 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Stable Semi-Supervised Remote Sensing Segmentation via Co-Guidance and Co-Fusion
Dec 28, 2025Semi-supervised remote sensing (RS) image semantic segmentation offers a promising solution to alleviate the burden of exhaustive annotation, yet it fundamentally struggles with pseudo-label drift, a phenomenon where confirmation bias leads to the accumulation of errors during training. In this work, we propose Co2S, a stable semi-supervised RS segmentation framework that synergistically fuses priors from vision-language models and self-supervised models. Specifically, we construct a heterogeneous dual-student architecture comprising two distinct ViT-based vision foundation models initialized with pretrained CLIP and DINOv3 to mitigate error accumulation and pseudo-label drift. To effectively incorporate these distinct priors, an explicit-implicit semantic co-guidance mechanism is introduced that utilizes text embeddings and learnable queries to provide explicit and implicit class-level guidance, respectively, thereby jointly enhancing semantic consistency. Furthermore, a global-local feature collaborative fusion strategy is developed to effectively fuse the global contextual information captured by CLIP with the local details produced by DINOv3, enabling the model to generate highly precise segmentation results. Extensive experiments on six popular datasets demonstrate the superiority of the proposed method, which consistently achieves leading performance across various partition protocols and diverse scenarios. Project page is available at https://xavierjiezou.github.io/Co2S/.
Dynamic Dictionary Learning for Remote Sensing Image Segmentation
Mar 09, 2025Remote sensing image segmentation faces persistent challenges in distinguishing morphologically similar categories and adapting to diverse scene variations. While existing methods rely on implicit representation learning paradigms, they often fail to dynamically adjust semantic embeddings according to contextual cues, leading to suboptimal performance in fine-grained scenarios such as cloud thickness differentiation. This work introduces a dynamic dictionary learning framework that explicitly models class ID embeddings through iterative refinement. The core contribution lies in a novel dictionary construction mechanism, where class-aware semantic embeddings are progressively updated via multi-stage alternating cross-attention querying between image features and dictionary embeddings. This process enables adaptive representation learning tailored to input-specific characteristics, effectively resolving ambiguities in intra-class heterogeneity and inter-class homogeneity. To further enhance discriminability, a contrastive constraint is applied to the dictionary space, ensuring compact intra-class distributions while maximizing inter-class separability. Extensive experiments across both coarse- and fine-grained datasets demonstrate consistent improvements over state-of-the-art methods, particularly in two online test benchmarks (LoveDA and UAVid). Code is available at https://anonymous.4open.science/r/D2LS-8267/.
Knowledge Transfer and Domain Adaptation for Fine-Grained Remote Sensing Image Segmentation
Dec 09, 2024



Fine-grained remote sensing image segmentation is essential for accurately identifying detailed objects in remote sensing images. Recently, vision transformer models (VTM) pretrained on large-scale datasets have shown strong zero-shot generalization, indicating that they have learned the general knowledge of object understanding. We introduce a novel end-to-end learning paradigm combining knowledge guidance with domain refinement to enhance performance. We present two key components: the Feature Alignment Module (FAM) and the Feature Modulation Module (FMM). FAM aligns features from a CNN-based backbone with those from the pretrained VTM's encoder using channel transformation and spatial interpolation, and transfers knowledge via KL divergence and L2 normalization constraint. FMM further adapts the knowledge to the specific domain to address domain shift. We also introduce a fine-grained grass segmentation dataset and demonstrate, through experiments on two datasets, that our method achieves a significant improvement of 2.57 mIoU on the grass dataset and 3.73 mIoU on the cloud dataset. The results highlight the potential of combining knowledge transfer and domain adaptation to overcome domain-related challenges and data limitations. The project page is available at https://xavierjiezou.github.io/KTDA/.
