 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer with Attention Map Hallucination and FFN Compaction
Jun 19, 2023Vision Transformer(ViT) is now dominating many vision tasks. The drawback of quadratic complexity of its token-wise multi-head self-attention (MHSA), is extensively addressed via either token sparsification or dimension reduction (in spatial or channel). However, the therein redundancy of MHSA is usually overlooked and so is the feed-forward network (FFN). To this end, we propose attention map hallucination and FFN compaction to fill in the blank. Specifically, we observe similar attention maps exist in vanilla ViT and propose to hallucinate half of the attention maps from the rest with much cheaper operations, which is called hallucinated-MHSA (hMHSA). As for FFN, we factorize its hidden-to-output projection matrix and leverage the re-parameterization technique to strengthen its capability, making it compact-FFN (cFFN). With our proposed modules, a 10$\%$-20$\%$ reduction of floating point operations (FLOPs) and parameters (Params) is achieved for various ViT-based backbones, including straight (DeiT), hybrid (NextViT) and hierarchical (PVT) structures, meanwhile, the performances are quite competitive.
Multi-Label Classification with Label Graph Superimposing
Nov 21, 2019
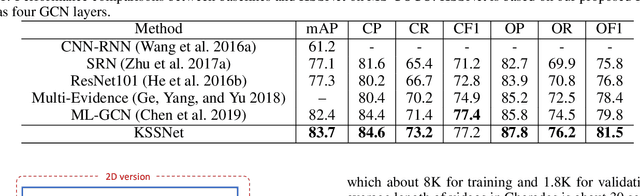
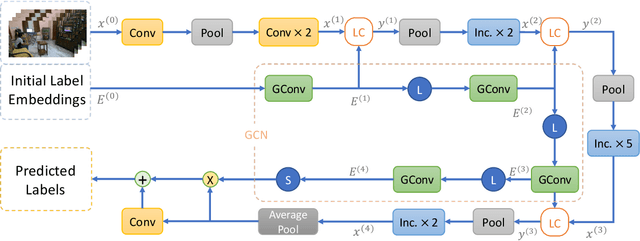

Images or videos always contain multiple objects or actions. Multi-label recognition has been witnessed to achieve pretty performance attribute to the rapid development of deep learning technologies. Recently, graph convolution network (GCN) is leveraged to boost the performance of multi-label recognition. However, what is the best way for label correlation modeling and how feature learning can be improved with label system awareness are still unclear. In this paper, we propose a label graph superimposing framework to improve the conventional GCN+CNN framework developed for multi-label recognition in the following two aspects. Firstly, we model the label correlations by superimposing label graph built from statistical co-occurrence information into the graph constructed from knowledge priors of labels, and then multi-layer graph convolutions are applied on the final superimposed graph for label embedding abstraction. Secondly, we propose to leverage embedding of the whole label system for better representation learning. In detail, lateral connections between GCN and CNN are added at shallow, middle and deep layers to inject information of label system into backbone CNN for label-awareness in the feature learning process. Extensive experiments are carried out on MS-COCO and Charades datasets, showing that our proposed solution can greatly improve the recognition performance and achieves new state-of-the-art recognition performance.
