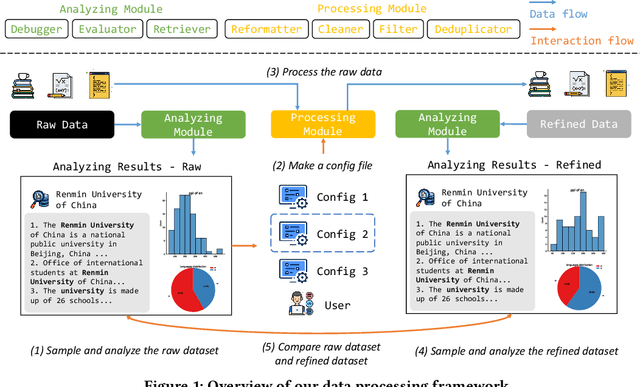



The ability of the foundation models heavily relies on large-scale, diverse, and high-quality pretraining data. In order to improve data quality, researchers and practitioners often have to manually curate datasets from difference sources and develop dedicated data cleansing pipeline for each data repository. Lacking a unified data processing framework, this process is repetitive and cumbersome. To mitigate this issue, we propose a data processing framework that integrates a Processing Module which consists of a series of operators at different granularity levels, and an Analyzing Module which supports probing and evaluation of the refined data. The proposed framework is easy to use and highly flexible. In this demo paper, we first introduce how to use this framework with some example use cases and then demonstrate its effectiveness in improving the data quality with an automated evaluation with ChatGPT and an end-to-end evaluation in pretraining the GPT-2 model. The code and demonstration videos are accessible on GitHub.