Adapting Vision Foundation Models for Robust Cloud Segmentation in Remote Sensing Images
Nov 20, 2024



Cloud segmentation is a critical challenge in remote sensing image interpretation, as its accuracy directly impacts the effectiveness of subsequent data processing and analysis. Recently, vision foundation models (VFM) have demonstrated powerful generalization capabilities across various visual tasks. In this paper, we present a parameter-efficient adaptive approach, termed Cloud-Adapter, designed to enhance the accuracy and robustness of cloud segmentation. Our method leverages a VFM pretrained on general domain data, which remains frozen, eliminating the need for additional training. Cloud-Adapter incorporates a lightweight spatial perception module that initially utilizes a convolutional neural network (ConvNet) to extract dense spatial representations. These multi-scale features are then aggregated and serve as contextual inputs to an adapting module, which modulates the frozen transformer layers within the VFM. Experimental results demonstrate that the Cloud-Adapter approach, utilizing only 0.6% of the trainable parameters of the frozen backbone, achieves substantial performance gains. Cloud-Adapter consistently attains state-of-the-art (SOTA) performance across a wide variety of cloud segmentation datasets from multiple satellite sources, sensor series, data processing levels, land cover scenarios, and annotation granularities. We have released the source code and pretrained models at https://github.com/XavierJiezou/Cloud-Adapter to support further research.
UV-Mamba: A DCN-Enhanced State Space Model for Urban Village Boundary Identification in High-Resolution Remote Sensing Images
Sep 05, 2024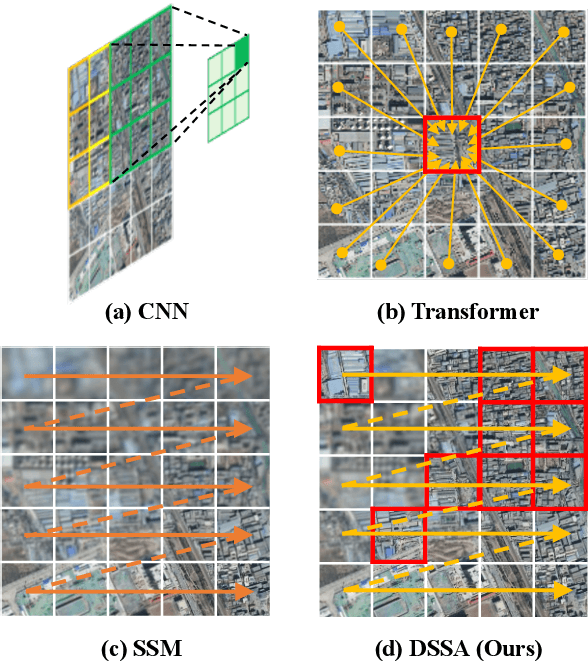
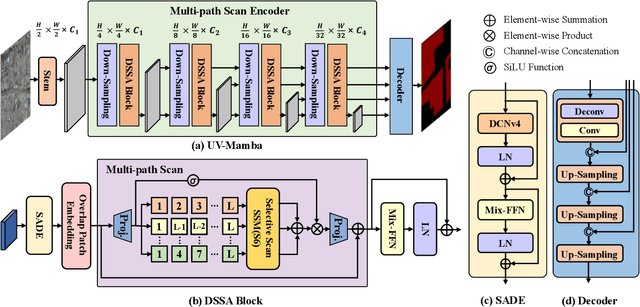
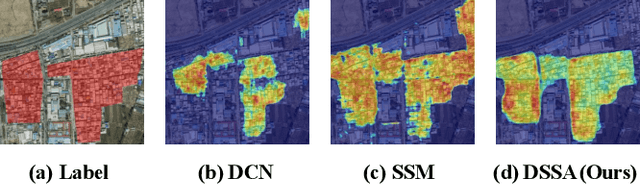

Owing to the diverse geographical environments, intricate landscapes, and high-density settlements, the automatic identification of urban village boundaries using remote sensing images is a highly challenging task. This paper proposes a novel and efficient neural network model called UV-Mamba for accurate boundary detection in high-resolution remote sensing images. UV-Mamba mitigates the memory loss problem in long sequence modeling, which arises in state space model (SSM) with increasing image size, by incorporating deformable convolutions (DCN). Its architecture utilizes an encoder-decoder framework, includes an encoder with four deformable state space augmentation (DSSA) blocks for efficient multi-level semantic extraction and a decoder to integrate the extracted semantic information. We conducted experiments on the Beijing and Xi'an datasets, and the results show that UV-Mamba achieves state-of-the-art performance. Specifically, our model achieves 73.3% and 78.1% IoU on the Beijing and Xi'an datasets, respectively, representing improvements of 1.2% and 3.4% IoU over the previous best model, while also being 6x faster in inference speed and 40x smaller in parameter count. Source code and pre-trained models are available in the supplementary material.