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
Nov 06, 2018
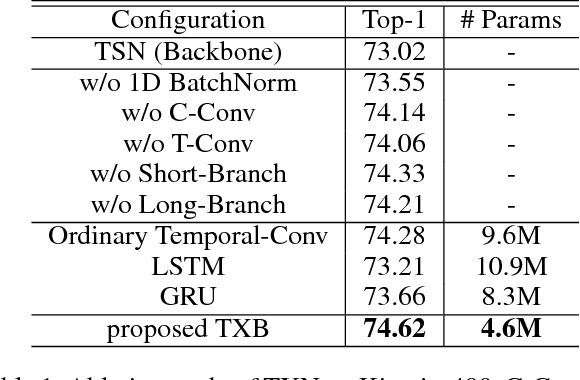
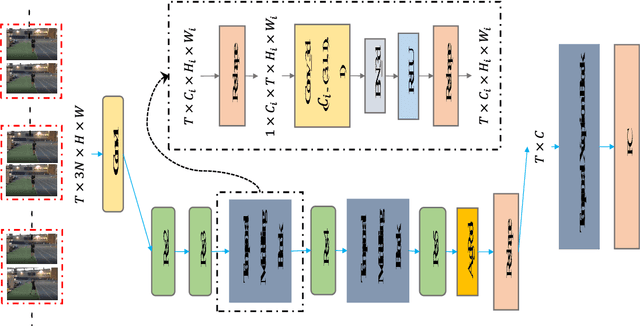
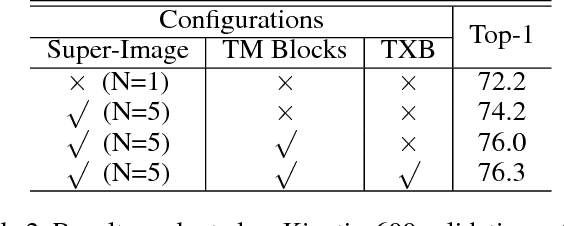
Despite the success of deep learning for static image understanding, it remains unclear what are the most effective network architectures for the spatial-temporal modeling in videos. In this paper, in contrast to the existing CNN+RNN or pure 3D convolution based approaches, we explore a novel spatial temporal network (StNet) architecture for both local and global spatial-temporal modeling in videos. Particularly, StNet stacks N successive video frames into a \emph{super-image} which has 3N channels and applies 2D convolution on super-images to capture local spatial-temporal relationship. To model global spatial-temporal relationship, we apply temporal convolution on the local spatial-temporal feature maps. Specifically, a novel temporal Xception block is proposed in StNet. It employs a separate channel-wise and temporal-wise convolution over the feature sequence of video. Extensive experiments on the Kinetics dataset demonstrate that our framework outperforms several state-of-the-art approaches in action recognition and can strike a satisfying trade-off between recognition accuracy and model complexity. We further demonstrate the generalization performance of the leaned video representations on the UCF101 dataset.
Triplet-Center Loss for Multi-View 3D Object Retrieval
Mar 16, 2018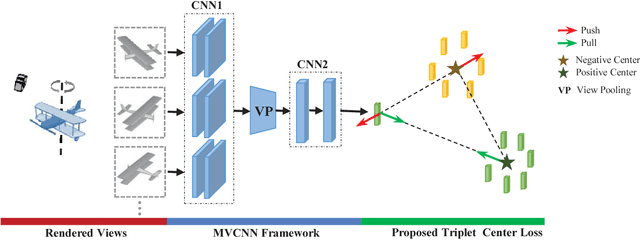
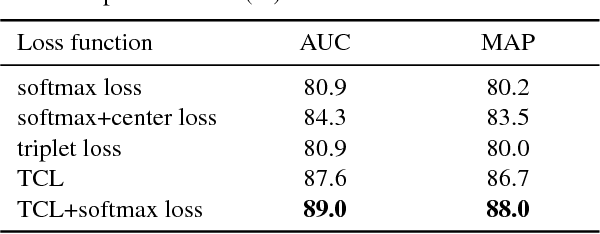
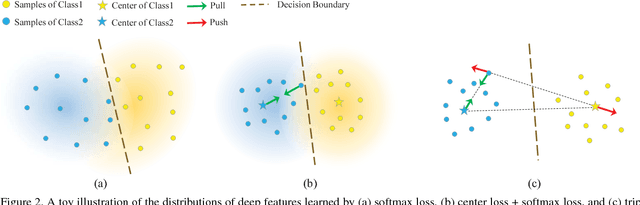
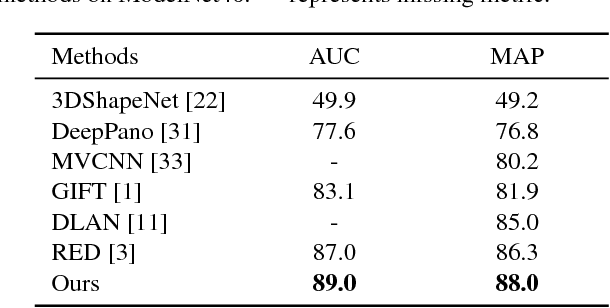
Most existing 3D object recognition algorithms focus on leveraging the strong discriminative power of deep learning models with softmax loss for the classification of 3D data, while learning discriminative features with deep metric learning for 3D object retrieval is more or less neglected. In the paper, we study variants of deep metric learning losses for 3D object retrieval, which did not receive enough attention from this area. First , two kinds of representative losses, triplet loss and center loss, are introduced which could learn more discriminative features than traditional classification loss. Then, we propose a novel loss named triplet-center loss, which can further enhance the discriminative power of the features. The proposed triplet-center loss learns a center for each class and requires that the distances between samples and centers from the same class are closer than those from different classes. Extensive experimental results on two popular 3D object retrieval benchmarks and two widely-adopted sketch-based 3D shape retrieval benchmarks consistently demonstrate the effectiveness of our proposed loss, and significant improvements have been achieved compared with the state-of-the-arts.
