 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflexDiffusion: Reflection-Enhanced Trajectory Planning for High-lateral-acceleration Scenarios in Autonomous Driving
Jan 14, 2026Generating safe and reliable trajectories for autonomous vehicles in long-tail scenarios remains a significant challenge, particularly for high-lateral-acceleration maneuvers such as sharp turns, which represent critical safety situations. Existing trajectory planners exhibit systematic failures in these scenarios due to data imbalance. This results in insufficient modelling of vehicle dynamics, road geometry, and environmental constraints in high-risk situations, leading to suboptimal or unsafe trajectory prediction when vehicles operate near their physical limits. In this paper, we introduce ReflexDiffusion, a novel inference-stage framework that enhances diffusion-based trajectory planners through reflective adjustment. Our method introduces a gradient-based adjustment mechanism during the iterative denoising process: after each standard trajectory update, we compute the gradient between the conditional and unconditional noise predictions to explicitly amplify critical conditioning signals, including road curvature and lateral vehicle dynamics. This amplification enforces strict adherence to physical constraints, particularly improving stability during high-lateral-acceleration maneuvers where precise vehicle-road interaction is paramount. Evaluated on the nuPlan Test14-hard benchmark, ReflexDiffusion achieves a 14.1% improvement in driving score for high-lateral-acceleration scenarios over the state-of-the-art (SOTA) methods. This demonstrates that inference-time trajectory optimization can effectively compensate for training data sparsity by dynamically reinforcing safety-critical constraints near handling limits. The framework's architecture-agnostic design enables direct deployment to existing diffusion-based planners, offering a practical solution for improving autonomous vehicle safety in challenging driving conditions.
Disentangled Representation via Variational AutoEncoder for Continuous Treatment Effect Estimation
Jun 04, 2024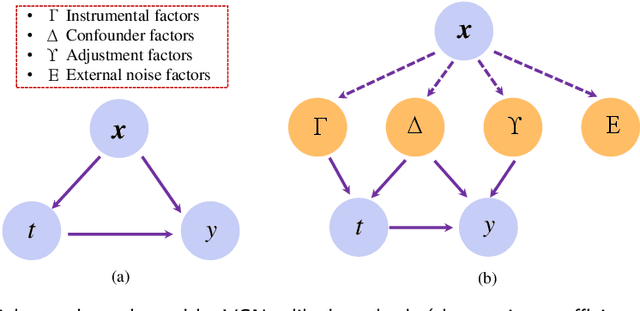



Continuous treatment effect estimation holds significant practical importance across various decision-making and assessment domains, such as healthcare and the military. However, current methods for estimating dose-response curves hinge on balancing the entire representation by treating all covariates as confounding variables. Although various approaches disentangle covariates into different factors for treatment effect estimation, they are confined to binary treatment settings. Moreover, observational data are often tainted with non-causal noise information that is imperceptible to the human. Hence, in this paper, we propose a novel Dose-Response curve estimator via Variational AutoEncoder (DRVAE) disentangled covariates representation. Our model is dedicated to disentangling covariates into instrumental factors, confounding factors, adjustment factors, and external noise factors, thereby facilitating the estimation of treatment effects under continuous treatment settings by balancing the disentangled confounding factors. Extensive results on synthetic and semi-synthetic datasets demonstrate that our model outperforms the current state-of-the-art methods.
Multi-Forgery Detection Challenge 2022: Push the Frontier of Unconstrained and Diverse Forgery Detection
Jul 27, 2022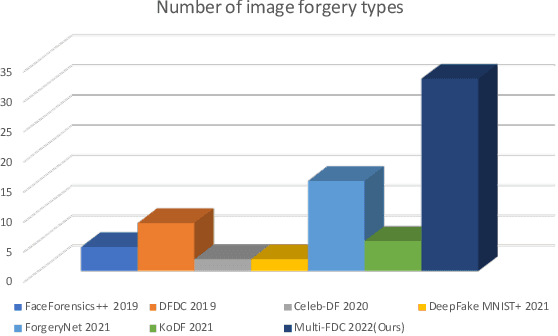

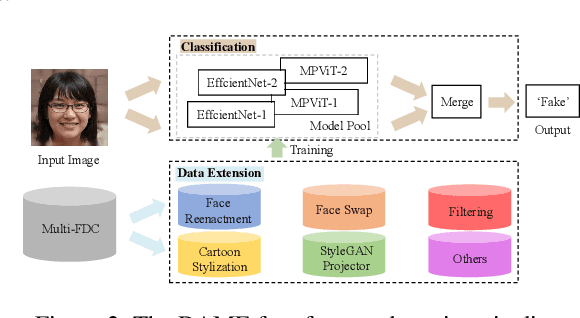

In this paper, we present the Multi-Forgery Detection Challenge held concurrently with the IEEE Computer Society Workshop on Biometrics at CVPR 2022. Our Multi-Forgery Detection Challenge aims to detect automatic image manipulations including but not limited to image editing, image synthesis, image generation, image photoshop, etc. Our challenge has attracted 674 teams from all over the world, with about 2000 valid result submission counts. We invited the Top 10 teams to present their solutions to the challenge, from which three teams are awarded prizes in the grand finale. In this paper, we present the solutions from the Top 3 teams, in order to boost the research work in the field of image forgery detection.
LookinGood^π: Real-time Person-independent Neural Re-rendering for High-quality Human Performance Capture
Dec 15, 2021

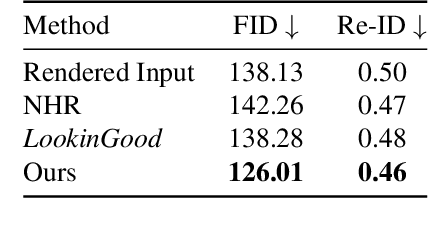

We propose LookinGood^{\pi}, a novel neural re-rendering approach that is aimed to (1) improve the rendering quality of the low-quality reconstructed results from human performance capture system in real-time; (2) improve the generalization ability of the neural rendering network on unseen people. Our key idea is to utilize the rendered image of reconstructed geometry as the guidance to assist the prediction of person-specific details from few reference images, thus enhancing the re-rendered result. In light of this, we design a two-branch network. A coarse branch is designed to fix some artifacts (i.e. holes, noise) and obtain a coarse version of the rendered input, while a detail branch is designed to predict "correct" details from the warped references. The guidance of the rendered image is realized by blending features from two branches effectively in the training of the detail branch, which improves both the warping accuracy and the details' fidelity. We demonstrate that our method outperforms state-of-the-art methods at producing high-fidelity images on unseen people.