A Parallel Attention Network for Cattle Face Recognition
Mar 29, 2024



Cattle face recognition holds paramount significance in domains such as animal husbandry and behavioral research. Despite significant progress in confined environments, applying these accomplishments in wild settings remains challenging. Thus, we create the first large-scale cattle face recognition dataset, ICRWE, for wild environments. It encompasses 483 cattle and 9,816 high-resolution image samples. Each sample undergoes annotation for face features, light conditions, and face orientation. Furthermore, we introduce a novel parallel attention network, PANet. Comprising several cascaded Transformer modules, each module incorporates two parallel Position Attention Modules (PAM) and Feature Mapping Modules (FMM). PAM focuses on local and global features at each image position through parallel channel attention, and FMM captures intricate feature patterns through non-linear mappings. Experimental results indicate that PANet achieves a recognition accuracy of 88.03% on the ICRWE dataset, establishing itself as the current state-of-the-art approach. The source code is available in the supplementary materials.
PanBench: Towards High-Resolution and High-Performance Pansharpening
Nov 20, 2023Pansharpening, a pivotal task in remote sensing, involves integrating low-resolution multispectral images with high-resolution panchromatic images to synthesize an image that is both high-resolution and retains multispectral information. These pansharpened images enhance precision in land cover classification, change detection, and environmental monitoring within remote sensing data analysis. While deep learning techniques have shown significant success in pansharpening, existing methods often face limitations in their evaluation, focusing on restricted satellite data sources, single scene types, and low-resolution images. This paper addresses this gap by introducing PanBench, a high-resolution multi-scene dataset containing all mainstream satellites and comprising 5,898 pairs of samples. Each pair includes a four-channel (RGB + near-infrared) multispectral image of 256x256 pixels and a mono-channel panchromatic image of 1,024x1,024 pixels. To achieve high-fidelity synthesis, we propose a Cascaded Multiscale Fusion Network (CMFNet) for Pansharpening. Extensive experiments validate the effectiveness of CMFNet. We have released the dataset, source code, and pre-trained models in the supplementary, fostering further research in remote sensing.