Divide and Fuse: A Re-ranking Approach for Person Re-identification
Aug 11, 2017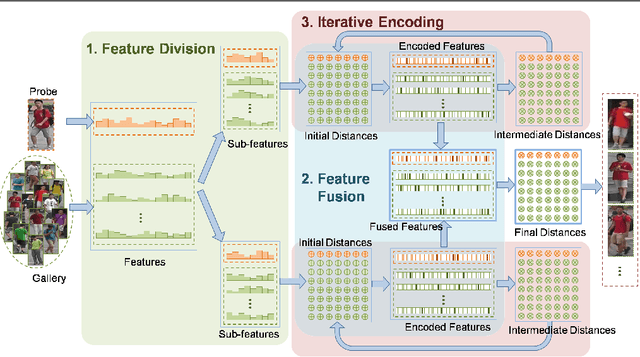
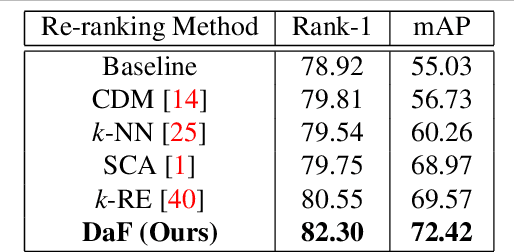
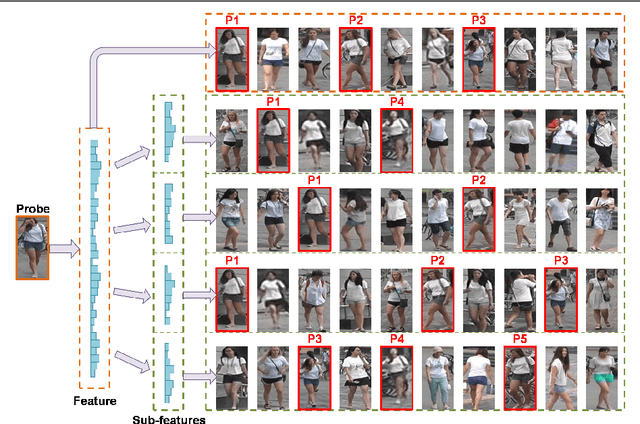
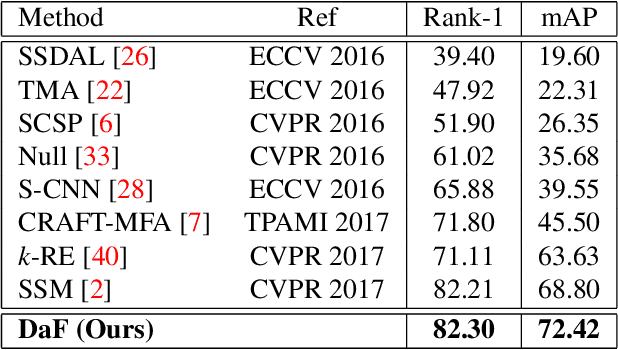
As re-ranking is a necessary procedure to boost person re-identification (re-ID) performance on large-scale datasets, the diversity of feature becomes crucial to person reID for its importance both on designing pedestrian descriptions and re-ranking based on feature fusion. However, in many circumstances, only one type of pedestrian feature is available. In this paper, we propose a "Divide and use" re-ranking framework for person re-ID. It exploits the diversity from different parts of a high-dimensional feature vector for fusion-based re-ranking, while no other features are accessible. Specifically, given an image, the extracted feature is divided into sub-features. Then the contextual information of each sub-feature is iteratively encoded into a new feature. Finally, the new features from the same image are fused into one vector for re-ranking. Experimental results on two person re-ID benchmarks demonstrate the effectiveness of the proposed framework. Especially, our method outperforms the state-of-the-art on the Market-1501 dataset.