High-Fidelity Lake Extraction via Two-Stage Prompt Enhancement: Establishing a Novel Baseline and Benchmark
Aug 16, 2023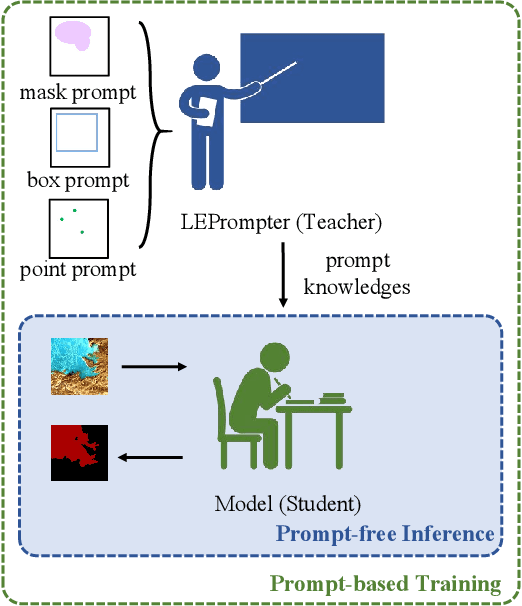
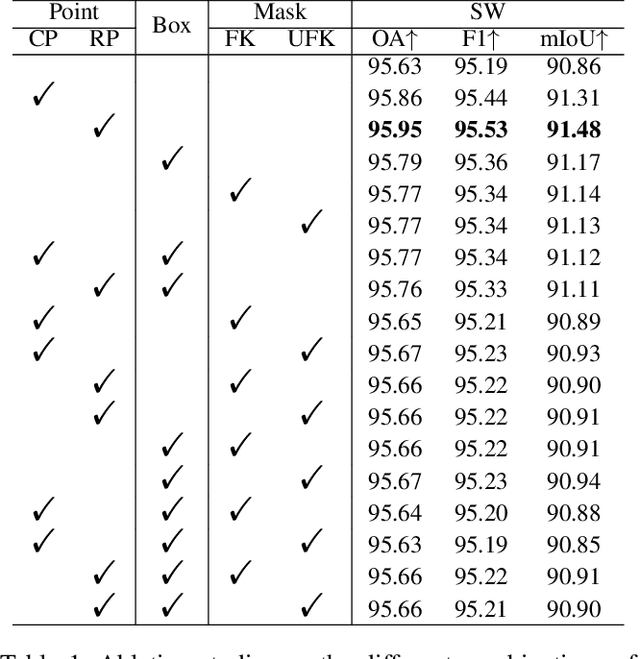
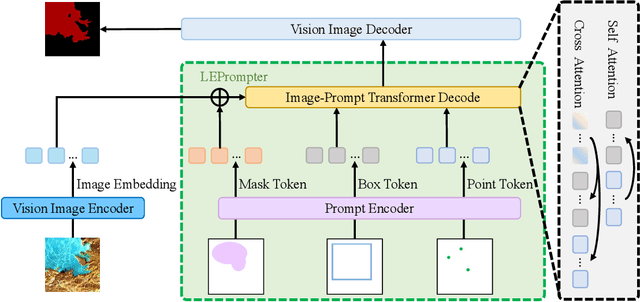
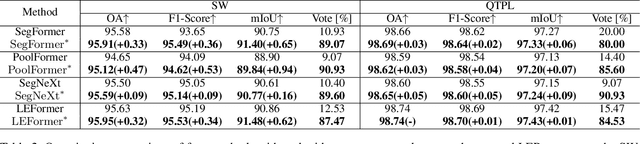
The extraction of lakes from remote sensing images is a complex challenge due to the varied lake shapes and data noise. Current methods rely on multispectral image datasets, making it challenging to learn lake features accurately from pixel arrangements. This, in turn, affects model learning and the creation of accurate segmentation masks. This paper introduces a unified prompt-based dataset construction approach that provides approximate lake locations using point, box, and mask prompts. We also propose a two-stage prompt enhancement framework, LEPrompter, which involves prompt-based and prompt-free stages during training. The prompt-based stage employs a prompt encoder to extract prior information, integrating prompt tokens and image embeddings through self- and cross-attention in the prompt decoder. Prompts are deactivated once the model is trained to ensure independence during inference, enabling automated lake extraction. Evaluations on Surface Water and Qinghai-Tibet Plateau Lake datasets show consistent performance improvements compared to the previous state-of-the-art method. LEPrompter achieves mIoU scores of 91.48% and 97.43% on the respective datasets without introducing additional parameters or GFLOPs. Supplementary materials provide the source code, pre-trained models, and detailed user studies.
LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery
Aug 08, 2023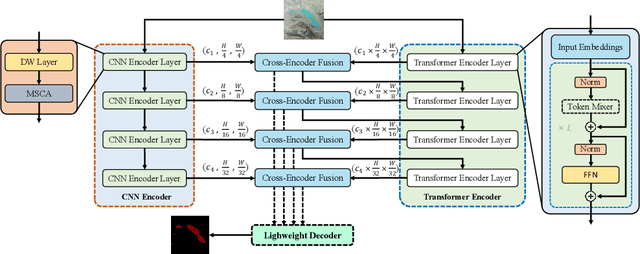

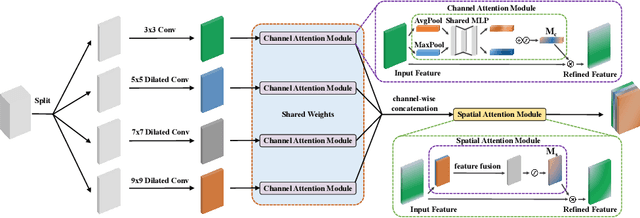
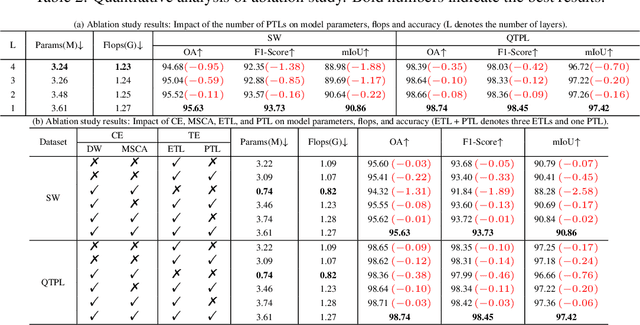
Lake extraction from remote sensing imagery is challenging due to the complex shapes of lakes and the presence of noise. Existing methods suffer from blurred segmentation boundaries and poor foreground modeling. In this paper, we propose a hybrid CNN-Transformer architecture, called LEFormer, for accurate lake extraction. LEFormer contains four main modules: CNN encoder, Transformer encoder, cross-encoder fusion, and lightweight decoder. The CNN encoder recovers local spatial information and improves fine-scale details. Simultaneously, the Transformer encoder captures long-range dependencies between sequences of any length, allowing them to obtain global features and context information better. Finally, a lightweight decoder is employed for mask prediction. We evaluate the performance and efficiency of LEFormer on two datasets, the Surface Water (SW) and the Qinghai-Tibet Plateau Lake (QTPL). Experimental results show that LEFormer consistently achieves state-of-the-art (SOTA) performance and efficiency on these two datasets, outperforming existing methods. Specifically, LEFormer achieves 90.86% and 97.42% mIoU on the SW and QTPL datasets with a parameter count of 3.61M, respectively, while being 20x minor than the previous SOTA method.
DiffCR: A Fast Conditional Diffusion Framework for Cloud Removal from Optical Satellite Images
Aug 08, 2023Optical satellite images are a critical data source; however, cloud cover often compromises their quality, hindering image applications and analysis. Consequently, effectively removing clouds from optical satellite images has emerged as a prominent research direction. While recent advancements in cloud removal primarily rely on generative adversarial networks, which may yield suboptimal image quality, diffusion models have demonstrated remarkable success in diverse image-generation tasks, showcasing their potential in addressing this challenge. This paper presents a novel framework called DiffCR, which leverages conditional guided diffusion with deep convolutional networks for high-performance cloud removal for optical satellite imagery. Specifically, we introduce a decoupled encoder for conditional image feature extraction, providing a robust color representation to ensure the close similarity of appearance information between the conditional input and the synthesized output. Moreover, we propose a novel and efficient time and condition fusion block within the cloud removal model to accurately simulate the correspondence between the appearance in the conditional image and the target image at a low computational cost. Extensive experimental evaluations on two commonly used benchmark datasets demonstrate that DiffCR consistently achieves state-of-the-art performance on all metrics, with parameter and computational complexities amounting to only 5.1% and 5.4%, respectively, of those previous best methods. The source code, pre-trained models, and all the experimental results will be publicly available at https://github.com/XavierJiezou/DiffCR upon the paper's acceptance of this work.