GIFT: A Real-time and Scalable 3D Shape Search Engine
Mar 31, 2017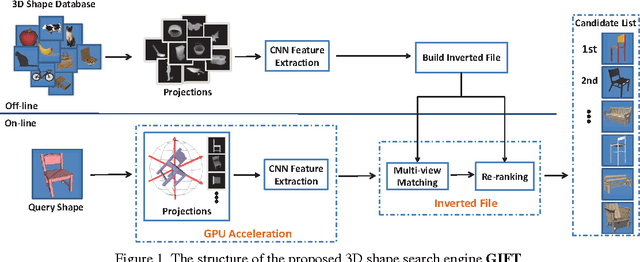
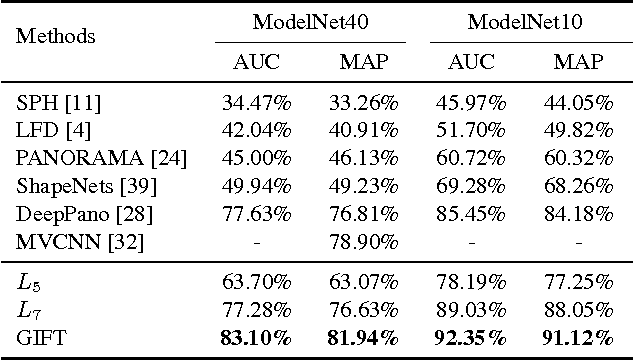
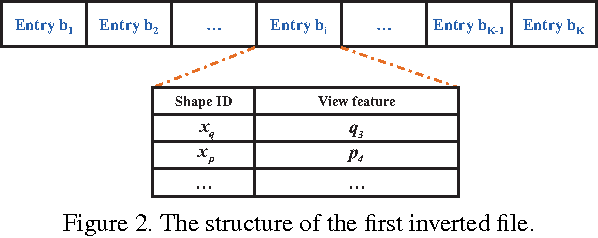
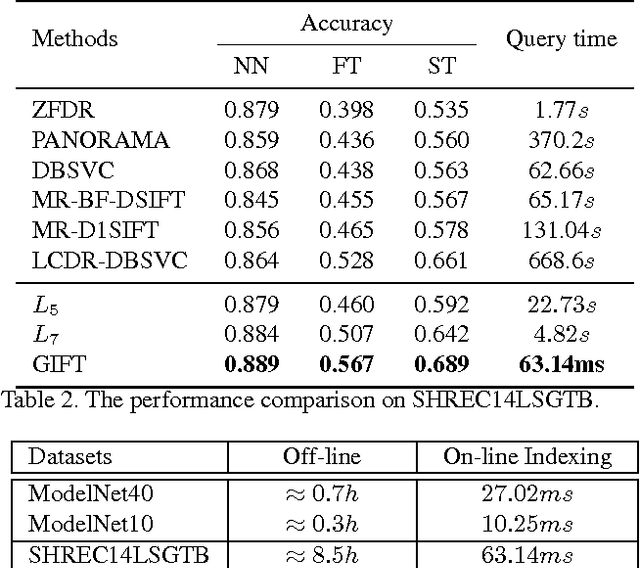
Projective analysis is an important solution for 3D shape retrieval, since human visual perceptions of 3D shapes rely on various 2D observations from different view points. Although multiple informative and discriminative views are utilized, most projection-based retrieval systems suffer from heavy computational cost, thus cannot satisfy the basic requirement of scalability for search engines. In this paper, we present a real-time 3D shape search engine based on the projective images of 3D shapes. The real-time property of our search engine results from the following aspects: (1) efficient projection and view feature extraction using GPU acceleration; (2) the first inverted file, referred as F-IF, is utilized to speed up the procedure of multi-view matching; (3) the second inverted file (S-IF), which captures a local distribution of 3D shapes in the feature manifold, is adopted for efficient context-based re-ranking. As a result, for each query the retrieval task can be finished within one second despite the necessary cost of IO overhead. We name the proposed 3D shape search engine, which combines GPU acceleration and Inverted File Twice, as GIFT. Besides its high efficiency, GIFT also outperforms the state-of-the-art methods significantly in retrieval accuracy on various shape benchmarks and competitions.